这篇文章拆解自我的知乎回答:https://www.zhihu.com/question/451313635/answer/1849701932
有大佬说让我讲一讲消息系统,流批处理还有k8s调度,istio,这些我也还在学习中,我先挑一个稍微熟悉一点的消息系统讲一下吧,希望整理的过程中自己也能有些收获。有什么不对的地方希望路过的大佬指正。
在讲消息系统以前,先想象一下这个场景。
我是维护订单系统的几个服务,今天营销平台说让我在用户下单的时候调用一下他的服务,他好去对这部分下单用户进行一些营销动作,比如说这个用户下单了一个小时都还没付款需要发个短信提醒用户付款,明天又一个B平台的开发让我调用一下他的B服务,后天C平台的开发说调用他们的C服务的参数能不能改一下。
然后我就天天忙于他们的业务,自己头上的KPI却没有任何进展。而且因为同步调用他们的服务,导致用户下单的时候贼耗时,这些外部服务严重降低了用户下单时的体验,特别是营销平台的短信服务它还要调下游运营商的服务,这尼玛可拖累死我了。而且双十一大促的时候下单量猛增,我调用他们的服务时,他们的机器根本杠不住,直接把他们打挂了,导致自己订单服务经常抛异常。这尼玛自己的KPI没完成,还造成了性能问题,恐怕今年绩效的3.25我是背定了。
怎么办呢?想想这里面出现的几个问题:
1、我堂堂一个订单核心应用,竟然要依赖营销平台这样一个跟用户无关紧要的服务,这明显是不合理的,我要把这些无关紧要的服务用一个统一的方式处理掉,把那些无关紧要的代码从我的代码里通通干掉,让我的服务与这些服务进行解耦。
2、由于我一个一个地调用他们的服务,这种同步调用严重拖累了我自己的核心业务,所以如果能把这些调用转成异步调用就ok了。
3、这一到双十一,即使我用异步调用,调用量还是洪水滔天一样,他们处理不过来还是很难扛的住,大促一过呢一切又归于平静,他们的机器又闲的发慌。而且他们有些业务并没有很高的及时性要求,发个促销短信,发张优惠券,送个积分,慢一点又何妨。所以他们亟需一个削峰填谷的功能。
现在大家都知道消息队列可以解决这些问题。但是没有消息队列的时候,要怎么解决类似的问题呢?
我可以把下单消息存在数据库里,然后开一个异步Scheduler把这些消息发送给订阅了这个消息的订阅方。为了实现这个功能需要一张msg表存消息,还有一张subscriber表来记录每个订阅方的发送进度。有新的业务方需要我的下单数据,我只需要在subscriber表里添加一条记录,Scheduler会自动帮我把消息发给新的业务方,我终于可以高枕无忧了。
慢慢地,我发现这种基于消息的场景越来越多,其他团队也有这样的场景,要是能把这个逻辑单独拎出来就好了,于是消息队列的需求就出来了。
消息队列里经常把存储每种类型消息的队列称作一个topic,把存储消息的中间件叫做broker,所以加入消息队列后的结构就变成这样了。
设计这个消息队列的时候会碰到什么问题呢?
1、**producer->broker本质上就是一次RPC调用**:原来在同一个数据库的msg表被迁移到了broker上。在同一个数据库,我可以用本地事务保证我的消息一定持久化到数据库了,但是变成RPC调用后,消息可能会因为网络原因弄丢,或者因为网络超时,producer可以配置retries次数进行重试,当然重试也可能会导致消息重复(RPC会碰到的问题,消息队列也会碰到)。retries配置为0,也就意味着消息最多持久化一次(at most once),这个至多一次的概念划重点后面还会讲到。
2、消息机制被单独拎出来成了broker,那broker就得保证高可用,不然宕机了,下游的订阅方又是一阵骂娘。要保证高可用又涉及到数据复制了,kafka自带了topic级别的分区与复制功能,只需要将topic的replication设置成大于1的值,kafka就会帮你完成数据复制。
