[TOC]
JAVA集合框架可以是说是JAVA开发中使用次数最高的一套类,是JAVA对各种数据结构的实现。一个集合代表一组对象,使用集合框架可以独立于实现细节来操作这一组对象,而不用自己再造轮子。
集合接口概要:
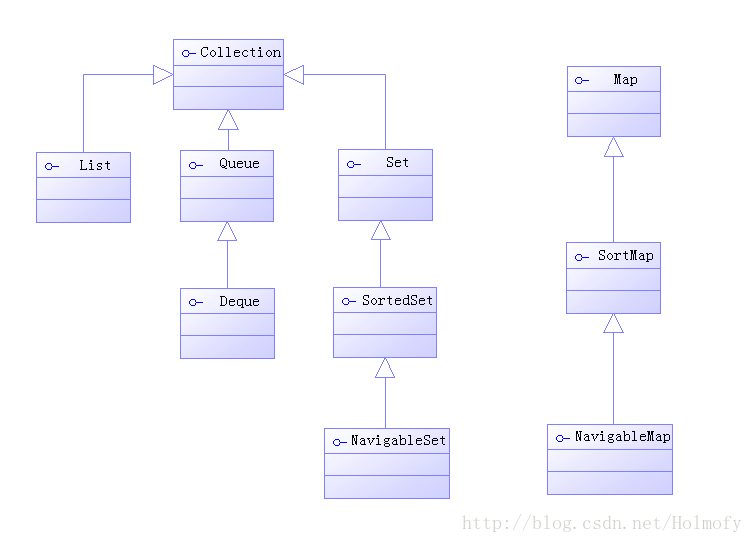
再加上并发库中的集合接口:
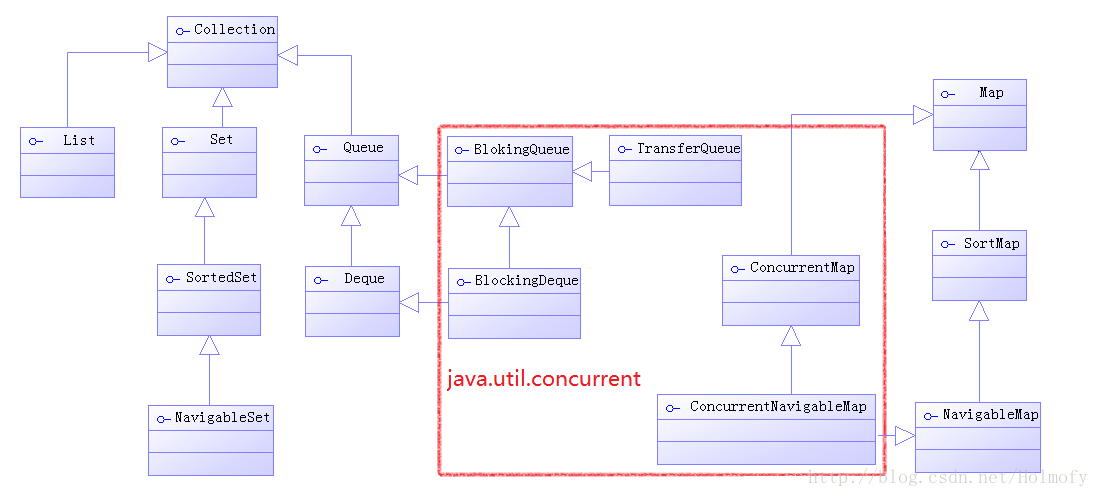
在下面的标题中用concurrent标记这个类是
java.util.concurrent包中的集合
List (since 1.2)
有序列表,代表一组有序可重复对象。
实现类:
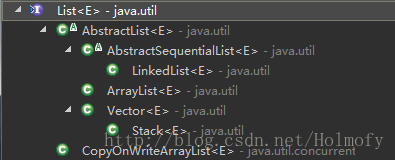
Vector(since 1.0):
与ArrayList实现基本类似,都是用Object数组存储,区别在于Vector是线程安全的,而且Vector扩容策略也比较老式:
newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity) (容量成倍增加)
如果构造时指定了capacityIncrement 扩容增量,则每次增加capacityIncrement (线性增加)。
该类完全可以使用Collections.synchronizedList(new ArrayList())代替。
JDK1.0当初的集合设计主要模仿C++的STL,可惜1.0的时候没有泛型(Java泛型与C++的模板本质上是不同的,不可相提并论),同时又为了线程安全加了
synchronized锁,重点是当初没有面向接口设计整个集合框架,最终导致了这个不伦不类的设计。
Stack(since 1.0):
“后进先出(LIFO)”的栈式结构,继承自Vector,这也决定了它被淘汰的命运:因为Deque接口的实现类可以作为栈使用
查看Deque接口
ArrayList(since 1.2):
数组实现的List,自动扩容,Java8.0中一般扩容策略为newCapacity = oldCapacity + (oldCapacity >> 1),也就是说每次扩容新容量为原始容量的1.5倍,另外在第一次添加元素的时候才申请内存(默认初始容量为10)。
ArrayList绝对是集合框架中使用次数最多的类。
LinkedList(since 1.2):
双向链表实现的List,在后续Java版本中又相继实现了Queue,Deque接口,所以该类可以当作链表、队列、栈使用。
因为LinkedList使用双向链表实现,所以作为List使用其查找元素效率不如ArrayList,但是在中间插入元素的效率比ArrayList高。
CopyOnWriteArrayList(since 1.5,concurrent):
通过拷贝数组来保证写线程不会影响到读线程(实现所谓的读写分离),所以该类允许读写同时进行;
同时使用ReentrantLock来实现多线程执行写操作的同步。
但是拷贝数组毕竟耗时,因此该类不适合用在写操作频繁的情况。
Map (since 1.2)
把Map放在前面是因为,Set的实现类是基于Map或List实现的。
表示一系列键值对映射(Key-Value)的集合,由于Map通过Key来查找Value,所以Key不能重复。
实现类:
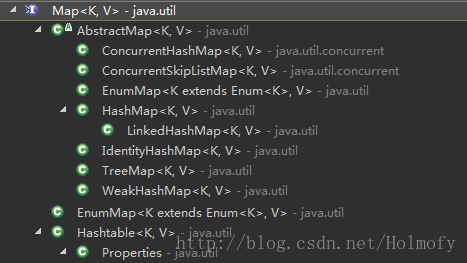
Hashtable(since 1.0):
哈希表,与HashMap实现原理相同,都是使用链式地址法解决哈希碰撞的。
与HashMap的区别:
- Hashtable使用synchronize关键字实现线程安全的,而HashMap不能保证线程安全;这一点与Vector相同
- Hashtable不允许Key为null(会抛空指针异常),而HashMap允许。
Hashtable基本被淘汰,Java的后续版本都没有对其升级。
更多相关内容可以查看HashMap
Propreties(since 1.0):
严格的说,这个类不能算是容器类。这个类一般用于存取属性配置文件的,该类实际上是一个Hashtable<Object,Object>对象。
1 | public class Properties extends Hashtable<Object,Object> |
HashMap(since 1.2):
HashMap在集合框架中的地位举足轻重,所以Java在每个版本中都对它进行了大大小小的性能优化。
HashMap对计算hash值的优化
哈希表,根据Key生成hashCode从而确定存储位置,时间复杂度为1,获取哈希值方法如下:
1 | static final int hash(Object key) { |
对于hash相同的元素(也就是哈希碰撞)使用链表(拉链法)进行延伸存储,拉链使用头插法。
