J2EE服务端开发编码问题主要集中在两个地方:JSP页面和Servlet程序。
JSP页面: 1 2 3 4 5 6 7 8 9 <%@ page contentType="text/html;charset=UTF-8" pageEncoding="UTF-8" language="java" %> <html > <head > <meta charset ="UTF-8" > <title > 编码问题</title > </head > <body > </body > </html >
JSP页面中有三个配置编码的地方,但这三个编码各自都有不同的作用。
1、pageEncoding="UTF-8":用于设置JSP文件的编码,JSP引擎会根据这个编码值来解析JSP文件并生成相应的Servlet,所以必须确保这个配置与JSP文件的编码一致,否则在JSP翻译成Servlet的过程中,JSP内的中文字符会被翻译成乱码。
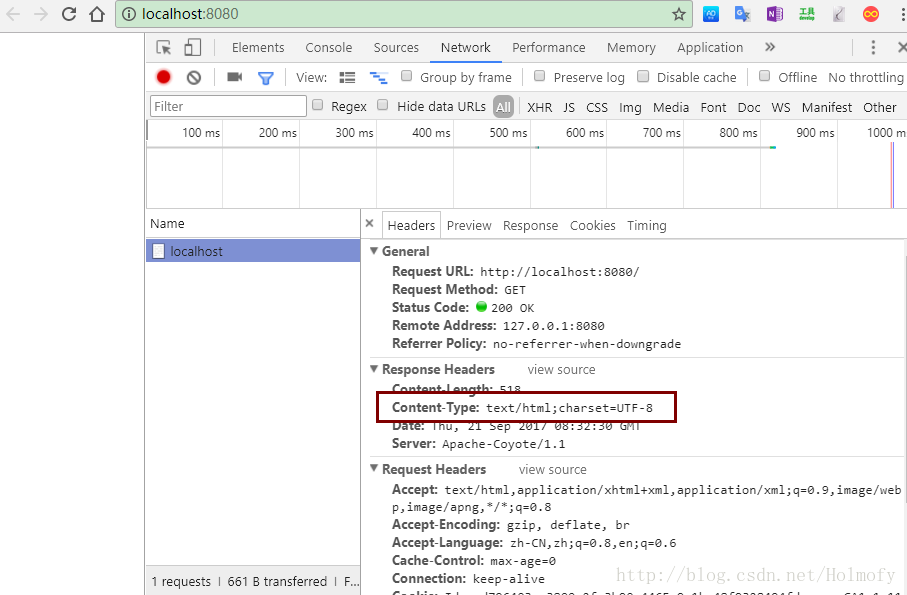
2、contentType="text/html;charset=UTF-8":这个配置会被设置到响应头中,也就是说由JSP生成的Servlet会调用response.setContentType()。客户端浏览器会根据这个配置来解析
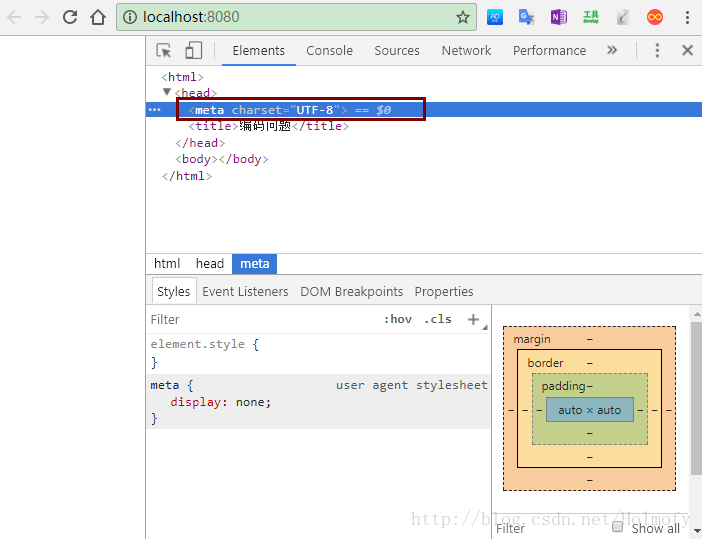
3、<meta charset="UTF-8">:这个是响应体的内容,作用和第二种一样。事实上这只是html5的写法,html4中常用的写法是<meta http-equiv="content-type" content="text/html; charset=UTF-8">。
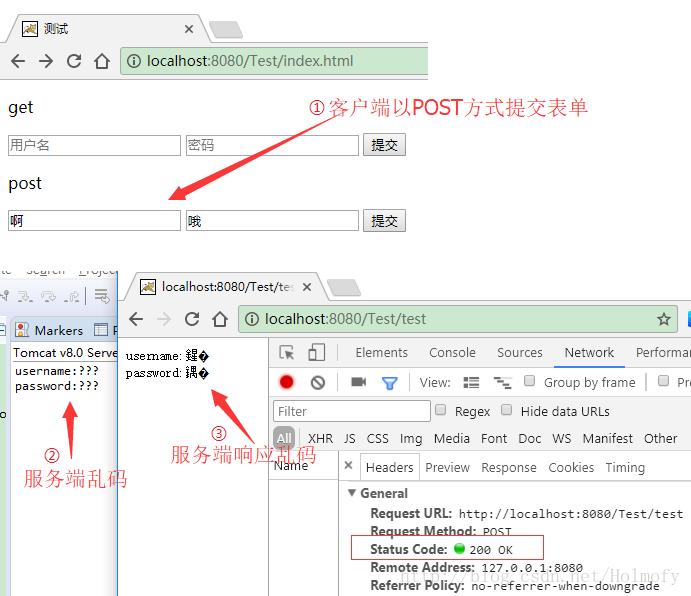
Servlet程序 Servlet程序中出现乱码主要出现在表单提交的时候。GET提交方式与POST提交方式出现乱码原因也各不相同。这里搞两个表单的html分别测试两种情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <!DOCTYPE html > <html > <head > <meta charset ="UTF-8" > <title > 编码问题</title > </head > <body > <p > get</p > <form action ="test" method ="get" > <input type ="text" name ="username" placeholder ="账号" > <input type ="text" name ="password" placeholder ="密码" > <input type ="submit" > </form > <p > post</p > <form action ="test" method ="post" > <input type ="text" name ="username" placeholder ="账号" > <input type ="text" name ="password" placeholder ="密码" > <input type ="submit" > </form > </body > </html >
测试get请求 先来测试get方式的请求:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class TestServlet extends HttpServlet { @Override protected void doGet (HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { String username = req.getParameter("username" ); String password = req.getParameter("password" ); System.out.println("username:" + username); System.out.println("password:" + password); PrintWriter writer = resp.getWriter(); writer.write("username:" + username + "\n" ); writer.write("password:" + password + "\n" ); } }
在web.xml中对Servlet进行相应配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <?xml version="1.0" encoding="UTF-8" ?> <web-app id ="test" version ="3.1" xmlns ="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd" > <servlet > <servlet-name > Test</servlet-name > <servlet-class > cn.hff.servlet.TestServlet</servlet-class > </servlet > <servlet-mapping > <servlet-name > Test</servlet-name > <url-pattern > /test</url-pattern > </servlet-mapping > </web-app >
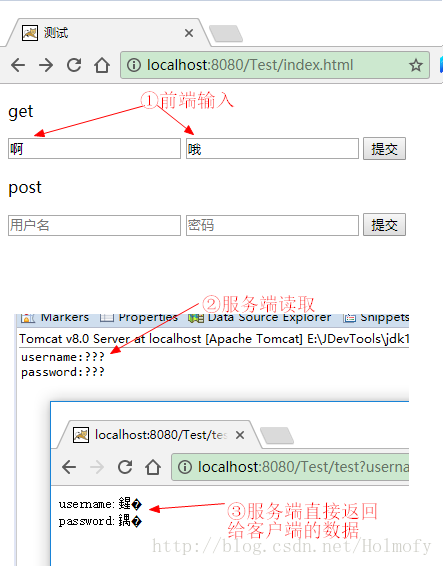
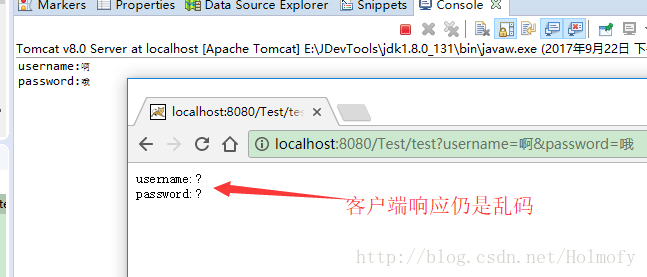
测试过程图如下(毫无疑问的出现了乱码,而且服务端乱码和客户端乱码还不一样):
