从单体应用到分布式应用的可观测性

Logging
日志记录本质上是一个事件。大多数语言、应用程序框架或库都支持日志,表现形式可以是字符串这样原始的非结构化数据,也可以是JSON等半结构化数据。开发者可以通过日志来分析应用的执行状况,报错信息,分析性能…… 正因为日志极其灵活,生成非常容易,没有一个统一的结构,所以它的体量也是最大的。
对于单体应用,查看日志我们可以直接登上服务器,用head、tail、less、more等命令进行查看,也可以结合awk、sed、grep等文本处理工具进行简单的分析。但是分布式应用,面对部署在数十数百台机器的应用,亟需一个日志收集、处理、存储、查询的系统。
开源社区最早流行的是Elastic体系的ELK。Logstash负责收集,ElasticSearch负责索引与存储,Kibana负责查询与展示。ElasticSearch支持全文索引可以进行全文搜索,而且支持DocValue可以用于结构化数据的聚合分析。再加上MetricBeats提供了监控指标的收集,APM提供的链路收集,Elastic俨然已是一个集Logging、Metrics、Trace的大一统技术体系。这主要是因为早期的
Elastic野心很大,但是这也导致ElasticSearch并不专注在其中的一个领域。
1、使用全文索引受限于分词器,对于日志查询非常鸡肋(两个单词能搜索到,三个单词就搜索不到的现象也不少)。
2、而且索引阶段特别耗时,很多用户都无法忍受ElasticSearch索引不过来时抛出的EsReject。
3、另外,ElasticSearch除了用于全文搜索的倒排索引,还有store按行存储,在_source字段中存储JSON文档,docValue列式存储,对于不熟悉ElasticSearch的开发者来说,意味着存储体量翻了好几倍,ElasticSearch的高性能查询严重依赖于索引缓存,官方建议机器的内存得预留一半给操作系统进行文件缓存,这套吃内存的东西对普通的日志查询简直就是小题大做。
4、还有ElasticSearch在生产环境至少得部署三个节点,否则由于网络波动容易出现脑裂。
5、基于JVM的Logstash极其笨重,经常因为GC无响应导致日志延时,作为采集日志的agent有点喧宾夺主,为此Elastic专门用Go语言开发了轻量级的FileBeat日志采集工具。由FileBeat负责采集,Logstash负责解析处理。
目前K8s生态下以Fluentd和C语言编写的fluent-bit为主作为日志收集工具,Grafana开发的Loki负责存储。Loki去掉了全文索引,使用最原始的块存储,对时间和特定标签做索引,这和Metrics领域的Prometheus类似。

Metrics
单体应用中应用的性能可以通过Linux自带的各种工具进行观测。
比如最常用的top命令可以看到每个进程的CPU、内存等使用情况,mpstat、vmstat、iostat可以看到系统的CPU、内存、磁盘读写等情况。

对于不同语言编写的应用也有针对应用内部的监控工具,如Java体系有jmap、jconsole、Eclipse Memory Analyzer等工具,JDK也提供了JMX对应用指标接口进行标准化。
在分布式系统中,由于应用部署在多台机器上,应用性能的观测面临着巨大的挑战。
指标数据和日志数据的区别在于它更加结构化,而且这些metrics的结构化数据与传统的OLTP数据库中的数据,区别在于:
- 数据不可变,只有插入,没有修改
- 按时间依次生成,顺序追加
- 数据量远比传统的OLTP数据库大
- 主要以时间戳和单独的主键(serverId、deviceId、accountId……)做索引
- 数据通常需要聚合。需要看同一秒内应用所有机器的整体性能,就需要把这些机器的数据聚合起来
这类数据也被称为时序数据,时序数据库的发展就是专门用来解决这类数据的存储问题。
正因为时序数据是按照时间依次生成顺序追加的,所以除了早期的VividCortex(基于MySQL)和TimeScaleDB(基于PostgreSQL)使用就地更新的B+树来存储,其他大多数时序数据库都是用LSM-Tree(Log-Structured Merge Tree)作为底层的索引结构(在InfluxDB中被叫做Time-Structured Merge Tree)。
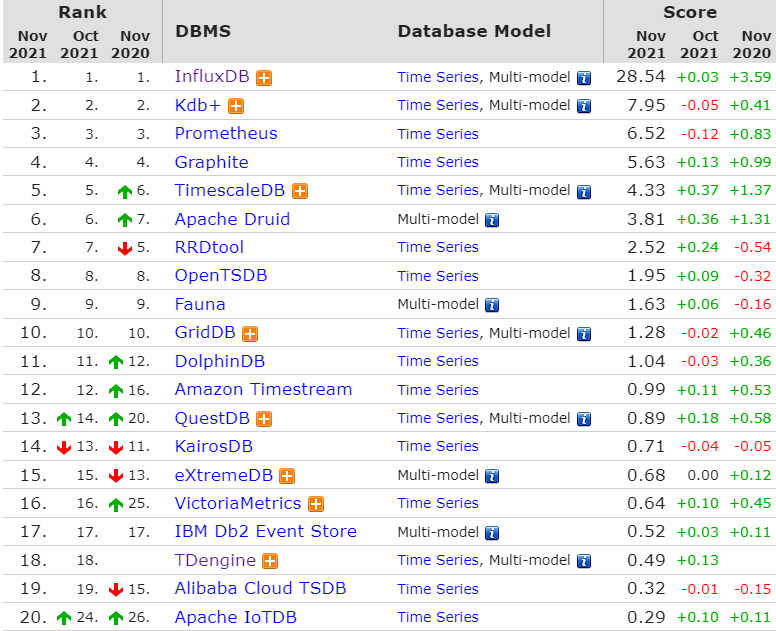
时序数据并不局限于系统与应用的性能指标,还包括了各种业务指标,如互联网应用的流量分析、接口性能、消息发送量……物联网传感器的功率、风速、温度等各种信号……金融领域的股票交易数据……
目前prometheus+grafana的组合几乎成了分布式系统指标观测的事实标准。