当总体容量达到数组长度的0.75倍这个默认阈值后,重新定容,将数组长度扩大到原来的两倍,并将原来的数据重新计算hash存入新表中,这个过程叫做rehash。
HashMap重新定容耗时耗资源,所以如果能确定存取元素的最大容量,最好在构造时通过initialCapacity参数来指定容量,**默认初始容量为16($2^4$)**。
同时也可以通过构造方法中的loadFactor参数来自定义扩容因子,默认扩容因子为0.75。
另外,**HashMap的容量始终保持为$2^n$**。这样设计为了方便直接根据哈希值定位索引(用&位运算取代%取余运算):
index = (length - 1) & hash
当$length=2^n$时,length-1的二进制为全1,(length-1) & hash可以达到取余的效果。
所以在通过initialCapacity参数指定构造时的容量,会有下面这个运算:
1 | // initialCapacity指定为5,6,7的时候,实际容量都为8 |
官方文档中将这个延伸的链表称为桶,个人觉得还是叫“拉链”更为形象。下面当拉链进化成红黑树的时候,叫“拉链”就有点不合适了。
Java8中使用红黑树对拉链法进行优化
当出现所有的元素都集中在一条拉链上的极端情况时,HashMap就退化成链表,导致查找性能下降。
我们知道红黑树能够实现$log_2(N)$级别的查找速度,所以Java8使用红黑树对拉链进行了优化。
在HashMap中有这么几个常量:
1 | /** |
WeakHashMap(since 1.2):
使用上与HashMap类似,区别在于这里的Entry对象(Key-Value对)继承自WeakReference。
1 | public class WeakHashMap<K,V> extends AbstractMap<K,V> implements Map<K,V> { |
也就是说Entry中持有Key的弱引用,从而不影响GC的垃圾回收,Key被系统回收后会自动将Entry放入引用队列。WeakHashMap每次读写操作都会遍历这个引用队列,从而把已过期的Entry对象从表中删除。
另外WeakHashMap与HashMap计算hash的算法也略有不同:
1 | final int hash(Object k) { |
WeakHashMap也进行了二次幂优化:hash & (length-1)
IdentityHashMap(since 1.4):
与HashMap功能相同,区别在于IdentityHashMap使用k1 == k2判断key是否相同,也就是k1和k2是同一个对象的引用才认为是同一个key;
而HashMap则是(k1 == null ? k2 == null :k1.equals(k2) ),也就是两个对象满足内容相同就认为是同一个key。
根据上述特性,IdentityHashMap允许Key重复。
所以IdentityHashMap允许两个内容相同的对象作为Key,另外获取与HashMap获取哈希值的方式不同:
1 | private static int hash(Object x, int length) { |
LinkedHashMap(since 1.4):
LinkedHashMap继承自HashMap,在HashMap的基础上,通过维护一个双向链表来保存元素插入的顺序。
根据该双向链表就可以知道哪些数据是存入时间较长的,所以LinkedHashMap可以用作数据的LRU缓存(可以通过重载removeEldestEntry方法来定义缓存策略)。
下面是一个使用LinkedHashMap实现的最简单Least recently used缓存。
1 | public class LruCache extends LinkedHashMap { |
EnumMap(since 1.5):
元素只能是枚举类,构造EnumMap时指定枚举类型。底层使用数组实现存储,所以数据比较紧凑。Key不允许为null。使用相对比较少。
TreeMap(since 1.2):NavigableMap的实现类。查看NavigableMap接口实现类。
ConcurrentHashMap(since 1.5,concurrent):ConcurrentMap的实现类。查看ConcurrentMap接口实现类。
ConcurrentSkipListMap(since 1.6,concurrent):ConcurrentNavigableMap的实现类。查看ConcurrentNavigableMap接口实现类。
Android中还提供了一个数组实现的ArrayMap。HashMap将Key-Value包装成一个类对象,然后使用该类的数组。而ArrayMap直接将Key-Value放在一个Object数组中,通过2*n,2*n+1来对Key-Value进行区分,这和EnumMap在一定程度有有点相似。