GET请求的过程 在解决这个问题前我们再来熟悉一下GET请求的一些特点
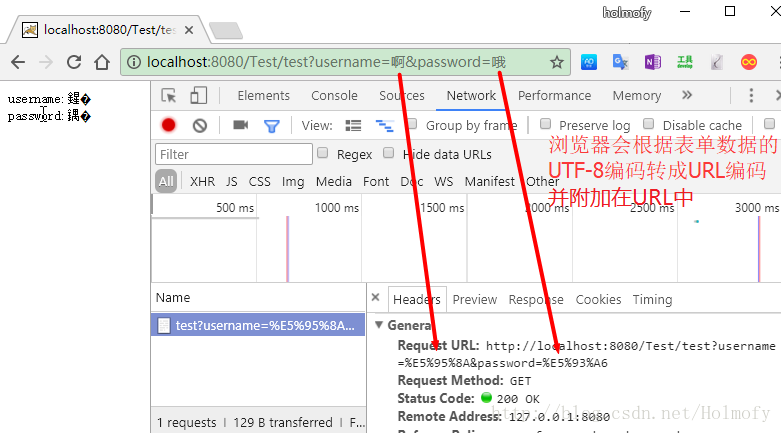
Tomcat8.0之前,默认使用ISO-8859-1编码(西欧8位字符集)去解析URI,所以这就导致使用request.getParameter读取乱码,这就是为什么控制台会打三个问号的原因。
为了解决这个问题我们需要修改Tomcat的conf/server.xml配置文件。找到HTTP/1.1的Connector配置:
1 <Connector URIEncoding ="ISO-8859-1" connectionTimeout ="20000" port ="8080" protocol ="HTTP/1.1" redirectPort ="8443" />
第一种方式 就是直接把URIEncoding修改成UTF-8:
1 <Connector URIEncoding ="UTF-8" connectionTimeout ="20000" port ="8080" protocol ="HTTP/1.1" redirectPort ="8443" />
事实上Tomcat8.0之后conf/server.xml中的默认URIEncoding就是UTF-8,这里我为了测试改成了Tomcat8.0之前的ISO-8859-1编码从ASCII、ISO-8859、GB2312、GBK到Unicode的UCS-2、UCS-4、UTF-8、UTF-16、UTF-32
第二种方式 是让URI的解码方式和请求体解码方式一致:
1 <Connector useBodyEncodingForURI ="true" connectionTimeout ="20000" port ="8080" protocol ="HTTP/1.1" redirectPort ="8443" />
同时我们需要在request.getParameter之前将请求体的解码方式设置为UTF-8:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Override protected void doGet (HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { req.setCharacterEncoding("UTF-8" ); String username = req.getParameter("username" ); String password = req.getParameter("password" ); System.out.println("username:" + username); System.out.println("password:" + password); PrintWriter writer = resp.getWriter(); writer.write("username:" + username + "\n" ); writer.write("password:" + password + "\n" ); }
官方文档 中建议使用第一种URIEncoding的方式。第二种配置方式主要为了兼容 Tomcat 4.1.x之前的版本。
服务端响应过程 进行上面的设置后,虽然服务端的乱码问题解决了,但客户端的响应仍然是乱码。
这是因为Tomcat的HTTP响应信息默认也是使用ISO-8859-1编码,我们需要在response.getWriter方法之前调用resp.setCharacterEncoding("UTF-8")将编码值设为UTF-8,同时我们要调用response.setContentType方法让客户端浏览器按照UTF-8的编码方式进行解析。
修改后的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Override protected void doGet (HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { String username = req.getParameter("username" ); String password = req.getParameter("password" ); System.out.println("username:" + username); System.out.println("password:" + password); resp.setCharacterEncoding("UTF-8" ); resp.setContentType("text/plain;charset=UTF-8" ); PrintWriter writer = resp.getWriter(); writer.write("username:" + username + "\n" ); writer.write("password:" + password + "\n" ); }
测试post请求 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class TestServlet extends HttpServlet { @Override protected void doPost (HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { String username = req.getParameter("username" ); String password = req.getParameter("password" ); System.out.println("username:" + username); System.out.println("password:" + password); PrintWriter writer = resp.getWriter(); writer.write("username:" + username + "\n" ); writer.write("password:" + password + "\n" ); } }
