[TOC]
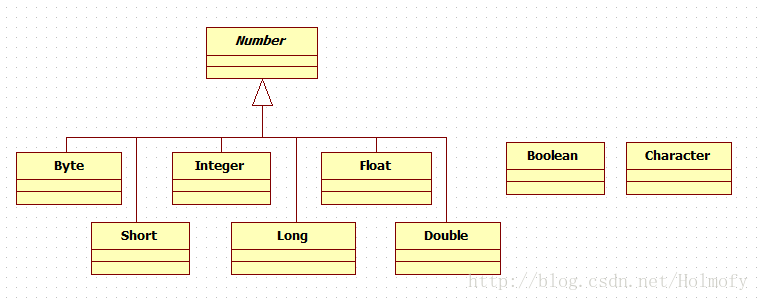
八种基本数据类型 Java语言中有八种基本数据类型:
byte,short,int,long,float,double,char,boolean
C语言因为依赖与CPU平台,数据类型所占字节数可能会因硬件平台以及编译器的不同而有所改变。因为Java是不依赖于任何硬件平台的软件平台,所以它在设计的时候每种数据类型的所占的字节数是固定的(除boolean以外)。
数据类型 所占字节数 备注 byte 1Byte 8位整数范围: short 2Byte 16位整数范围: int 4Byte 32位整数范围 long 8Byte 64位整数范围 float 4Byte 单精度的32位IEEE 754浮点数标准 double 8Byte 双精度的64位IEEE 754浮点数标准 char 2Byte 16位的Unicode字符范围:\u0000 ~ \uffff boolean 不确定
注意:Java中boolean比较特殊:单个boolean在编译时映射成int;boolean数组则会被编译成byte数组。用1表示true,0表示false。参考JVM规范
基本数据类型的包装类 Java中为上面的八种基本类型提供了包装类,从而让基本类型变成引用类型。有了这些包装类我们就可以在ArrayList,HashMap等Java集合类中存储基本的数据类型了(因为集合类型底层都是使用Object引用类型)。
原本JDK1.5之前这些基本数据类型要变成包装类,必须得通过相应的构造函数来对基本数据类型进行包装。这就导致一个问题:如果我往ArrayList中存入一万个整型的1,则需要new出一万个Integer对象。这无疑会消耗很大的内存(Java对象不像C语言结构体那么干净,Java对象头部有很多字段,诸如monitor等信息)。
于是JDK5.0后提供了自动拆装箱机制。自动拆装箱机制分为两个操作:自动拆箱(auto boxing)和自动装箱(auto unboxing)
比如下面这段简短的代码:
1 2 3 4 5 6 7 8 9 10 11 12 public class NumberTest { public static void main (String[] args) { Integer i1 = 10 ; int i2 = i1; Boolean b1 = true ; boolean b2 = b1; Character c1 = 'c' ; char c2 = c1; } }
使用以下Windows命令对其进行编译后并进行反编译:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 C:\Users\Holmofy\Desktop>javac NumberTest.java C:\Users\Holmofy\Desktop>dir |find "NumberTest" 2017 /05 /23 22 :50 599 NumberTest.class2017 /05 /23 22 :48 198 NumberTest.javaC:\Users\Holmofy\Desktop>javap -c NumberTest > NumberTest.javap C:\Users\Holmofy\Desktop>dir |find "NumberTest" 2017 /05 /23 22 :50 599 NumberTest.class2017 /05 /23 22 :48 198 NumberTest.java2017 /05 /23 22 :51 1 ,162 NumberTest.javapC:\Users\Holmofy\Desktop>
打开得到的反编译文件NumberTest.javap:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Compiled from "NumberTest.java" public class NumberTest { public NumberTest () ; Code: 0 : aload_0 1 : invokespecial #1 4 : return public static void main (java.lang.String[]) ; Code: 0 : bipush 10 2 : invokestatic #2 5 : astore_1 6 : aload_1 7 : invokevirtual #3 10 : istore_2 11 : iconst_1 12 : invokestatic #4 15 : astore_3 16 : aload_3 17 : invokevirtual #5 20 : istore 4 22 : bipush 99 24 : invokestatic #6 27 : astore 5 29 : aload 5 31 : invokevirtual #7 34 : istore 6 36 : return }
确实如此。
包装类的缓存池 前面说自动装箱调用的相应包装类的valueOf静态方法。那看看这些静态方法的实现:
Byte
1 2 3 4 public static Byte valueOf (byte b) { final int offset = 128 ; return ByteCache.cache[(int )b + offset]; }
Short
1 2 3 4 5 6 7 8 public static Short valueOf (short s) { final int offset = 128 ; int sAsInt = s; if (sAsInt >= -128 && sAsInt <= 127 ) { return ShortCache.cache[sAsInt + offset]; } return new Short (s); }
Integer