SortedMap(since 1.2)与NavigableMap(since 1.6)
SortedMap在Map的基础上对Key自动排序
| 方法 | 方法说明 |
|---|---|
| Comparator<? super K> comparator() | 返回该Map中Key使用的比较器 |
| SortedMap<K,V> headMap(K toKey) | 头:小于toKey的所有Key-Value对,不包括toKey |
| SortedMap<K,V> tailMap(K fromKey) | 尾:大于fromKey的所有Key-Value对,包括fromKey |
| SortedMap<K,V> subMap(K fromKey, K toKey) | fromKey到toKey之间的所有Key-Value对,包括fromKey,不包括toKey。 |
| K firstKey() | 第一个Key,也就是最小的Key |
| K lastKey() | 最后一个Key,也就是最大的Key |
SortedMap实现类:
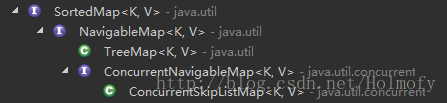
NavigableMap在SortedMap的基础上添加了更多的有序Map的操作。下图是NavigableMap增加的操作,更多细节可以查看Java官方文档。
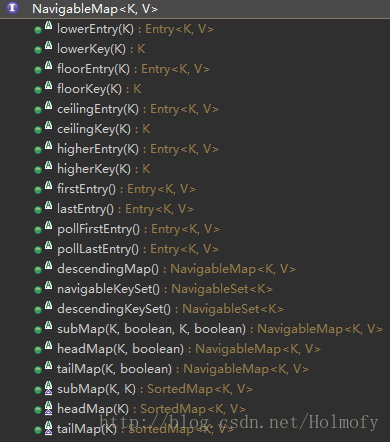
NavigableMap实现类:

TreeMap(since 1.2):
通过红黑树(一种自平衡二叉查找树树)实现的有序Map映射,因为红黑树的元素查找类似于二分查找,所以保证了增删改查等方法的时间复杂度$log_2(N)$。
因为元素是有序存储,所以需要实现Comparable接口或者在构造方法中指定Comparator比较器。
因为元素之间需要进行比较,所以TreeMap不允许元素为null(会抛空指针异常)。
ConcurrentSkipListMap可以查看ConcurrentNavigableMap接口的实现类。
ConcurrentMap (since 1.5)与ConcurrentNavigableMap (since 1.6)
在Map的基础上添加了一些原子操作,从而实现无锁数据结构,具有多线程高并发特性,更多内容可以查看这篇文章。
| 方法 | 等价操作 |
V putIfAbsent(K key, V value) | |
boolean remove(Object key, Object value) | |
boolean replace(K key, V oldValue, V newValue) | |
V replace(K key, V value) | |
ConcurrentMap 实现类:

ConcurrentNavigableMap是ConcurrentMap与NavigableMap的结合体:既有序又高并发。
ConcurrentHashMap(since 1.5,concurrent):
该类用来代替Hashtable实现多线高并发操作。与Hashtable相比支持高并发的读取操作,Hashtable由于所有的方法都加上了同步锁(包括读取操作),而ConcurrentHashMap对读取操作不加锁,对写入操作的关键部分加同步锁,进而降低锁粒度,所以在多线程操作的效率上ConcurrentHashMap比Hashtable更加高效。
ConcurrentSkipListMap(since 1.6,concurrent):
ConcurrentNavigableMap接口的唯一实现类。该数据结构使用跳跃链表实现,跳跃链表是一种查找速度与二叉查找树相当的数据结构,基于多级并联的链表实现,相较二叉查找树要消耗更多的内存资源,但实现起来比二叉查找树简单的多。关于跳跃链表的更多细节可以查看维基百科。
Set (since 1.2)
无序集合,代表一组无序不可重复的对象。与数学中的集合特性类似:无序性,互异性。
Set 实现类:
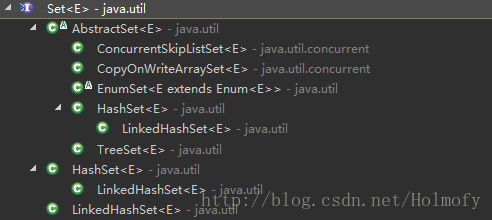
HashSet(since 1.2):
一个底层由HashMap实现的无序集合。只使用了HashMap的Key,而没有使用Value,HashSet的所有元素的Value都是一个Object常量:private static final Object PRESENT = new Object();。因为HashMap允许Key为null,所以HashSet中的元素也允许为null。
LinkedHashSet(since 1.4):
底层由LinkedHashMap实现。LinkedHashSet继承自HashSet,该类只有四个构造函数,这四个构造函数都是调用HashSet的这个构造函数(该构造方法包内私有):
