压测节点拓扑图:
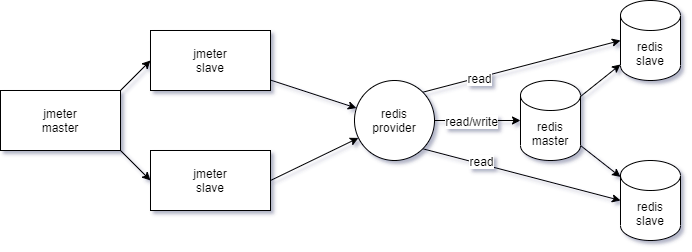
jmeter是三节点:每个节点都是默认的1500cpu,1.5G内存
redis-provider是一个转发redis请求的代理服务,配置为:3000cpu,1.5G内存
redis是RedisSentinel部署一主两从,版本为redis-5.0.7,只有主节点接受写。
jmeter压测监控
jmeter的监控线程从200逐渐增大到500,但是吞吐量并没有明显提升,响应时间也基本没有变化。从jmeter两个slave节点的监控可以看到,cpu和内存仍有很大空闲,吞吐量没有提升,说明下游有瓶颈。
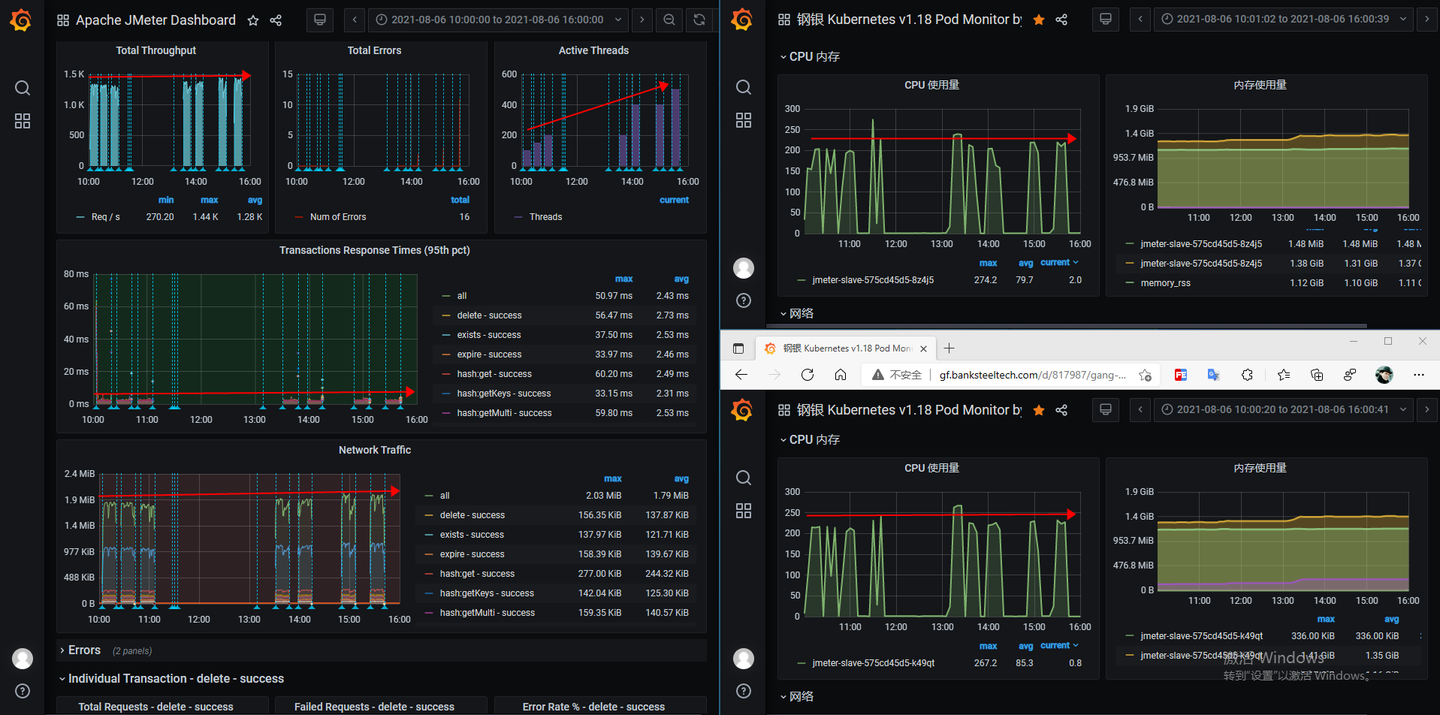
redis-provider服务监控
redis服务的cpu被提升到了3000,可以看到实际达到1500后就没有再增长了。jmeter的流量到redis-provider后cpu就压不上来了,说明cpu不是瓶颈,那就是I/O有瓶颈了,但是redis-provider服务的带宽远没有到顶。那说明下游的redis数据库有瓶颈。
