系列文章:
- Java多线程复习与巩固(一)–线程基本使用
- Java多线程复习与巩固(二)–线程相关工具类的使用
- Java多线程复习与巩固(三)–线程同步
- Java多线程复习与巩固(四)–synchronized的实现
- Java多线程复习与巩固(五)–生产者消费者问题(第一部分)
- Java多线程复习与巩固(六)–线程池ThreadPoolExecutor详解
- Java多线程复习与巩固(七)–任务调度线程池ScheduledThreadPoolExecutor
- Java多线程复习与巩固(八)–原子性操作与原子变量
- Java多线程复习与巩固(九)–volatile关键字与CAS操作
- ThreadPoolExecutor最佳实践–如何选择线程数
- ThreadPoolExecutor最佳实践–如何选择队列
前面讲线程同步时,我们对多线程容易出现的问题进行了分析,在那个例子中,问题的根源在于c++和c--这两个操作在底层处理的时候被分成了若干步执行。当时我们用的是synchronized关键字来解决这个问题,而从synchronize的实现原理中我们知道synchronized通过monitor监视器来实现线程同步,这种同步方式要求线程等待monitor的拥有者线程释放后,才可能进一步执行,而线程等待可能会导致**线程上下文的切换(Context Switch)**,线程上下文的切换会带来极大的开销:保存和恢复线程当前的执行状态(如程序计数器,线程执行栈等)。这片文章中我们使用另一种方式来解决前面提出的多线程问题。
使用原子操作来解决多线程的问题
先贴出代码:
1 | import java.util.concurrent.atomic.AtomicInteger; |
程序运行结果:
1 | 0 |
上面代码中使用了java.util.concurrent.atomic包中的一个类**AtomicInteger**,使用的是类中的getAndIncrement和getAndDecrement方法,这两个方法类似于之前例子中的c++,c--操作。
AtomicInteger是对int类型的封装,**AtomicInteger类中的方法能保证对内存中的int值的操作都是原子性的**,换句话说就能保证一个线程在对int操作的过程中不会被另一个线程打断,从而使得两个线程不会发生前面文章中出现的指令交叉执行的现象。
对于单处理机CPU来说,原子操作指的是一个不会被“线程调度机制”打断的操作,这种操作一旦开始,就一直占用CPU直到操作结束,中间不会有任何上下文切换(context switch,切换到另外的进程或线程)。
对于多处理机CPU来说,原子操作不仅仅具有前面的那些性质,还应包括“在一个处理机上的操作不会受其他处理机的影响”这一特性,比如说一个处理机修改内存的时候另一个处理机不能修改内存。
java.util.concurrent.atomic包
像AtomicInteger这样的类还有很多,它们都在java.util.concurrent.atomic包中,这些类都是无锁的、线程安全的。
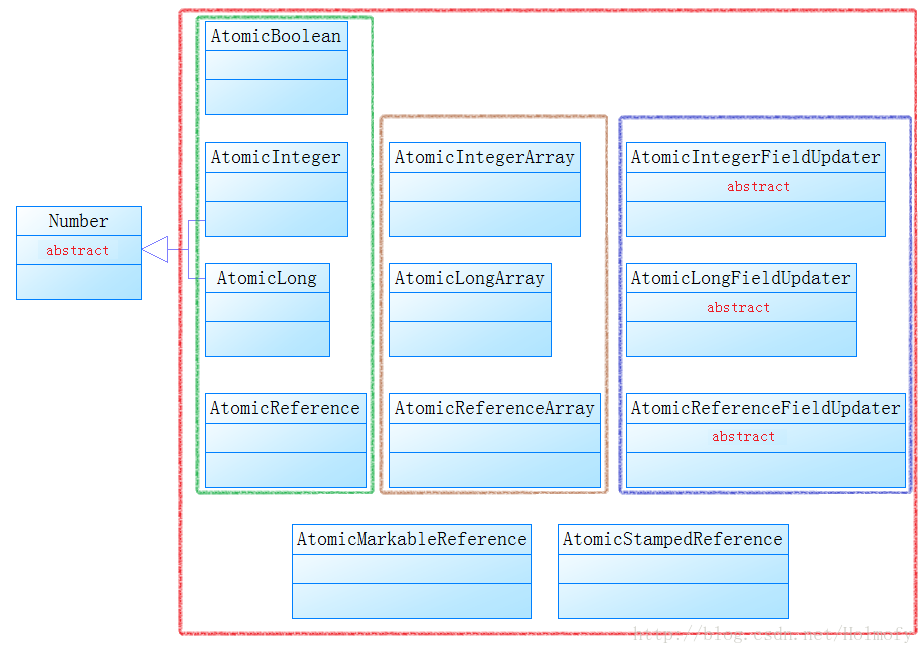
从功能上来说,上面这些类主要分为以下几种:
1. 单一值原子性封装
AtomicBoolean、AtomicInteger、AtomicLong、AtomicReference是对volatile修饰的单一值进行封装。
由于**volatile关键字只能保证多线程读取(get)、写入(set)操作的一致性,但不能保证多线程修改操作(++,–等操作)的原子性**。但AtomicInteger和AtomicLong类内部使用CAS操作保证了getAndIncrement(i++),getAndDecrement(i–),incrementAndGet(++i),decrementAndGet(–i)等这类操作的原子性。