1 | HashSet(int initialCapacity, float loadFactor, boolean dummy) { |
EnumSet(since 1.5):
只存储枚举类型的Set。根据具体的枚举类型,可以得到枚举类中的所有枚举值,进一步就确定这个集合最大的容量了。EnumSet就直接把所有枚举值放到一个数组,然后通过类似于BitSet的位图算法并借助枚举类值的ordinal作为索引来标记集合中是否有对应的枚举值。按照枚举类的大小它分成了两种实现,枚举值个数小于64的直接用一个long进行标记,这就是RegularEnumSet的实现;枚举值个数大于64的,则用long[]进行标记,这就是JumboEnumSet的实现。

CopyOnWriteArraySet(since 1.5,concurrent):
基于CopyOnWriteArraySet实现的无序集,与CopyOnWriteArrayList一样不适合写操作频繁的场合。由于底层使用数组实现,所以它的查找速度不如HashSet。
ConcurrentSkipListSet可以查看NavigableSet接口。
SortedSet (since 1.2)与NavigableSet (since 1.6)
SortedSet :有序集合,在Set基础上提供排序功能,由于Set基本上都是使用Map实现的(除了上面提到的EnumSet),所以SortedSet的排序功能也来自于SortedMap。
| 方法 | 方法说明 |
|---|---|
| Comparator<? super K> comparator() | 返回该Set元素使用的比较器 |
| SortedSet | 头:小于toElement的所有元素,不包括toElement |
| SortedSet | 尾:大于fromElement的所有元素,包括fromElement |
| SortedSet | fromElement到toElement之间的所有元素对,包括fromElement,不包括toElement。 |
| E first() | 第一个元素,也就是最小的元素 |
| E last() | 最后一个元素,也就是最大的元素 |
NavigableSet: 在SortedSet的基础上添加了更多的有序Set的操作。下图是NavigableSet增加的操作,更多细节可以查看Java官方文档。
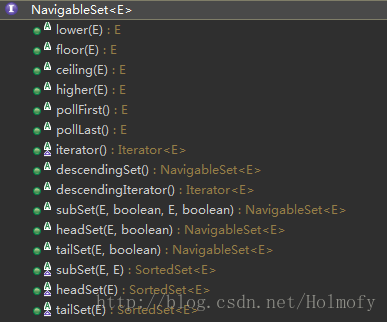
NavigableSet实现类:
TreeSet(since 1.2):
底层由TreeMap实现,与HashSet一样只使用Key不使用Value,Value都是同一个对象:private static final Object PRESENT = new Object();
ConcurrentSkipListSet(since 1.6,concurrent):
基于ConcurrentSkipListMap实现的有序集,因为ConcurrentSkipListMap支持并发操作,ConcurrentSkipListSet也支持并发操作。
Queue (since 1.5)
在普通集合的基础上添加了一些队列操作:
| 操作 | 失败抛出异常 | 失败返回false |
|---|---|---|
| 入队 | add(e) | offer(e) |
| 出队 | remove() | poll() |
| 检查 | element() | peek() |
看Queue的实现类之前,先来看一张Queue的继承图
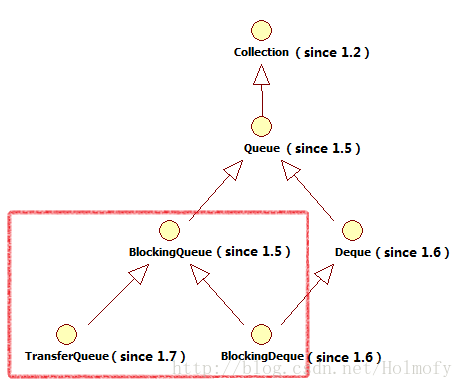
Queue这个接口仿佛就是为了并发库而设计的,所以Queue的实现类也几乎都是支持多线程的。
Queue实现类:
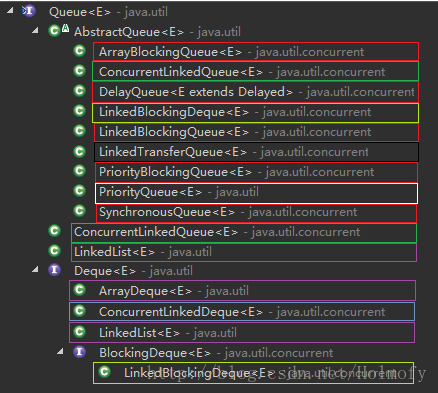
PriorityQueue(since 1.5):
优先级队列,使用数组实现二叉堆(完全二叉树),从而对元素进行排序,队列中的元素需要实现Comparable接口或者在构造方法中指定Comparator比较器。
ConcurrentLinkedQueue(since 1.5,concurrent):
无界限非阻塞的并发队列,使用了非阻塞同步算法(CAS)实现无锁数据结构,该类与BlockingQueue接口的实现类不同,BlockingQueue通过线程阻塞来实现生产者与消费者的同步,而无锁数据结构不会导致线程阻塞。关于CAS的内容可以参考这篇文章。
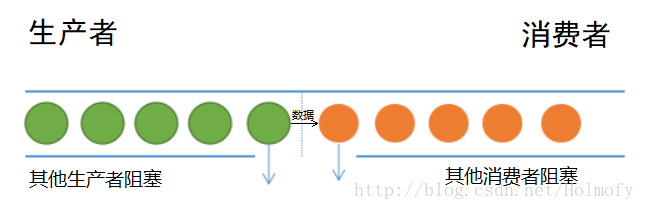
BlockingQueue (since 1.5,concurrent)
