流程化营销是我个人觉得在达西做的最复杂的一个功能,把我大学里学的很多知识都应用到了这个功能的实现上,我也是靠着这个功能毕业才一年就在公司里晋升到了P5,所以在这里记录一下
流程化营销:店铺根据需要在前端绘制一张执行流程图,校验连通性与数据合法性后交由后端服务执行。
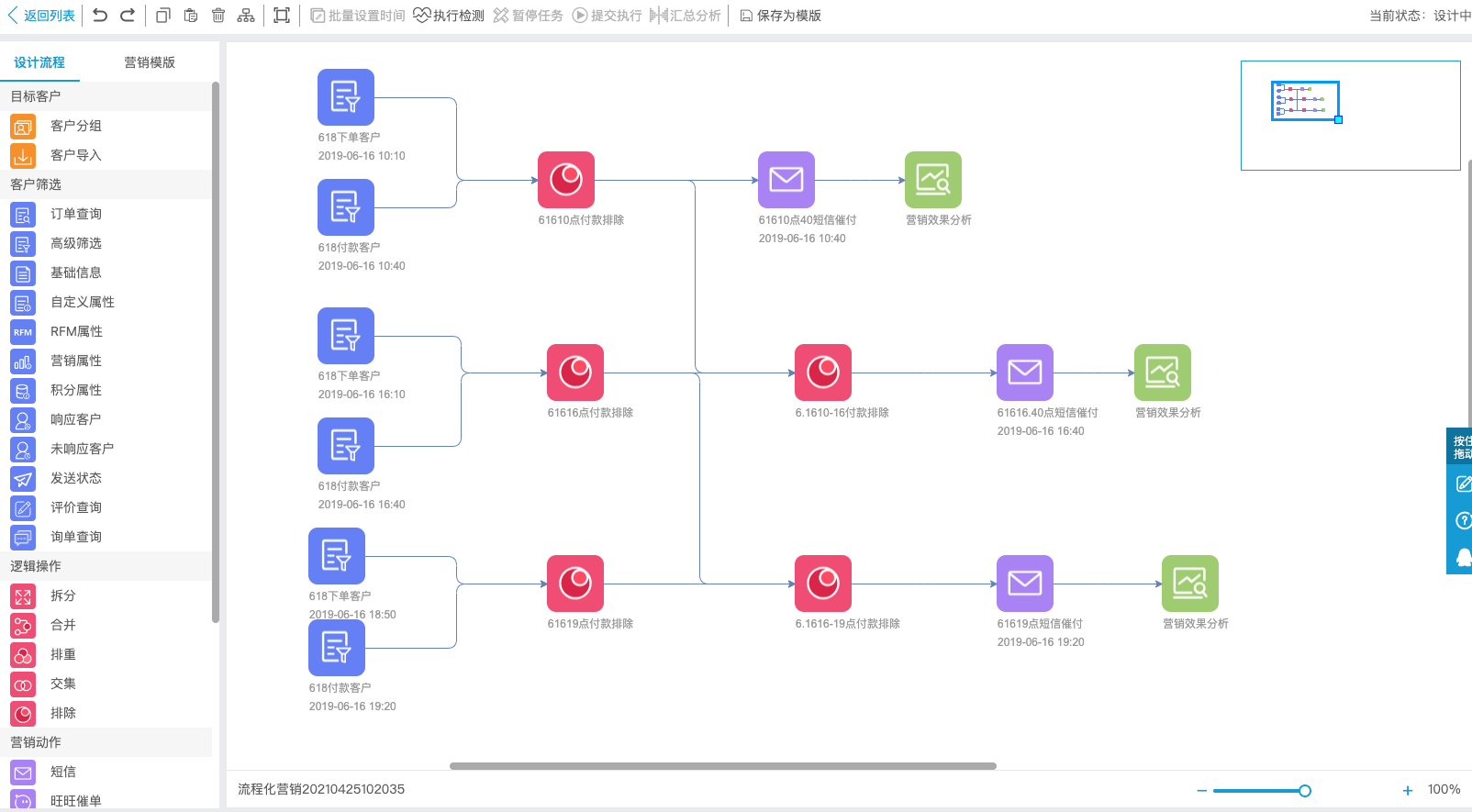
节点类型
数据源节点

数据源节点中有动态数据节点和静态数据节点:
- 静态数据是用户通过txt,excel等文件手动导入的,静态节点没有执行时间的
- 动态数据节点是筛选条件,根据筛选条件对店铺的会员进行筛选。因为会员的属性是会变化的,比如会员的最后下单时间、总付款金额等数据会因为用户每次下单支付而变化,所以通过这些条件筛选出来的用户肯定是动态的。动态节点用户可以指定执行时间
逻辑节点