特别地,AtomicBoolean底层使用int存储,用1表示true,用0表示false,因为在Java中boolean类型的字节长度是不确定的,单个的boolean编译时会被映射为int类型,boolean数组编译时才会被映射为byte类型的数组。用1表示true,用0表示false。
JDK没有提供byte、short、float、double、char的包装类,Java官方文档给出的建议是使用已有的AtomicInteger和AtomicLong来自己实现相应的包装类。比如:
- 用
AtomicInteger来存储byte数据,进行相应的强制转换即可; - 用
AtomicInteger来存储float数据,并使用Float.floatToRawIntBits(float)和Float.intBitsToFloat(int)方法进行转换; - 用
AtomicLong来存储double数据,并使用Double.doubleToRawLongBits(double)和Double.longBitsToDouble(long)进行转换。
Demo:
1 | import java.util.concurrent.atomic.AtomicInteger; |
Guava的
com.google.common.util.concurrent.AtomicDouble包有这些扩展类的实现,
如AtomicDouble、AtomicDoubleArray
2. 数组值原子性封装
AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray是对数组类型的值进行原子性操作的封装。
这三个类在方法中多传入一个索引作为参数来访问数组中的元素,
AtomicIntegerArray使用int[]存储,AtomicLongArray使用long[]存储,AtomicReferenceArray使用T[]泛型数组存储。
3. 对象字段原子性封装
AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater是对类对象的某个字段进行原子操作。
这三个类都是抽象类,但是它们都提供了一个工厂方法newUpdater(Class<U> tclass, String fieldName)来创建内部实现类的实例。
这三个类主要用在已经封装好的类,我们无法对这个类的代码进行修改,但是却要保证里面某些字段的操作是原子性的。
4. 对象标志原子性封装
AtomicMarkableReference、AtomicStampedReference是对AtomicReference类的扩展。
这两个类的区别在于AtomicMarkableReference使用boolean与引用类型的值进行关联,这个布尔值用来标识这个引用对象是否被;而AtomicStampedReference使用integer与引用类型的值进行关联,你可以使用这个integer代表引用数据更新的版本数值。
下一篇文章讲CAS操作的ABA问题时会提到这两个类的用处
下面的代码是JDK1.8中AtomicMarkableReference、AtomicStampedReference的部分代码(1.8之前实现有所不同):
1 | public class AtomicMarkableReference<V> { |
在Java1.8中还增加了
DoubleAccumulator、DoubleAdder、LongAccumulator、LongAdder这四个类用于并发累积计数。