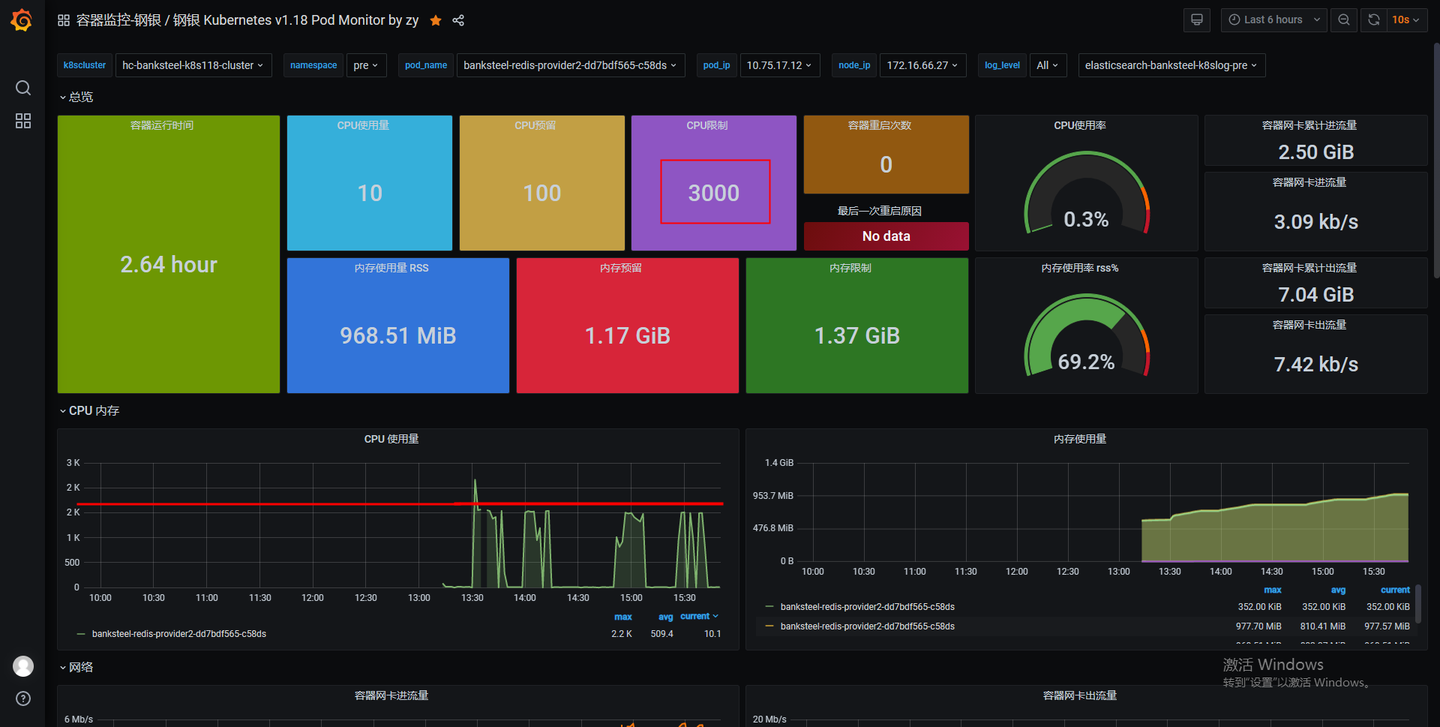
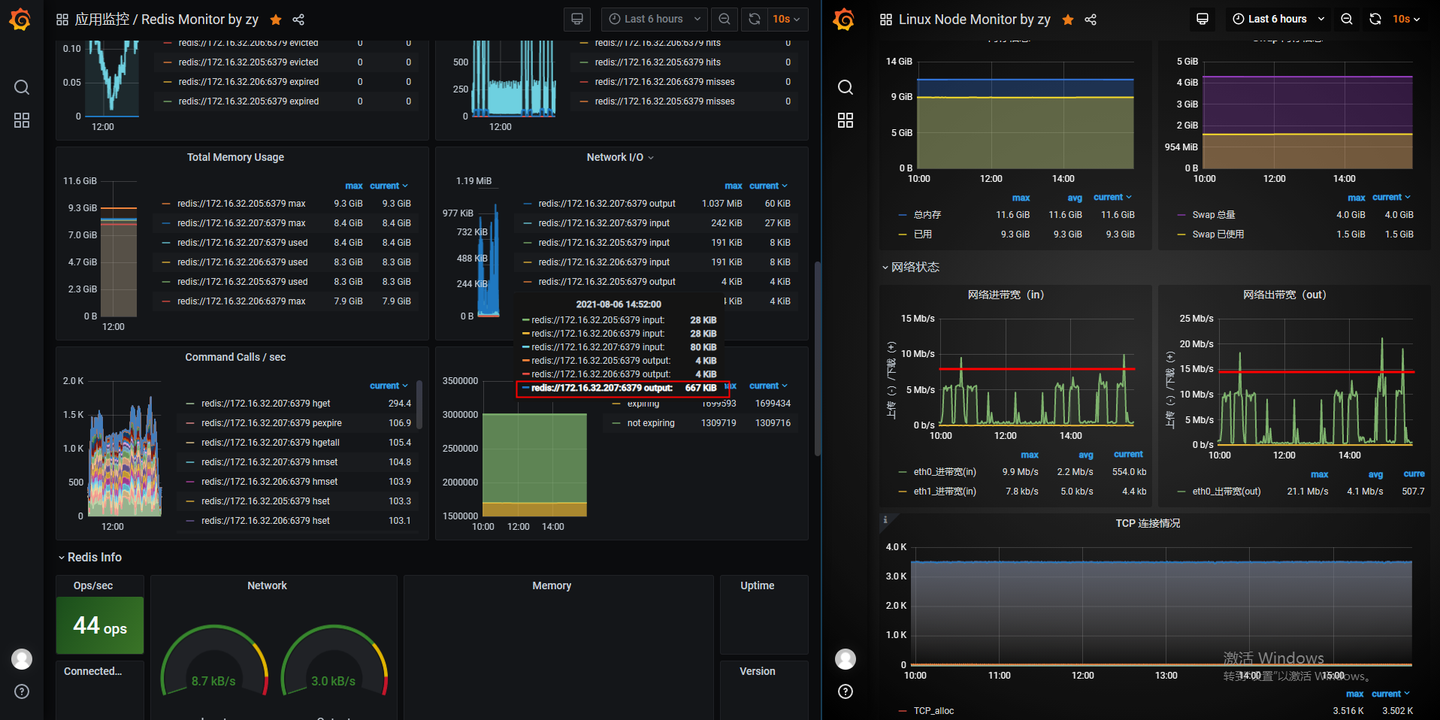
redis数据库的监控
可以看到redis的CPU每次压测调用虽然使用率上升了,但是仍有80%以上的CPU资源空闲着,说明cpu也不是redis的瓶颈,IO带宽也远没有打满。但是从系统监控中看到,redis的Context Switches有飙升,和压测节点的波形基本吻合,还有一点比较特别的是三台redis中,有一台redis每秒执行的命令数是另外两台的四倍。