1 2 3 4 5 public static Integer valueOf (int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer (i); }
Long
1 2 3 4 5 6 7 public static Long valueOf (long l) { final int offset = 128 ; if (l >= -128 && l <= 127 ) { return LongCache.cache[(int )l + offset]; } return new Long (l); }
Float
1 2 3 public static Float valueOf (float f) { return new Float (f); }
Double
1 2 3 public static Double valueOf (double d) { return new Double (d); }
Character
1 2 3 4 5 6 public static Character valueOf (char c) { if (c <= 127 ) { return CharacterCache.cache[(int )c]; } return new Character (c); }
Boolean
1 2 3 public static Boolean valueOf (boolean b) { return (b ? TRUE : FALSE); }
通过查看源码发现,总结出下面几个结论:
Byte,Short,Integer,Long这四种整数包装类型都缓存了-128 ~ 127(即256个数据)。 Float,Double这两个浮点包装类型没有缓存,valueOf直接调用构造方法进行包装。 Character包装类型缓存了0 ~ 127总共128个ASCII码值。 Boolean包装类型缓存了true(TRUE)和false(FALSE)。 有了这些缓存数据,从而避免了前面所说的大量new对象的问题。但也正因为这些缓存数据,也导致了以下的现象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class NumberTest { public static void main (String[] args) { Integer i1 = new Integer (100 ); Integer i2 = new Integer (100 ); System.out.println(i1 == i2); Integer i3 = 100 ; Integer i4 = 100 ; System.out.println(i3 == i4); Integer i5 = 200 ; Integer i6 = 200 ; System.out.println(i5 == i6); } }
运行结果:
很明显这是Integer缓存搞的鬼:100是缓存对象,而200不是缓存对象。
也许你不会觉得这对程序有什么影响,但是如果你了解过IdentityHashMap这个集合类,你就不会这么想了。
关于IdentityHashMap的介绍可以查看Java集合框架总结和巩固
Integer缓存池的自定义配置 通过查看Byte,Short,Integer,Long源码你会发现,它们缓存都包装在一个相应的类中ByteCache、ShortCache、IntegerCache、LongCache。其中ByteCache,ShortCache,LongCache这三个内部类代码基本一致:都是缓存-127~128的数据。
以下代码均来自jdk1.8.0_131,其他版本不能保证完全相同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 private static class ByteCache { private ByteCache () {} static final Byte cache[] = new Byte [-(-128 ) + 127 + 1 ]; static { for (int i = 0 ; i < cache.length; i++) cache[i] = new Byte ((byte )(i - 128 )); } } private static class ShortCache { private ShortCache () {} static final Short cache[] = new Short [-(-128 ) + 127 + 1 ]; static { for (int i = 0 ; i < cache.length; i++) cache[i] = new Short ((short )(i - 128 )); } } private static class LongCache { private LongCache () {} static final Long cache[] = new Long [-(-128 ) + 127 + 1 ]; static { for (int i = 0 ; i < cache.length; i++) cache[i] = new Long (i - 128 ); } }