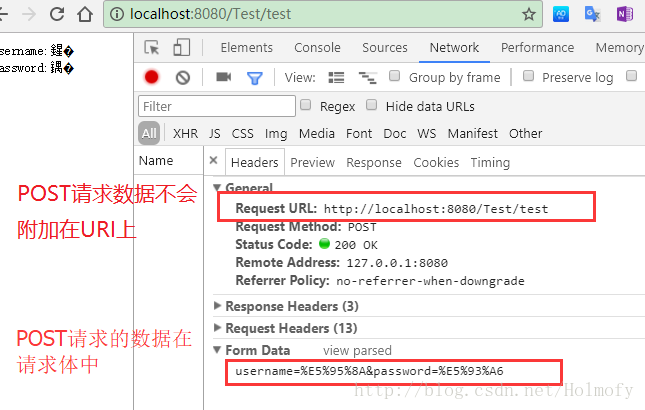
默认情况下和GET请求出现一样的乱码。
POST请求过程
和GET请求不同,POST请求的参数数据存放在请求体中,并没有附加在URI上,所以前面针对GET进行URI的配置就没必要了。因为数据存放在请求体中,所以我们可以直接调用request.setCharsetEncoding方法对请求体的解码方式进行设置:
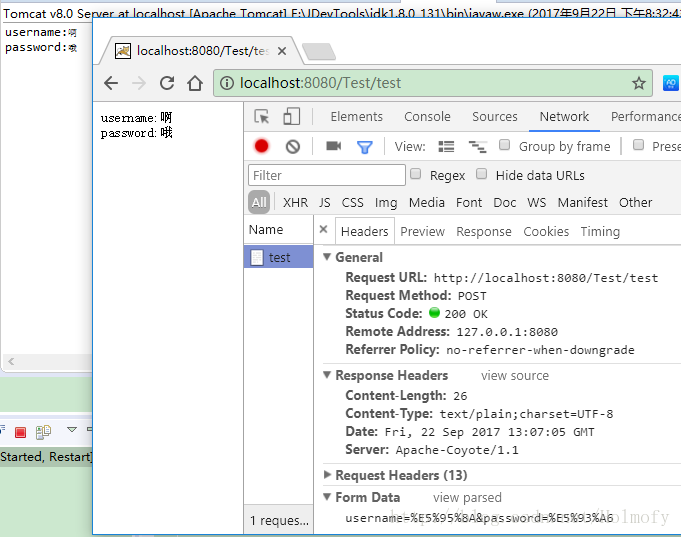
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Override protected void doPost (HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { req.setCharacterEncoding("UTF-8" ); String username = req.getParameter("username" ); String password = req.getParameter("password" ); System.out.println("username:" + username); System.out.println("password:" + password); resp.setCharacterEncoding("UTF-8" ); resp.setContentType("text/plain;charset=UTF-8" ); PrintWriter writer = resp.getWriter(); writer.write("username:" + username + "\n" ); writer.write("password:" + password + "\n" ); }
自定义过滤器设置编码 每个Servlet调用request.setCharacterEncoding确实很烦,最好的方式就是写一个Filter方便统一管理所有的编码。Filter代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package cn.hff.filter;public class UTF8EncodingFilter implements Filter { public void init (FilterConfig filterConfig) throws ServletException {} public void doFilter (ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException{ request.setCharacterEncoding("UTF-8" ); response.setCharacterEncoding("UTF-8" ); response.setContentType("text/html;charset=UTF-8" ); chain.doFilter(request, response); } public void destroy () {} }
然后在web.xml配置下过滤器:
1 2 3 4 5 6 7 8 9 10 11 12 13 <web-app > ... <filter > <filter-name > UTF8Filter</filter-name > <filter-class > cn.hff.filter.UTF8EncodingFilter</filter-class > </filter > <filter-mapping > <filter-name > UTF8Filter</filter-name > <url-pattern > /*</url-pattern > </filter-mapping > ... </web-app
使用Tomcat内建过滤器设置请求体编码 事实上Tomcat已经实现了上面的过滤器功能,而且过滤器的编码可以自行配置,使用时直接在web.xml中进行如下配置即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <web-app > ... <filter > <filter-name > RequestEncodingFilter</filter-name > <filter-class > org.apache.catalina.filters.SetCharacterEncodingFilter</filter-class > <init-param > <param-name > encoding</param-name > <param-value > UTF-8</param-value > </init-param > <async-supported > true</async-supported > </filter > <filter-mapping > <filter-name > RequestEncodingFilter</filter-name > <url-pattern > /*</url-pattern > </filter-mapping > ... </web-app >
Tomcat的SetCharacterEncodingFilter文档地址:http://tomcat.apache.org/tomcat-8.0-doc/config/filter.html#Set_Character_Encoding_Filter