阻塞队列。在Queue的基础上进行阻塞扩展,如果队列为空读取元素会阻塞,如果队列已满添加元素会阻塞。用生产者消费者模式来解释就是:当生产者向队列添加元素但队列已满时,生产者会被阻塞;当消费者从队列移除元素但队列为空时,消费者会被阻塞。阻塞队列是线程间通信常用的手段。
| 抛出异常 | 返回false | 阻塞 | 超时 | |
| 入队 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 出队 | remove() | poll() | take() | poll(time, unit) |
| 检查 | element() | peek() | 无需该操作 | 无需该操作 |
实现类:
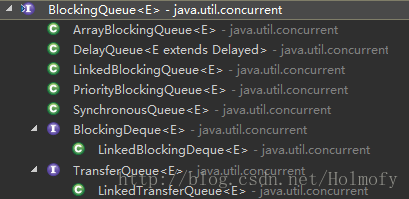
ArrayBlockingQueue(since 1.5,concurrent):
数组实现的阻塞队列,数组大小不会自动增长。队列已满,生产者线程阻塞。元素不允许为null。
DelayQueue(since 1.5,concurrent):
使用PriorityQueue与ReentrantLock实现的延时阻塞队列,该集合存储的元素需要实现Delayed接口,该集合通过Delayed接口来获取元素对应的延时时长。元素不能为null。
LinkedBlockingQueue(since 1.5):
单向链表实现的阻塞队列,该集合功能上类似与ArrayBlockingQueue。LinkedBlockingQueue可以在构造方法中指定最大容量,如果没有指定则为Integer.MAX_VALUE,相当于不限容,所以LinkedBlockingQueue相比ArrayBlockingQueue有更大的吞吐量。元素不允许为null。
PriorityBlockingQueue(since 1.5):
在PriorityQueue的基础上对读写操作加重入锁(ReentrantLock)来达到多线程的同步。
SynchronousQueue(since 1.5):
这个类是一个比较奇葩的容器,或许不能称其为容器,因为它是一个0容量的队列,不像ArrayBockingQueue和LinkedBlockingQueue那样有缓冲区,SynchronousQueue没有缓冲区,内部直接通过TransferQueue(公平模式)或TransferStack(不公平模式)来进行生产者与消费者的数据传递(这是Java6之后的实现方式),公平模式使生产者(或消费者)线程排队依次添加(或取出),而费公平模式允许恶性竞争,使用SynchronousQueue可以让生产者线程与消费者线程之间的同步:生产者生产一个消费者就消费一个。SynchronousQueue不允许添加null元素。
Deque (since 1.6)
双端队列,两端都支持插入删除。既可以把它当Queue用又可以把它当Stack用。

| 第一元素(头) | 最后元素(尾) | |||
| 抛出异常 | 返回false | 抛出异常 | 返回false | |
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 删除 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 检查 | getFirst() | peekFirst() | getLast() | peekLast() |
实现类:
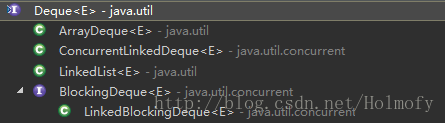
LinkedList(since 1.2):双向链表实现双端队列,前面已经提过了。
ArrayDeque(since 1.6):
数组实现的双端队列。容量按两倍的方式自动增长。不允许元素为null。双端队列既可以当栈用又可以当队列用,作为栈使用速度比Stack类更快,作为队列用速度比LinkedList类更快。
ConcurrentLinkedDeque(since 1.5,concurrent):
无界限非阻塞的并发双端队列,与ConcurrentLinkedQueue一样使用非阻塞同步算法实现。
LinkedBlockingDeque(since 1.7,concurrent):
BlockingDeque接口的实现类。查看BlockingDeque接口
BlockingDeque (since 1.6)
BlockingDeque与Deque的关系类似于BlcokingQueue与Queue的关系。
| 第一元素(头) | ||||
| 抛出异常 | 返回false | 阻塞 | 超时 | |
| 插入 | addFirst(e) | offerFirst(e) | putFirst(e) | offerFirst(e, time, unit) |