但IntegerCache类的内容就丰富了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private static class IntegerCache { static final int low = -128 ; static final int high; static final Integer cache[]; static { int h = 127 ; String integerCacheHighPropValue = sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high" ); if (integerCacheHighPropValue != null ) { try { int i = parseInt(integerCacheHighPropValue); i = Math.max(i, 127 ); h = Math.min(i, Integer.MAX_VALUE - (-low) -1 ); } catch ( NumberFormatException nfe) { } } high = h; cache = new Integer [(high - low) + 1 ]; int j = low; for (int k = 0 ; k < cache.length; k++) cache[k] = new Integer (j++); assert IntegerCache.high >= 127 ; } private IntegerCache () {} }
可以看出Java会去查找虚拟机的java.lang.Integer.IntegerCache.high属性来决定创建多大的缓存池,如果该属性小于127则使用默认的127作为缓存池的最大界限,否则就使用java.lang.Integer.IntegerCache.high属性中的值。我们可以通过java命令的-XX:AutoBoxCacheMax=<size>来设置JVM的java.lang.Integer.IntegerCache.high属性。
比如下面这个例子:
1 2 3 4 5 6 7 public class Test { public static void main (String[] args) { Integer a = 256 ; Integer b = 256 ; System.out.println(a == b); } }
按照前面的解释,正常情况下运行会输出false。在运行时进行如下配置就会输出true。
包装类中的其他工具方法 在这些基本数据类型的包装类中还提供给我们许多的工具方法。
解析字符串
在这些包装类中都有parseXxxx这样的静态方法,使用这些静态方法能够将字符串类型的值解析成相应的数据类型。并且对于Byte,Short,Integer,Long这四种整数包装类型还可以在解析时指定基数(也就是使用8进制,使用10进制还是16进制)。
转换成字符串
包装类中还有toString静态方法,能将基本数据类型转换成相应的字符串值。
其他:Boolean中的逻辑运算方法、Character中的静态工具方法最多(如判断数字字符、空白字符、西欧字符,转大写、小写),这些工具方法正等待着各位自己去发掘(避免重复造轮子哦)。
基本数据类型的格式化输出 在Java中提供了两个类PrintStream和PrintWriter支持常见数据的格式化输出。
关于PrintStream和PrintWriter的更多详细内容可以参考JavaIO总结与巩固
比如我们常用的System.out.print等方法也是该类中的方法。
除了这些方法,还提供了format,printf等方法。
1 2 3 4 5 6 7 8 PrintStream format (String format, Object ... args) ; PrintStream format (Locale l, String format, Object ... args) PrintStream printf (String format, Object ... args) PrintStream printf (Locale l, String format, Object ... args) PrintWriter format (String format, Object ... args) ; PrintWriter format (Locale l, String format, Object ... args) PrintWriter printf (String format, Object ... args) PrintWriter printf (Locale l, String format, Object ... args)
这些方法都是直接或间接地调用了java.util.Formatter中的format方法。在使用上这些方法和C语言中的printf方法用法上还是有很多的差别。
转换符 备注 d decimal。以十进制输出的整数,java不支持i f float。以十进制输出的浮点数,java中没有lf s string。输出字符串,java有字符串连接,这个用的比较少 n newline。换行,java推荐使用%n代替\n ty,tY time year。ty—两位数年份,tY—四位数年份 tB 以地区的方式显示月份,如:May,五月 tm time month。两位数月份不够补零 td,te time day。td—两位数日期不够补零,te—不会补零 tl 十二进制的小时数 tM time minutes。两位数分钟数不够补零 tp 以地区的方式显示上下午,如:AM|PM,上午|下午 tD time Date。等价于:%tm%td%ty 08 以8位字符输出,不够前面补零,并右对齐 + 输出正负号(包括符号) - 左对齐 , 以地区的方式输出分隔符,如:122,345 .3 输出时保留三位小数 10.3 以10位字符输出,右对齐,并保留三位小数