Trace
单体应用的调用只局限于内存的堆栈,可以通过stack trace进行调用链追踪,调用的性能分析可以通过这些堆栈生成相应的火炬图进行可视化。github上也有大多数语言应用生成火炬图的工具,使用火炬图能方便地分析各个函数的调用深度和调用消耗。
但是分布式应用,不再是内存内的堆栈调用了,而是穿透网络的RPC调用。用户一个请求过来,从A服务到B服务再到C服务……这个调用链可能很长。再也不能像单机版应用一样直接看程序堆栈,直接用火炬图就能分析应用的性能了。而且一个应用部署了多台机器,具体调用了集群中哪台机器也是不知道的。
这就催生了调用链收集的工具,将分布式应用的调用链整成一个跟程序堆栈类似的东西,最好还能告诉我每个服务调用过程中的耗时,这就是Distributed Tracing。
最早谷歌的Dapper论文就介绍了谷歌是怎么实现这个功能的。然后开源社区便产出了Zipkin、Jaeger等优秀工具,Spring Cloud也有一个Sleuth,这种组件很多,每种实现可能有所差别。
在谷歌论文里服务之间的调用被称为Span,整个链路被叫做Trace,但是在一些实现里服务间的调用被称为Rpc或者其他的名字,为了规范链路追踪的技术,有了OpenTracing标准和OpenCensus标准。
但是,OpenTracing和OpenCensus的出发点不一样。由社区发起的OpenTracing专注于链路追踪相关概念的统一,与具体实现无关,是一套链路追踪的规范。由谷歌主导的OpenCensus包括了Metrics和Trace两者数据收集的规范与对应的实现,后面微软的加入也更能证明这个项目的实力。
随着K8s催生的云原生的发展,OpenTracing和OpenCensus合并到了OpenTelemetry,并且将Traces, Metrics, Logs进行了统一。目前OpenTelemetry是云原生基金会的孵化项目,是K8s生态分布式观测系统的未来。