Tomcat相关源码分析 通过源码看Tomcat解析请求参数的过程
以下源码出自apache-tomcat-8.0.36-src,该版本源码可以从这里下载 ,不同版本可能略有差异
请求参数处理相关源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 package org.apache.catalina.connector;... public class RequestFacade implements HttpServletRequest { ... protected Request request = null ; @Override public String getParameter (String name) { ... return request.getParameter(name); } @Override public void setCharacterEncoding (String env) throws java.io.UnsupportedEncodingException { if (request == null ) { throw new IllegalStateException ( sm.getString("requestFacade.nullRequest" )); } request.setCharacterEncoding(env); } } package org.apache.catalina.connector;... public class Request implements HttpServletRequest { ... @Override public String getParameter (String name) { if (!parametersParsed) { parseParameters(); } return coyoteRequest.getParameters().getParameter(name); } protected void parseParameters () { parametersParsed = true ; Parameters parameters = coyoteRequest.getParameters(); boolean success = false ; try { parameters.setLimit(getConnector().getMaxParameterCount()); String enc = getCharacterEncoding(); boolean useBodyEncodingForURI = connector.getUseBodyEncodingForURI(); if (enc != null ) { parameters.setEncoding(enc); if (useBodyEncodingForURI) { parameters.setQueryStringEncoding(enc); } } else { parameters.setEncoding (org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING); if (useBodyEncodingForURI) { parameters.setQueryStringEncoding (org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING); } } parameters.handleQueryParameters(); ... } @Override public void setCharacterEncoding (String enc) throws UnsupportedEncodingException { if (usingReader) { return ; } B2CConverter.getCharset(enc); coyoteRequest.setCharacterEncoding(enc); } @Override public String getCharacterEncoding () { return coyoteRequest.getCharacterEncoding(); } } package org.apache.tomcat.util.http;... public final class Parameters { public void handleQueryParameters () { if ( didQueryParameters ) { return ; } didQueryParameters=true ; ... try { decodedQuery.duplicate( queryMB ); } catch (IOException e) { e.printStackTrace(); } processParameters( decodedQuery, queryStringEncoding ); } public void processParameters ( MessageBytes data, String encoding ) { if ( data==null || data.isNull() || data.getLength() <= 0 ) { return ; } if ( data.getType() != MessageBytes.T_BYTES ) { data.toBytes(); } ByteChunk