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import java.util.Calendar;import java.util.Locale;public class TestFormat { public static void main (String[] args) { long n = 461012 ; System.out.format("%d%n" , n); System.out.format("%08d%n" , n); System.out.format("%+8d%n" , n); System.out.format("%,8d%n" , n); System.out.format("%+,8d%n%n" , n); double pi = Math.PI; System.out.format("%f%n" , pi); System.out.format("%.3f%n" , pi); System.out.format("%10.3f%n" , pi); System.out.format("%-10.3f%n" , pi); System.out.format(Locale.FRANCE, "%-10.4f%n%n" , pi); Calendar c = Calendar.getInstance(); System.out.format("%tB %te, %tY%n" , c, c, c); System.out.format("%tl:%tM %tp%n" , c, c, c); System.out.format("%tD%n" , c); } }
关于字符格式化的更多内容可以查看JDK中的java.text.*`包中的相关描述。
Java中的数学运算 java像大多数语言一样不仅提供了+,-,*,/,%这样的基本数学运算,还提供了一个Math类来进行更复杂的数学运算。
调用Math类中的数学方法我们可以使用两种方式:
因为Math类属于java.lang包下的,所以我们无需另外导包,可以直接Math.xxx()进行调用。 因为Math类的方法都是static静态的,所以我们可以使用import static java.lang.Math.*方式导入Math类的静态方法。这样我们调用的时候可以不用加类名,直接调用xxx()方法。 Math类中的常量和最基本方法 Math.E, 自然对数的底数Math.PI, 圆周率最基础的方法 方法 方法描述 double abs(double d)取绝对值 double ceil(double d)向上取整 double floor(double d)向下取整 double rint(double d)四舍五入取整 long round(double d)四舍五入取整 double min(double arg1, double arg2)返回两个参数的较小值 double max(double arg1, double arg2)返回两个参数的较大值
指数运算与幂运算 幂运算与指数运算 方法 方法描述 double exp(double d)自然底数e的d次幂 double log(double d)d的自然对数。ln(d) double pow(double base, double exponent)b的e次幂 double sqrt(double d)开平方根。根号d
三角函数运算 三角函数摘要 方法 方法描述 double sin(double d)求正弦值 double cos(double d)求余弦值 double tan(double d)求正切值 double asin(double d)反正弦值。arcsine(sin(x))==x double acos(double d)反余弦值。arccos(cos(x))==x double atan(double d)反正切值。arctan(tan(x))==x double atan2(double y, double x)将直角坐标系(x, y) 转成极坐标系 (r, theta) 并返回 theta的值。 double toDegrees(double d)将弧度制转换成角度制
产生伪随机数 Math.random()函数底层使用java.util.Random类随机生成一个大于等于零并且小于一的双精度浮点数:0.0 <= Math.random() < 1.0。这和C语言的rand()函数还是有区别,rand函数生成的是0到32767(RAND_MAX)之间的数。这个方法比较鸡肋,我们完全可以使用java.util.Random或java.security.SecureRandom这两个类来生成随机数。
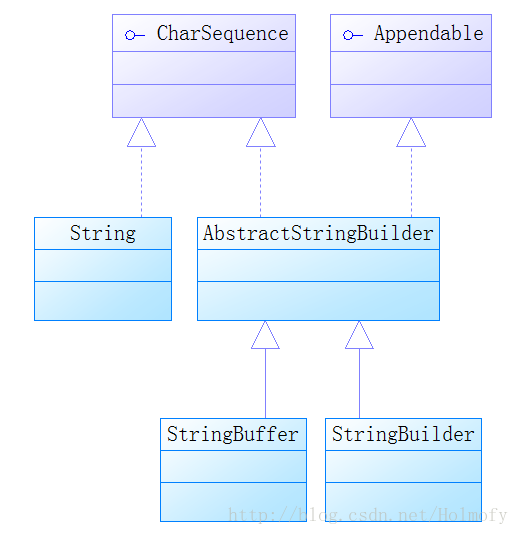
Java中的字符串 Java字符串与C/C++字符串对比 字符串是程序设计中最常用到的数据类型。
Java中有一个专门的类String用来代表字符串,而不像C/C++中字符串仅仅是一个以\0结尾的字符数组(C语言的字符串常量与字符数组还是有很大的区别的)。
C/C++:
1 2 char str[] = "Hello World" ;
Java:
1 2 3 4 5 char [] cArr = {'H' ,'e' ,'l' ,'l' ,'o' ,' ' ,' W' ,'o' ,'r' ,'l' ,'d' ,'!' };String str1 = new String (cArr);String str2 = "Hello World!" ;
正因C/C++语言字符串是基本数据类型,导致了C++中各种对字符串类的封装:如STL中的std::string,MFC中的CString,Qt中的QString…各种库中都有自己实现的封装。
另外Java中char类型占两个字节,使用Unicode字符集UTF-16编码;而C/C++的char类型占一个字节,使用ASCII编码。
关于编码的问题可以查看我的这篇文章:从ASCII、ISO-8859、GB2312、GBK到Unicode的UCS-2、UCS-4、UTF-8、UTF-16、UTF-32
Java字符串的不可变性 尽管Java的String类中提供了像replace()这样的修改字符串的方法,但实际上Java的String类是一个不可变类型:一旦创建,对象的字符内容不可修改。那些replace()之类的方法都是重新创建一个String类对象作为返回值。
那我们平时经常使用“+”操作符作为来进行字符串连接,是怎样实现的呢?