3、高可用集群里消息的持久化,一台机器数据落盘不一定可靠。producer发送消息给集群leader的时候,leader有可能还没来得及把数据复制给从节点就挂了,那这个消息就丢失了。为了解决这个问题,kafka给producer提供了acks参数:
- acks=0的时候,producer不会等待broker的确认,producer只要把数据扔进自己的socket缓冲区,他就认为成功了。这种情况producer的速度会很快,但是明显非常不可靠。
- acks=1的时候,producer发送给broker后,broker的leader只要将消息落盘了就会给producer返回ack响应。这种情况leader没来得及将数据复制给从节点就挂了,这个消息也就丢了。
- acks=-1或者acks=all的时候,broker收到消息后会等待集群中所有副本确认落盘了才会给producer返回ack响应。这种情况是最可靠的,当然效率也会更低。
4、acks=all能保证消息一定被broker集群持久化了,消息不会丢失。但是因为网络等种种原因producer可能没有收到ack确认,他为了保证可靠性就重试了,结果导致消息被broker集群持久化了多次。也就是说broker上的replication>1和producer的ack=-1只能保证消息至少保存了一次(at least once),但是无法保证只有一次exactly-once
前面讨论RPC的时候说过,为了防止接口重试产生的影响需要保证RPC接口的幂等,producer->broker也一样。所以Kafka 0.11.0引入了幂等的功能,Kafka会为每个Producer生成一个ProducerID,并为每条消息生成一个序列号,所以当broker收到同一个Producer发出的两条序列号相同的消息就不会再保存一遍了。而这个exactly-once是现代流系统精确性的必要条件。你想,如果你用事件流来实时统计双十一大盘上的销售额GMV,如果有重复消息不就相当于一笔订单统计了多次吗,那这几千亿的GMV水分就大了。
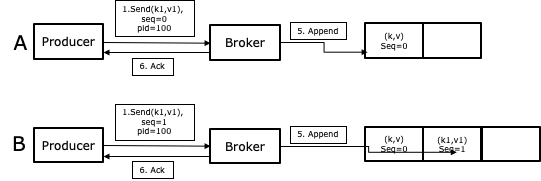
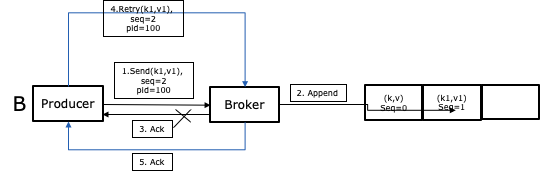
关于幂等的内容可以参考这篇文章:https://www.cnblogs.com/smartloli/p/11922639.html
5、消息的持久化问题与消息的堆积问题。我们开始设计的broker是基于数据库存储的,随着消息的增多,数据库B+树的深度就会增大,消息堆积的越多性能下降就越严重。阿里最早的notify消息队列是基于ActiveMQ设计的,Linkedin最早也是用ActiveMQ,都出现了这个问题,所以Linkedin开发了基于日志结构的Kafka,并且通过内存映射的方式大大提高了读写的速度,具体可以看Linkedin的这篇文章:The Log: What every software engineer should know about real-time data’s unifying abstraction。但Kafka的存储结构并不适用于阿里,所以阿里就基于Kafka开发了metaq(也就是开源的RocketMQ)。
Kafka主要问题在于:
Kafka每个topic会有若干个partition,每个partition就是一个文件,除此之外partition还有一个offset的索引文件,并且在1.0的时候又引入了基于timestamp的索引文件。topic越多,partition就越多,文件数就越多,一是消耗了过多的文件句柄,二是原本高性能的顺序写随着文件数的增多就变成了随机写。所以Kafka在topic数特别大的时候性能会急剧下降。
Kafka只能保证一个partition内的消息有序,如果topic有多个partition,就无法保证消息的有序性了,也就是说消息的有序性与多个partition带来的高吞吐量二者不可兼得。
关于阿里的metaq怎么解决这个问题,有兴趣的可以参考我的上一篇文章