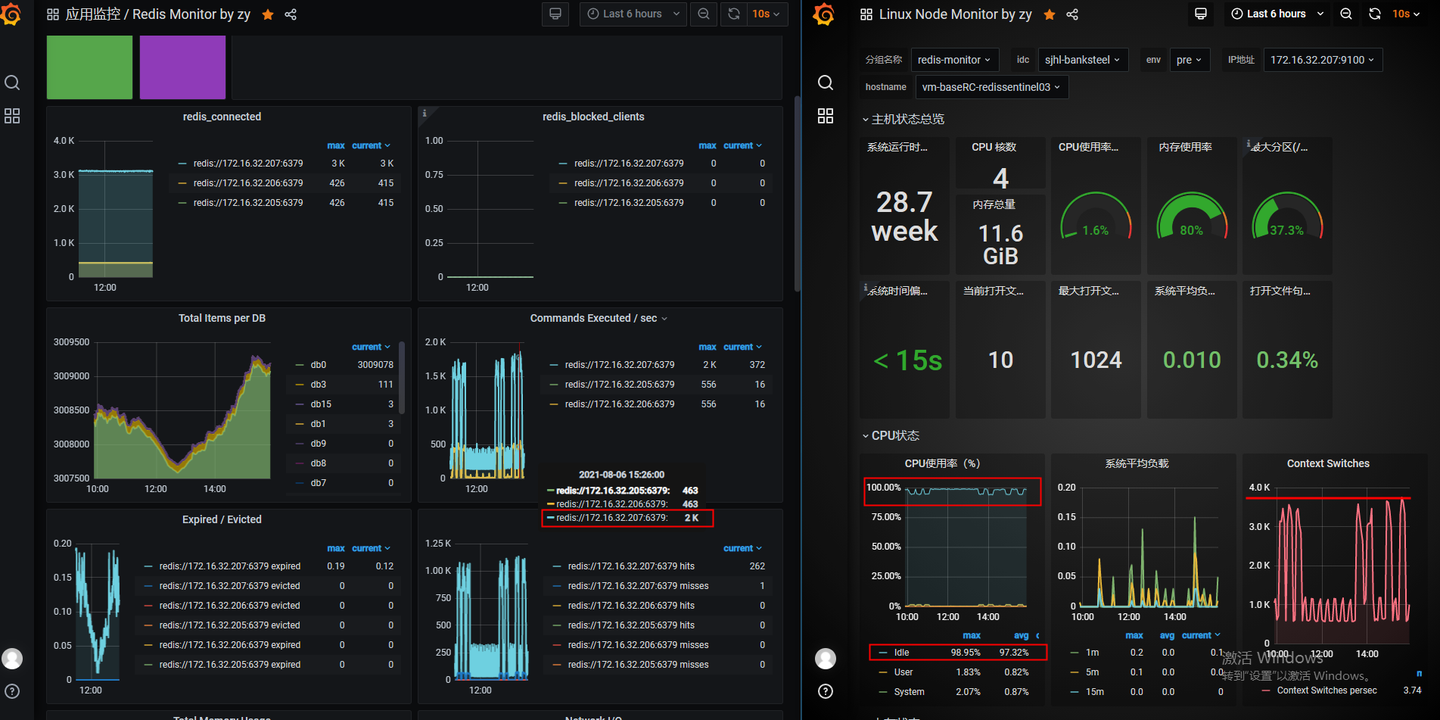
redis的context switches问题
原本以为context switches是线程切换导致的,但是redis使用的5.x版本仍然是单线程,6.x开始才支持multi-thread。在redis官网查了一下,context-switch是SocketIO每次调用read/write系统调用时内核态与用户态之间切换导致的。redis推荐用pipeline来减少SocketIO导致的IO性能影响。