Java的字符串连接底层实现 下面我们写一个简单的小Demo来看一下String的字符串连接:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class StringTest { public static void main (String[] args) { String a = "Hello" ; String b = new String ("Hello" ); System.out.println(a == b); String c = "Hello" ; System.out.println(a == c); String d = c + "World!" ; String e = "Hello" + "World!" ; System.out.println(d == e); String f = "HelloWorld!" ; System.out.println(e == f); } }
我们编译运行,然后反编译一下看看底层实现
1 2 3 4 5 6 7 8 9 10 11 12 C:\Users\Holmofy\Desktop>javac StringTest.java C:\Users\Holmofy\Desktop>dir |find "StringTest" 2017 /06 /02 20 :01 1 ,233 StringTest.class2017 /05 /26 16 :04 441 StringTest.javaC:\Users\Holmofy\Desktop>javap -c StringTest > StringTest.javap C:\Users\Holmofy\Desktop>dir |find "StringTest" 2017 /06 /02 20 :01 1 ,233 StringTest.class2017 /05 /26 16 :04 441 StringTest.java2017 /06 /02 20 :02 5 ,397 StringTest.javap
我们先不讨论运行结果,先来看一下StringTest.javap这个反编译出来的文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 Compiled from "StringTest.java" public class StringTest { public StringTest () ; Code: 0 : aload_0 1 : invokespecial #1 4 : return public static void main (java.lang.String[]) ; Code: 0 : ldc #2 2 : astore_1 3 : new #3 6 : dup 7 : ldc #2 9 : invokespecial #4 12 : astore_2 13 : getstatic #5 16 : aload_1 17 : aload_2 18 : if_acmpne 25 21 : iconst_1 22 : goto 26 25 : iconst_0 26 : invokevirtual #6 29 : ldc #2 31 : astore_3 32 : getstatic #5 35 : aload_1 36 : aload_3 37 : if_acmpne 44 40 : iconst_1 41 : goto 45 44 : iconst_0 45 : invokevirtual #6 48 : new #7 51 : dup 52 : invokespecial #8 55 : aload_3 56 : invokevirtual #9 59 : ldc #10 61 : invokevirtual #9 64 : invokevirtual #11 67 : astore 4 69 : ldc #12 71 : astore 5 73 : getstatic #5 76 : aload 4 78 : aload 5 80 : if_acmpne 87 83 : iconst_1 84 : goto 88 87 : iconst_0 88 : invokevirtual #6 91 : ldc #12 93 : astore 6 95 : getstatic #5 98 : aload 5 100 : aload 6 102 : if_acmpne 109 105 : iconst_1 106 : goto 110 109 : iconst_0 110 : invokevirtual #6 113 : return }
可以看出字符串连接实际上是new一个StringBuilder对象,然后调用它的append方法,最后调用toString方法转换成String类型的不可变对象。
我们将结果运行出来:
1 2 3 4 5 C:\Users\Holmofy\Desktop>java StringTest false true false true
从运行结果可以得出以下结论:
1 2 3 4 5 6 7 8 "Hello" != new String ("Hello" ); "Hello" == "Hello" ; String c = "Hello" ;c + "World!" != "Hello" + "World!" ; "Hello" + "World!" == "HelloWorld!" ;
String字符串常量池的底层实现 Java中所有的字符串常量都存储在字符串常量池中。比如上面Demo中的”Hello”,”HelloWorld!”这种字面量。
对于我们通过构造方法new出来的String对象都是创建在Java的堆内存中,这样的对象一旦失去引用后,我们就无法再次使用了,只能等着GC回收这个对象。
其实String中有个intern()方法,可以将我们new出来的字符串对象,加入到字符串常量池中,这样我们下次再使用这样的字面量时,Java会从池中返回这个对象的引用。
举个例子:
1 2 3 4 5 6 7 8 StringBuilder builder = new StringBuilder ();builder.append((int )(Math.random()*100 )); builder.append('+' ); builder.append((int )(Math.random()*100 )); builder.append('=' ); String question = builder.toString(); question.intern();
我们先看一下Java文档中是怎么描述这个方法的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public native String intern () ;