| 删除 | removeFirst() | pollFirst() | takeFirst() | pollFirst(time, unit) |
| 检查 | getFirst() | peekFirst() | 无需该操作 | 无需该操作 |
| 最后元素(尾) | ||||
| 抛出异常 | 返回false | 阻塞 | 超时 | |
| 插入 | addLast(e) | offerLast(e) | putLast(e) | offerLast(e, time, unit) |
| 删除 | removeLast() | pollLast() | takeLast() | pollLast(time, unit) |
| 检查 | getLast() | peekLast() | 无需该操作 | 无需该操作 |
实现类:
- java.util.concurrent包
- LinkedBlockingDeque(since 1.7):双向链表实现的双端阻塞队列。与LinkedBlockingQueue类似,只是说这个类还可以当作栈使用。
TransferQueue (since 1.7)
在BlockingQueue的基础上更进一步,生产者会一直阻塞直到所添加到队列的元素被某一个消费者所消费(不仅仅是添加到队列里就完事)。这个和SynchronousQueue有点类似,但区别在于SynchronousQueue只允许一个生产者线程将数据传递给一个消费者线程,其他线程想要添加或取出数据就会阻塞;而TransferQueue可以允许多个生产者线程同时与多个消费者线程进行数据传递,所以当我们把TransferQueue的容量设为0时TransferQueue就等价于SynchronousQueue了。
| 返回值 | 方法说明 |
|---|---|
int | getWaitingConsumerCount()返回调用 BlockingQueue.take()或BlockingQueue.poll消费者方法而阻塞的消费者的数量 |
boolean | hasWaitingConsumer()true是否有消费者正在调用BlockingQueue.take()或BlockingQueue.poll消费者方法 |
void | transfer(E e)将元素e转交给消费者,如有必要该方法阻塞以等待消费者将元素e消费。 |
boolean | tryTransfer(E e)如果可以立即将元素e转交给等待的消费者返回true,否则返回false。 |
boolean | tryTransfer(E e, long timeout, TimeUnit unit)如果可以在指定时间内将元素转交给消费者返回true,否则返回false。 |
- java.util.concurrent包
- LinkedTransferQueue(since 1.7):TransferQueue接口唯一的一个实现类,相关功能可以查看TransferQueue接口的定义。注意的是
LinkedTransferQueue.size()方法与大多数集合不一样,该类没有成员变量中没有保存容器的size,size()方法会临时性的去遍历整个链表来计算元素个数,所以这是个非常耗时的操作,而且由于遍历过程中可能有另外的线程操作,所以该方法获取的size可能是不准确的。
- LinkedTransferQueue(since 1.7):TransferQueue接口唯一的一个实现类,相关功能可以查看TransferQueue接口的定义。注意的是
Collections工具类
Collections工具类中的包装类
Collections.unmodifiable 不可修改包装类
经过unmodifiable方法包装的集合对象将成为只读对象,对只读的集合进行add,remove等修改操作将会抛出异常。这个方法使用场景比较广泛。比如说一个公司(Company)有一个字段为员工表(employeeList),同时有一个获取员工表的方法List getEmployeeList(),我们希望员工的删减只能通过Company类中的指定方法来修改,List getEmployeeList()方法返回员工表但是不能被外部修改,此时就需要使用unmodifiableList对employeeList进行包装了。
1 | public class Company { |
Collections中的unmodified方法有以下几个:
public static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c)public static <T> List<T> unmodifiableList(List<? extends T> list)public static <T> Set<T> unmodifiableSet(Set<? extends T> s)public static <T> SortedSet<T> unmodifiableSortedSet(SortedSet<T> s)public static <T> NavigableSet<T> unmodifiableNavigableSet(NavigableSet<T> s)public static <K,V> Map<K,V> unmodifiableMap(Map<? extends K, ? extends V> m)public static <K,V> SortedMap<K,V> unmodifiableSortedMap(SortedMap<K, ? extends V> m)public static <K,V> NavigableMap<K,V> unmodifiableNavigableMap(NavigableMap<K, ? extends V> m)
这与Google Guava中的Immutable集合工具类有点类似。
Collections.synchronized 同步包装类
synchronized包装后的集合是线程同步的,比如ArrayList对象可以经过synchronizedList方法进行包装从而达到线程同步的目的,有了这个线程同步的包装类,ArrayList可以完全替代Vector。
public static <T> Collection<T> synchronizedCollection(Collection<T> c)public static <T> List<T> synchronizedList(List<T> list)public static <T> Set<T> synchronizedSet(Set<T> s)public static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T> s)public static <T> NavigableSet<T> synchronizedNavigableSet(NavigableSet<T> s)public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m)public static <K,V> SortedMap<K,V> synchronizedSortedMap(SortedMap<K,V> m)public static <K,V> NavigableMap<K,V> synchronizedNavigableMap(NavigableMap<K,V> m)
Collections.checked 动态类型检查包装类
这主要归咎于Java的类型擦除(Java的泛型与C++的泛型不同,准确的说C++应该叫做“模板”,C++在编译后会根据模版的使用情况生成多套可执行代码,而Java使用同一套代码)。Java集合实际存储的时候都是使用Object数组,集合中不保存集合元素的数据类型,所以在源代码中你会看到类似下面的代码:
1 |
|
因此Java对于List list = new ArrayList<String>()这样的赋值也不会报错。而此时我们往list中添加任何类型的数据都没有影响list.add(1) list.add(true),但是我们本意是想往该集合中添加String类型的数据。这个时候就可以使用checked动态类型检查了。拿上面的那个公司与员工表的例子,现在我们可以通过getEmployeeList获取员工表并对员工表进行修改。
1 | public class Company { |
客户调用时可能会做出这样的操作
1 | public class Client { |
上面的用户很显然执行了一个不正确的操作,但是程序照样能够运行,不会报错。此时我们就可以进行动态类型检查。
1 | public class Company { |
这样就能确保用户只能往员工表中添加员工,而不能添加其他元素了。
Collections中的checked方法有以下几个:
public static <E> Collection<E> checkedCollection(Collection<E> c, Class<E> type)public static <E> List<E> checkedList(List<E> list, Class<E> type)public static <E> Set<E> checkedSet(Set<E> s, Class<E> type)public static <E> SortedSet<E> checkedSortedSet(SortedSet<E> s, Class<E> type)public static <E> NavigableSet<E> checkedNavigableSet(NavigableSet<E> s, Class<E> type)public static <K, V> Map<K, V> checkedMap(Map<K, V> m, Class<K> keyType, Class<V> valueType)public static <K,V> SortedMap<K,V> checkedSortedMap(SortedMap<K, V> m, Class<K> keyType, Class<V> valueType)public static <K,V> NavigableMap<K,V> checkedNavigableMap(NavigableMap<K, V> m, Class<K> keyType, Class<V> valueType)public static <E> Queue<E> checkedQueue(Queue<E> queue, Class<E> type)
Collections类中的简单工具方法
列表逆序
1
public static void reverse(List<?> list)
列表填充
1
public static <T> void fill(List<? super T> list, T obj)
列表拷贝
1
public static <T> void copy(List<? super T> dest, List<? extends T> src)
列表元素交换
1
public static void swap(List<?> list, int i, int j)
计算集合中元素出现次数
1
public static int frequency(Collection<?> c, Object o)
集合元素是否相交
1
public static boolean disjoint(Collection<?> c1, Collection<?> c2)
集合最大值,最小值
1
2
3
4public static <T extends Object & Comparable<? super T>> T min(Collection<? extends T> coll)
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)
public static <T> T max(Collection<? extends T> coll, Comparator<? super T> comp)
public static <T> T min(Collection<? extends T> coll, Comparator<? super T> comp)集合元素替换
1
public static <T> boolean replaceAll(List<T> list, T oldVal, T newVal)
添加若干元素
1
public static <T> boolean addAll(Collection<? super T> c, T... elements)
查找子列表
1
2public static int indexOfSubList(List<?> source, List<?> target)
public static int lastIndexOfSubList(List<?> source, List<?> target)
Collections类中的算法
排序算法
Collections直接调用list.sort方法,该方法底层调用Arrays类中的排序算法。
1 | public static <T extends Comparable<? super T>> void sort(List<T> list) |
关于排序算法可以先参考常见排序算法及Java实现和SinglePivotQuickSort与DualPivotQuickSort及其JAVA实现。
二分查找算法
1 | int binarySearch(List<? extends Comparable<? super T>> list, T key) |
洗牌算法
1 | public static void shuffle(List<?> list) |
列表旋转算法
1 | // 列表的旋转可能不好理解,你把list想象成一个环。 |
Collections中的适配器
Collections集合中使用对象的适配器模式实现并提供了两个适配器,分别可以将Map适配成Set,Deque适配成Stack。
1 | public static <E> Set<E> newSetFromMap(Map<E, Boolean> map) // 将Map适配成Set (SetFromMap) |