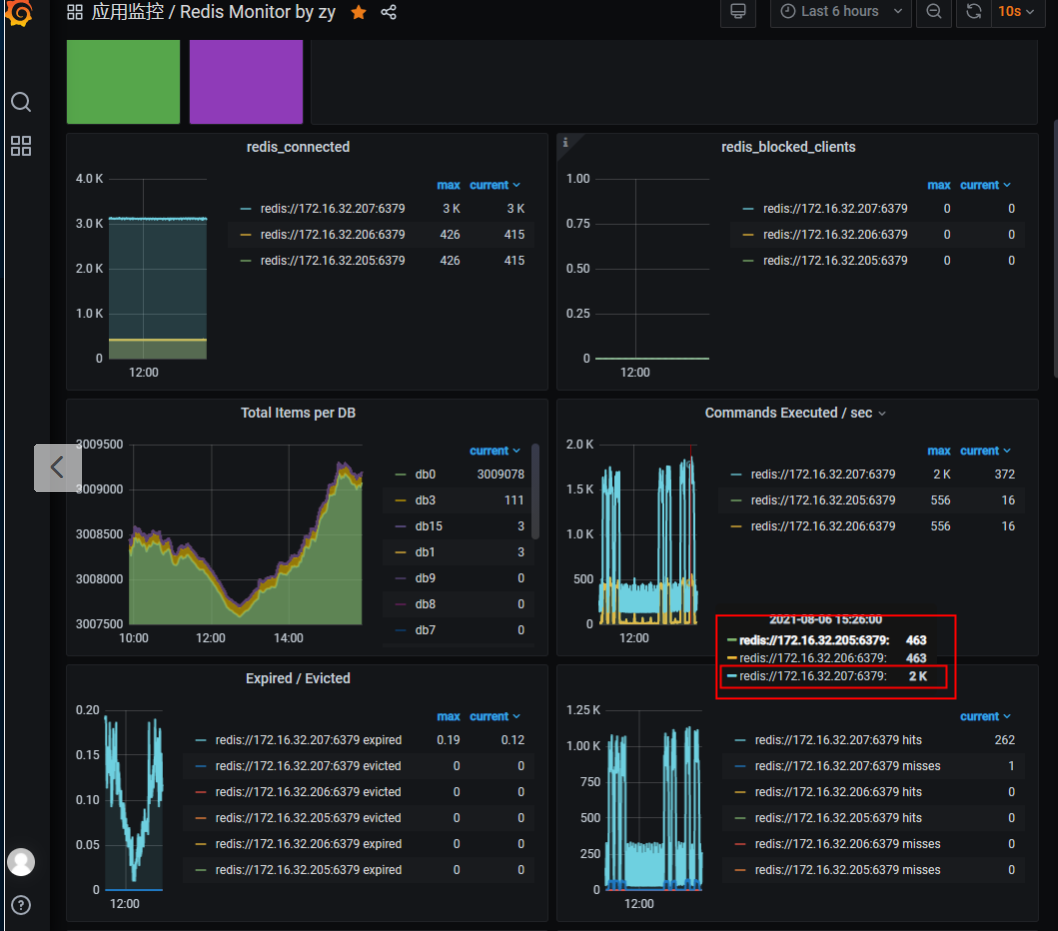
RedisSentinel主节点接受写
RedisSentinel是主从异步同步的,只有主节点能接受写操作,所有节点都能接受读操作,所以集群中主节点会接受更多的请求。
结论
redis-provider应用CPU在2000即可达到1.4K的吞吐量,CPU不是应用的瓶颈。redis数据库的瓶颈在于SocketIO的内核态与用户态的切换,以及RedisSentinel单个主节点接受写操作导致写入速度有瓶颈。