如果该在字符串常量池中已经有一个和该字符串值相等(equal)的字符串对象,则intern方法会返回池中的这个对象;如果没有,则将该字符串加入到字符串常量池中。
所以两个字符串只有当s.equal(t)成立才会有s.intern() == t.intern()。
intern方法是native方法,接下来我们看一下它的C/C++实现。
注意我的JDK和JVM源码是openjdk-8-src-b132-03_mar_2014这个版本的,不同版本源码可能会有所差别。
首先找到java/lang/String.c文件:
1 2 3 4 5 6 7 8 #include "jvm.h" #include "java_lang_String.h" JNIEXPORT jobject JNICALL Java_java_lang_String_intern (JNIEnv *env, jobject this ) return JVM_InternString (env, this ); }
这个文件中就一个intern方法,底层调用的JVM的InternString方法。
找到Jvm.cpp:
1 2 3 4 5 6 7 8 JVM_ENTRY (jstring, JVM_InternString (JNIEnv *env, jstring str)) JVMWrapper ("JVM_InternString" ); JvmtiVMObjectAllocEventCollector oam; if (str == NULL ) return NULL ; oop string = JNIHandles::resolve_non_null (str); oop result = StringTable::intern (string, CHECK_NULL); return (jstring) JNIHandles::make_local (env, result); JVM_END
找到JVM_ENTRY和JVM_END这两个宏定义(interfaceSupport.hpp文件中)
1 2 3 4 5 6 7 8 9 #define JVM_ENTRY(result_type, header) \ extern "C" { \ result_type JNICALL header { \ JavaThread* thread=JavaThread::thread_from_jni_environment(env); \ ThreadInVMfromNative __tiv(thread); \ debug_only(VMNativeEntryWrapper __vew;) \ VM_ENTRY_BASE(result_type, header, thread) #define JVM_END } }
展开宏定义,就可以看到JVM_InternString的定义了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 extern "C" { jstring JNICALL JVM_InternString (JNIEnv *env, jstring str) { JavaThread* thread=JavaThread::thread_from_jni_environment (env); ThreadInVMfromNative __tiv(thread); debug_only (VMNativeEntryWrapper __vew;) VM_ENTRY_BASE (result_type, header, thread) JVMWrapper ("JVM_InternString" ); JvmtiVMObjectAllocEventCollector oam; if (str == NULL ) return NULL ; oop string = JNIHandles::resolve_non_null (str); oop result = StringTable::intern (string, CHECK_NULL); return (jstring) JNIHandles::make_local (env, result); } }
最关键的部分就是StringTable::intern方法,先让我们看一下StringTable类的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class StringTable : public Hashtable<oop, mtSymbol> { friend class VMStructs ; private : static StringTable* _the_table; static bool _needs_rehashing; static volatile int _parallel_claimed_idx; static oop intern (Handle string_or_null, jchar* chars, int length, TRAPS) oop basic_add (int index, Handle string_or_null, jchar* name, int len, unsigned int hashValue, TRAPS) oop lookup (int index, jchar* chars, int length, unsigned int hashValue) ; StringTable () : Hashtable <oop, mtSymbol>((int )StringTableSize, sizeof (HashtableEntry<oop, mtSymbol>)) {} StringTable (HashtableBucket<mtSymbol>* t, int number_of_entries) : Hashtable <oop, mtSymbol>((int )StringTableSize, sizeof (HashtableEntry<oop, mtSymbol>), t, number_of_entries) {} public : static StringTable* the_table () return _the_table; } static uint bucket_size () return sizeof (HashtableBucket<mtSymbol>); } static void create_table () assert (_the_table == NULL , "One string table allowed." ); _the_table = new StringTable (); } ... static oop lookup (Symbol* symbol) static oop lookup (jchar* chars, int length) static oop intern (Symbol* symbol, TRAPS) static oop intern (oop string, TRAPS) static oop intern (const char *utf8_string, TRAPS) ... }