bc=data.getByteChunk(); processParameters( bc.getBytes(), bc.getOffset(), bc.getLength(), getCharset(encoding)); } private static final Charset DEFAULT_CHARSET = StandardCharsets.ISO_8859_1; private Charset getCharset (String encoding) { if (encoding == null ) { return DEFAULT_CHARSET; } try { return B2CConverter.getCharset(encoding); } catch (UnsupportedEncodingException e) { return DEFAULT_CHARSET; } } private void processParameters (byte bytes[], int start, int len, Charset charset) { ... int decodeFailCount = 0 ; int pos = start; int end = start + len; while (pos < end) { int nameStart = pos,nameEnd = -1 ,valueStart = -1 ,valueEnd = -1 ; boolean parsingName = true ; boolean decodeName = false ; boolean decodeValue = false ; boolean parameterComplete = false ; do { switch (bytes[pos]) { case '=' : if (parsingName) { nameEnd = pos; parsingName = false ; valueStart = ++pos; } else { pos++; } break ; case '&' : if (parsingName) { nameEnd = pos; } else { valueEnd = pos; } parameterComplete = true ; pos++; break ; case '%' : case '+' : if (parsingName) { decodeName = true ; } else { decodeValue = true ; } pos ++; break ; default : pos ++; break ; } } while (!parameterComplete && pos < end); ... tmpName.setBytes(bytes, nameStart, nameEnd - nameStart); if (valueStart >= 0 ) { tmpValue.setBytes(bytes, valueStart, valueEnd - valueStart); } else { tmpValue.setBytes(bytes, 0 , 0 ); } ... try { String name; String value; if (decodeName) { urlDecode(tmpName); } tmpName.setCharset(charset); name = tmpName.toString(); if (valueStart >= 0 ) { if (decodeValue) { urlDecode(tmpValue); } tmpValue.setCharset(charset); value = tmpValue.toString(); } else { value = "" ; } try { addParameter(name, value); } catch (IllegalStateException ise) { ... } } catch (IOException e) { } tmpName.recycle(); tmpValue.recycle(); ... } ... }
响应体相关源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package org.apache.catalina.connector;... public class Response implements HttpServletResponse { public void setCharacterEncoding (String charset) { if (isCommitted()) { return ; } if (included) { return ; } if (usingWriter) { return ; } getCoyoteResponse().setCharacterEncoding(charset); isCharacterEncodingSet = true ; } public String getCharacterEncoding () { return (getCoyoteResponse().getCharacterEncoding()); } public PrintWriter getWriter () throws IOException { ... if (ENFORCE_ENCODING_IN_GET_WRITER) { setCharacterEncoding(getCharacterEncoding()); } usingWriter = true ; outputBuffer.checkConverter(); if (writer == null ) { writer = new CoyoteWriter (outputBuffer); } return writer; } }