可以对数据节点进行逻辑操作,还可以对逻辑操作的结果再进行逻辑操作。
动作节点

动作节点都有执行时间,用户在这个节点里配置短信内容,选择发放的优惠券,或者赠送积分的数量。
分析节点

对短信、优惠券等节点的营销效果进行分析。
用户绘制完流程图后,提交到后端调度,后段通过深度优先遍历并根据节点时间配置判断是否继续执行下去。
遇到的问题和难点
节点数据很多:考虑到每个节点客户数量可能较多,很多店铺客户数据量上千万,比如比较有名的网红店“李子柒旗舰店”用户量有1800w,2020年一年的订单两就有2100w。节点的数据支持交、并、差等逻辑, 直接把节点数据拿到内存运算肯定会导致内存溢出的。
解决方案:因为昵称在淘宝店铺里是唯一的,每个节点执行后的数据根据昵称计算 hash 分成64个文件放到一个文件夹中,后续的交并差等运算以小文件读取到内存的形式进行。比如要对A、B两个节点做交集运算,只需要拿A节点的1号文件和B节点的2号文件进行交集。
数据校验问题:在用户提交任务的时候,我们会校验图的连通性和数据合法性的时候。
大致的连接规则是:
数据源节点必须是起始节点
逻辑节点前面必须有数据
动作节点前必须有数据
分析节点前必须有动作
所以在用户提交任务的时候就需要执行一次深度优先遍历。
另外,数据的合法性,比如在流程图里,后面节点的执行时间肯定要大于前面节点的执行时间的。而有些节点是没有执行时间的。
所以,为了简化逻辑,我们会在校验过程中对没有时间的节点进行填充,规则是取所有前驱节点中时间的最大值。一方面简化了校验逻辑,另一方面也对任务的调度逻辑进行了统一(调度的时候会检查节点的时间有没有到)。
节点回溯问题:
A、B、C三个节点,A节点和B节点做交集的数据会存在C节点。使用深度优先遍历,由A遍历到C的时候,C的前驱节点B还没有遍历过。这个时候就需要回溯。
回溯问题分两种场景:
校验场景:填充时间的时候,前面节点的时间可能都没有,肯定需要回溯。比如说A遍历到C,C节点没有时间要拿前面最大的时间填充,前面B节点也没有时间,那就需要再往前找B节点前面的最大时间。
因为数据是填充的,所以整个图的所有节点也就只需要遍历一遍。
执行场景:A后面接的C节点进行交集运算,此时C前面的B节点还没有执行。这个时候要不要回溯呢?实践过程中,A节点先执行完的到了C节点直接放弃执行交集,因为图是有多个起始节点的,让其他链路执行,肯定能执行到B节点,B节点执行完的时候再继续遍历也就能执行到C节点。所以到C节点执行交集的时候,只要先检查它的前驱节点有没有执行完,只要有任何一个前驱节点没执行完,就放弃执行权。
比如说流程图里前面节点的执行时间肯定不能大于后面节点的执行时间,。
校验环路问题:同时校验过程中还要避免环路,因为环路会导致递归遍历时无限循环。
解决方案:常见的检测链表环路的算法就是快慢双指针的方式,但我们的流程图还是比较复杂,起始节点可能有多个,这里的环路有两种情况:没有头节点的自闭环路(A->B, B->A, 闭环),有头节点的中间环路(A->B, B->C, C->B)。为此在进行深度遍历时维护了两个Set。一个Set用于存储已经遍历过的所有节点,遍历完成后看用户提交的所有节点是否都在这个Set里,如有不在集合中则说明图中存在自闭环路;另一个Set用做当前路径的递归栈,每次遍历到一个新节点的时候,先判断这个节点是否在递归栈中,在递归栈中则说明该节点已经遍历过了,也就是产生了中间环路。
交集、并集、差集的实现优化:因为我们的数据是按hash存在文件里的,两个文件执行交、并、差集的时候,是可以做一些优化的,不需要真的把两个文件都加载到内存里来,用两个Set做交并差。我只需要把一个文件加载到内存的Set中,另一个文件只需要用IO流的方式读取每一行数据,在用内存的Set.contains一下就行了。这个时候我用哪个文件放到内存里面呢,肯定是希望内存占用越小越好,所以在执行交、并、差的时候会先比较一下两个文件的大小,把较小的文件放到内存里面,大文件就一行一行读出来在内存里contains一下就行了。
其实hash分桶和交并差的优化逻辑都是用了和关系型数据库Join实现算法一样的逻辑,Hash Join和Block Nested Loop。
调度及时性:产品要求节点执行时间误差不能太大,技术上需要尽量降低数据库压力不能频繁的轮询。因为任务的执行时间可能就是当前时间,所以用户提交后需要立即调度一次。
解决方案:我们提供了一个JobCache会每分钟去更新数据库中未完成的任务。同时为了保证及时性,用户对任务修改提交后会将任务的triggerTime设置成 now,同时立即往 Redis 的队列中提交一个EntityChange的事件,CacheScheduler中以BRPOP方式取出事件以提醒JobCache更新相应 的任务。JobScheduler会每秒查看JobCache中是否存在需要调度的任务。 用户的这个更新会修改掉任务的version,原有任务的调度就会因为乐观锁异常而重新调度,重新调度的时候就能从JobCache中拿到最新的任务。
这整个项目的架子都是我搭的,读写文件的整个框架也是我写的,用的是Visitor模式:
1 | public interface BucketVisitor { |
然后组里其他人就负责写每个节点的具体逻辑就行了。