分布式观测系统的架构
Logging、Metrics、Tracing三者架构上基本是一致统一的,但是这里面可选的组件可谓是百花齐放。
比如FileBeat和MetricBeat可以负责Logging和Metrics的日志采集,由Logstash处理后存入ElasticSearch;ElasticAPM Agent可以负责Tracing的数据采集,由APM Server处理后存入ElasticSearch;Kibana中提供了Logging、Metrics、Tracing的可视化;Elastic官方提供了kibana-alerting用于告警,开源社区也有一个ElastAlert插件可以提供告警功能。
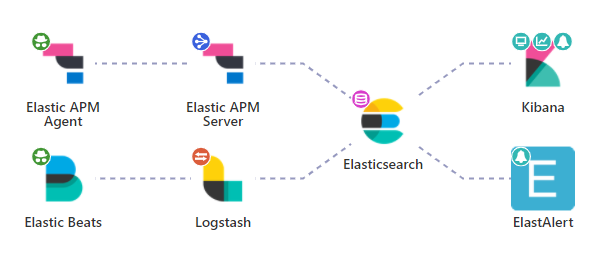
1、Library:应用内生成数据。Logging领域的库不胜枚举,Metrics和Tracing领域也有很多。
2、 Collector Agent:负责在服务器节点上采集数据,有一些能做简单的数据处理,如从日志中拆解字段,过滤清洗日志等。
3、Transport:负责中间转储,防止日志丢失,为日志处理流程提供相对高的可靠性。
4、Storage:负责数据的存储,可以根据数据的不同schema(非结构化的大文本日志类,半结构化的JSON文档类型,结构化的)选用适合的存储。
5、Visualization & Dashboarding:负责将数据可视化展示,生成相应的仪表盘
6、Alerting:负责对异常进行告警
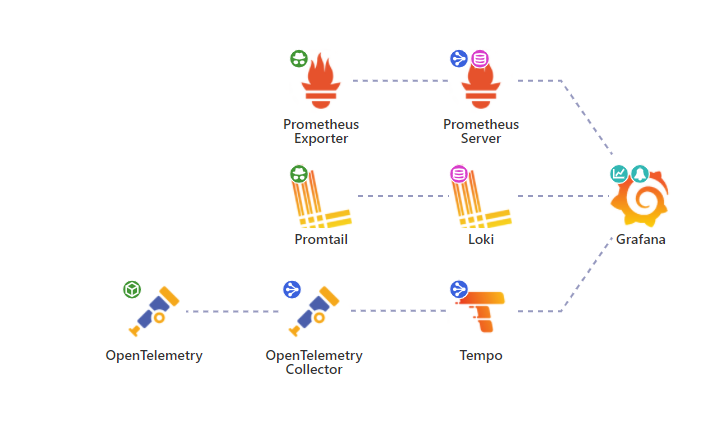
基于Grafana的一站式分布式观测系统
最早Grafana是为了弥补Kibana没有Metrics指标统计功能的一个分支,2014年首次发布,目标是为Prometheus、InfluxDB、OpenTSDB等时序数据库提供可视化界面,后面逐渐支持传统关系型数据库。
Kibana和Grafana走向了两个不同的发展道路。Kibana作为ElasticSearch的可视化工具,最早只支持日志查询,之后围绕着ElasticSearch存储功能的不断升级改进,才有了后面的Metrics和Tracing的功能。Grafana最早没有自己的存储功能,它通过接入各种数据库(也支持ElasticSearch),来实现Metrics功能。
在2019年~2021年获得三轮融资后,依次有了Loki、Tempo专门支持Logging、Tracing的开源产品。
OpenTelemetry
OpenTelemetry是由两个项目合并而成:由开源社区主导的OpenTracing,由谷歌主导微软支持的OpenCensus。OpenTracing只是制定了Tracing相关的标准,OpenCensus提供了Tracing和Metrics采集与收集的相关实现。两者合并后目标是将Logging、Tracing、Metrics三者的采集与收集进行统一,并指定一个数据编码与传输规范——OpenTelemetry Protocol Specification。
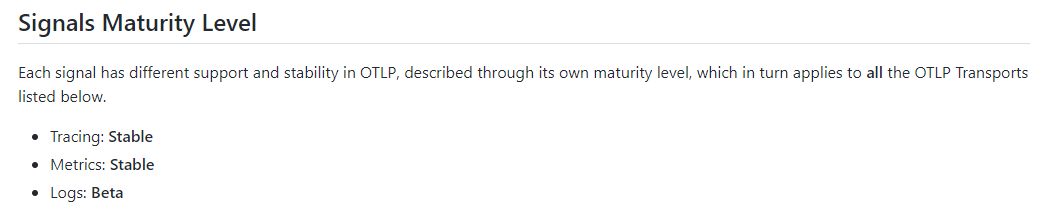
截至当前(2021年11月),OTLP规范的Tracing和Metrics已经稳定,Logging目前还在Beta版本。
opentelemetry-cpp-contrib还提供了nginx的支持(C/C++语言实现的)。
Loki
日志数据的写是由Loki中的Distributor和Ingester两个组件处理,整体的流程如下图红线部分,读取过程由蓝线部分表示。
除此之外,Loki还提供了一个独立的应用loki-canary用于监控日志抓取性能。

使用grafana即可通过LogQL查询日志
Tempo
参考链接:
^ 1. 分布式系统观测性的三大基石:https://www.oreilly.com/library/view/distributed-systems-observability/9781492033431/ch04.html
^ 2. 云原生生态远景图:https://landscape.cncf.io/
^ 3. 面向列的数据库:http://www.timestored.com/time-series-data/what-is-a-column-oriented-database
^ 4. OpenMetrics: https://openmetrics.io/
^ 5. OpenTracing: https://opentracing.io/
^ 6. OpenCensus: https://opencensus.io/
^ 7. OpenTelemetry: https://opentelemetry.io/
^ 8. OpenAPM: https://openapm.io/landscape
^ 9. Loki Architecture: https://grafana.com/docs/loki/latest/architecture/