6、消费完的消息怎么清理。如果是使用数据库存储,我们为了避免B+树深度的增大,肯定是需要开一个任务定时清理已经消费过的数据,B+树是对读性能优化的数据结构,对于增删操作多的写性能是很差的,这也是为什么kafka使用日志来存储消息的一个原因。同样的,kafka用日志存储也需要考虑到日志的清理,如果使用一个日志文件肯定是不方便的,所以kafka的日志除了分了partition,每个partition还分成了若干的segment。直接删除也就是把cleanup.policy设置成delete,根据消息的key对消息进行合并保留最新的一个消息就把cleanup.policy设置成compact。说到这个compact,再思考一个问题,因为基于append-only的日志存储,如果发了一条消息反悔了,想删除怎么办,kafka目前只提供了一个墓碑消息的概念,就是你发送一条消息体为null的消息并发消息的key设置成与之前消息key相同就行。

7、Pull or Push: Broker->Consumer是让Broker起一个Scheduler往Consumer推消息呢,还是让Consumer自己起一个Scheduler从Broker拉消息呢?这两者各有优缺点,让Broker实现Push方式可以保证消息的及时性,一旦有新的消息进来就可以立马推送给Consumer,但是如果Consumer消化不良就可能把Consumer给撑死。Consumer的Pull方式可以让Consumer根据自身需要自身控制消费速度,消费的实时性虽然有些影响,但是Consumer可以提高Pull频率达到自己预期的响应要求,当然提高Pull频率也就导致Broker压力增大,所以这个频率也需要平衡控制。Kafka的消费客户端就是基于Pull模式的。
8、Broker->Consumer消费过程中,Consumer可能会消费失败,或者消费超时,从而导致Consumer重复消费,所以同样地Consumer消费消息的时候仍要保证幂等。
9、一个topic可以由不同的Consumer订阅,Consumer为了提高消费速度可能会有多个线程甚至多台机器,所以就有了Consumer Group的概念。在Kafka中可以增多partition以提高消息的吞吐量,如果topic的partition数小于Consumer Group中的Consumer的个数时,肯定会有Consumer同时消费多个partition。
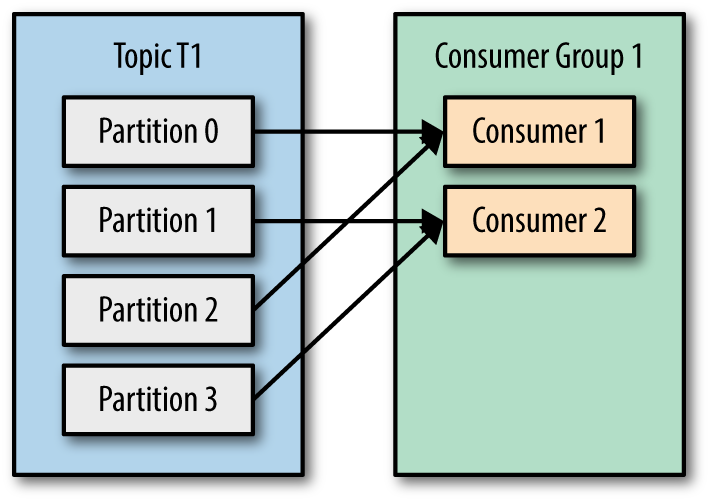
如果consumer数大于partition,kafka为了避免提交offset时出现争用导致不一致,就会有consumer空闲。
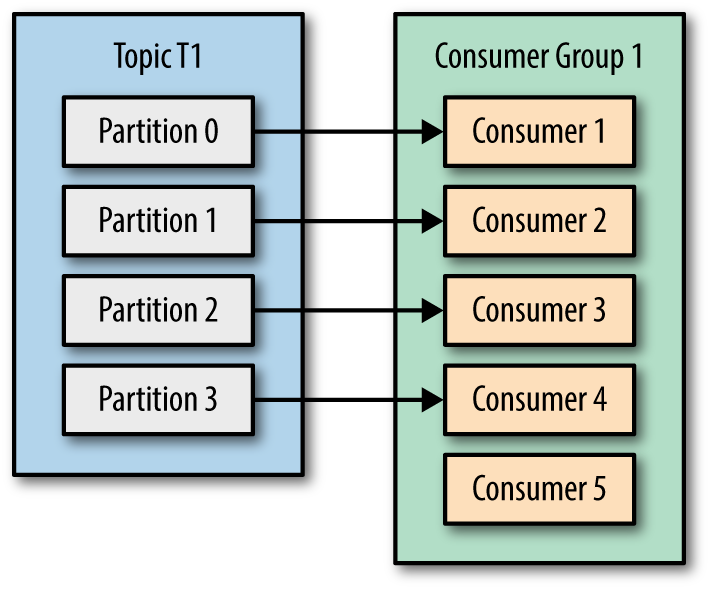
如果Consumer Group中有consumer挂了或者高负载导致心跳超时,将会导致Rebalance,重新调整partition的分配规则。
refs:
- https://github.com/akullpp/awesome-java#messaging
- https://laptrinhx.com/kafka-file-storage-mechanism-613781710/
- https://docs.confluent.io/cloud/current/client-apps/optimizing/index.html
- https://docs.confluent.io/cloud/current/client-apps/optimizing/throughput.html
- https://docs.confluent.io/platform/current/kafka/post-deployment.html#performance-tips
- 美团MQ设计概要:https://tech.meituan.com/2016/07/01/mq-design.html