从源码可以看出:StringTable也就是所谓的字符串常量池实际上就是一个Hashtable,而且被设计成单例,通过lookup()来查找元素,intern()方法来添加元素。
String类中的几个工具方法 对于String类中的许多成员方法,我们可能都非常熟悉。
substring获取子串(截取字符串中的一部分),包含start,不包含end。
startsWith和endsWidth来判断字符串头部和尾部的字符串
indexOf从前往后进行字符串匹配,lastIndexOf从后往前进行字符串匹配
trim去除字符串两端的空白字符(空格、换行等空白字符,即ASCII码0~32[空格])
split字符串切分
concat字符串连接,并返回一个新字符串,与C语言中的strcat函数类似
compareTo用于字符串之间的比较(该方法实现自Comparable接口),与C语言中的strcmp函数类似,按字母的编码顺序进行比较(字典序),如果大于传入的字符串则返回值大于0,如果相等则返回值等于0,如果小于传入的字符串则返回值小于0
equals用于比较字符串内容是否相同(该方法重写自Object类),相同返回true,不相同返回false
compareToIgnoreCase忽略大小写比较两个字符串
equalsIgnoreCase忽略大小写比较两字符串内容是否相同
contentEquals比较两个字符序列内容是否相同,传入参数只要是CharSequence接口的实现类即可
getBytes获取字符串编码的字节数组,可以指定字符集编码
toLowerCase转小写,toUpperCase转大写
replace和replaceAll用于替换子串(可以使用正则)
replaceFirst替换第一次出现(从前到后)的子串
matches字符串是否能匹配正则
…
上面的方法我们都经常使用,但是String类的一些静态方法可能会被我们忽略掉。
1 2 String format (String format, Object... args)
Java8中对StringBuilder类进行了一层封装——StringJoiner类,于是String类就多了个静态方法
StringJoiner类真的很“鸡肋”,主要是为了1.8提供的函数式编程而设计的。
1 2 String join (CharSequence delimiter, CharSequence... elements) String join (CharSequence delimiter, Iterable<? extends CharSequence> elements)
StringBuffer与StringBuilder 前面频繁提到了StringBuffer和StringBuilder这两个类,但很多初学者对这两个类区分不清:StringBuffer是线程安全的(方法基本上都是synchronized同步方法),StringBuilder是线程不安全的(没有使用synchronized进行同步);正因如此StringBuilder在效率上比StringBuffer要高 。这一点上和Vector与ArrayList的关系是一样的。
前面也提到Java中String的字符串连接就是使用StringBuilder实现的,但StringBuilder是Java5之后才添加的,在Java5之前都是使用StringBuffer类来实现的。Java中每次字符串连接都会重新创建一个StringBuilder类,所以不会出现多线程访问共享资源时发生的问题。
除了前面所说的StringBuffer与StringBuilder之间的区别比较重要外,它们的扩容策略也值得我们探究,这也可能会成为影响我们程序内存效率的因素。
它们的扩容策略是相同的
首先我们先看一下这两个类的构造方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public StringBuilder () { super (16 ); } public StringBuilder (int capacity) { super (capacity); } public StringBuilder (String str) { super (str.length() + 16 ); append(str); } public StringBuilder (CharSequence seq) { this (seq.length() + 16 ); append(seq); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public StringBuffer () { super (16 ); } public StringBuffer (int capacity) { super (capacity); } public StringBuffer (String str) { super (str.length() + 16 ); append(str); } public StringBuffer (CharSequence seq) { this (seq.length() + 16 ); append(seq); }
它们的构造方法完全一致。
我们能通过传入capacity来设置它的初始容量,如果不指定则默认为16(一个char占2字节,就相当于32个字节)。如果我们能大致确定要连接的字符数量,最好还是指定一下它的初始容量,这样可以避免频繁的创建新数组和数组拷贝。
这两个类的扩容策略是相同的,扩容策略的实现都被封装在它们的基类AbstractStringBuilder中:
1 2 3 4 5 6 7 8 9 10 11 12 void expandCapacity (int minimumCapacity) { int newCapacity = value.length * 2 + 2 ; if (newCapacity - minimumCapacity < 0 ) newCapacity = minimumCapacity; if (newCapacity < 0 ) { if (minimumCapacity < 0 ) throw new OutOfMemoryError (); newCapacity = Integer.MAX_VALUE; } value = Arrays.copyOf(value, newCapacity); }