系列文章:
前篇:《Java多线程复习与巩固(六)–线程池ThreadPoolExecutor详解》
1. 为什么要使用ScheduledThreadPoolExecutor 在《Java多线程复习与巩固(二)–线程相关工具类Timer和ThreadLocal的使用》 提到过,Timer可以实现指定延时调度任务 ,还可以实现任务的周期性执行 。但是Timer中的所有任务都是由一个TimerThread执行,也就是说Timer是单线程 执行任务。单线程执行任务有一个致命的缺点:当某些任务的执行特别耗时,后续的任务无法在预定的时间内得到执行,前一个任务的延迟或异常将影响到后续的任务;另外TimerThread没有做异常处理,一个任务出现异常将会导致整个Timer线程结束 。
由于Timer单线程的种种缺点,这个时候我们就需要让线程池去执行这些任务。
2. 使用Executors工具类 Executors是线程池框架提供给我们的创建线程池的工具类,FixedThreadPool,SingleThreadExecutor,CachedThreadPool都是上一篇文章中的ThreadPoolExecutor对象 。
他还有另外两个方法:
1 2 3 4 5 public static ScheduledExecutorService newScheduledThreadPool () ;public static ScheduledExecutorService newSingleThreadScheduledExecutor () ;
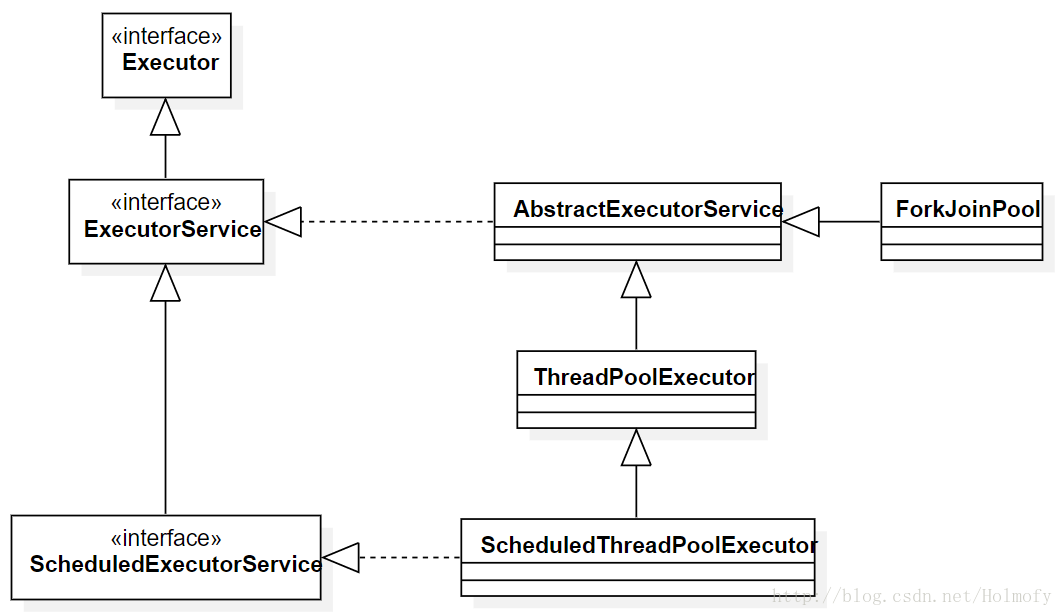
从下面的继承图我们知道ScheduledThreadPoolExecutor就是ScheduledExecutorService接口的实现类。
3. 构造ScheduledThreadPoolExecutor对象 先看一下ScheduledThreadPoolExecutor的几个构造函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class ScheduledThreadPoolExecutor extends ThreadPoolExecutor implements ScheduledExecutorService { ... public ScheduledThreadPoolExecutor (int corePoolSize) { super (corePoolSize, Integer.MAX_VALUE, 0 , NANOSECONDS, new DelayedWorkQueue ()); } public ScheduledThreadPoolExecutor (int corePoolSize, ThreadFactory threadFactory) { super (corePoolSize, Integer.MAX_VALUE, 0 , NANOSECONDS, new DelayedWorkQueue (), threadFactory); } public ScheduledThreadPoolExecutor (int corePoolSize, RejectedExecutionHandler handler) { super (corePoolSize, Integer.MAX_VALUE, 0 , NANOSECONDS, new DelayedWorkQueue (), handler); } public ScheduledThreadPoolExecutor (int corePoolSize, ThreadFactory threadFactory, RejectedExecutionHandler handler) { super (corePoolSize, Integer.MAX_VALUE, 0 , NANOSECONDS, new DelayedWorkQueue (), threadFactory, handler); } ... }
从上面的代码可以看出ScheduledThreadPoolExecutor都是直接调用的父类ThreadPoolExecutor的构造函数。
我们结合上一篇对ThreadPoolExecutor构造参数的解释 对ScheduledThreadPoolExecutor的几个参数进行分析,主要有以下几个参数比较特殊:
maximumPoolSize:线程池允许的最大线程数为Integer.MAX_VALUE,也就意味着ScheduledThreadPoolExecutor对线程数没有限制。这个是必须的,因为一旦对线程数有了限制,必定会存在任务等待调度的情况,有等待就可能会存在任务延时,所以最大线程数不能有限制。 keepAliveTime和unit:0 NANOSECONDS,0纳秒,也就是说一旦有空闲线程会立即销毁该线程对象。 workQueue:DelayedWorkQueue是ScheduledThreadPoolExecutor的内部类,它也是实现按时调度的核心。 4. 二叉堆DelayedWorkQueue DelayedWorkQueue和java.util.concurrent.DelayQueue有着惊人的相似度:
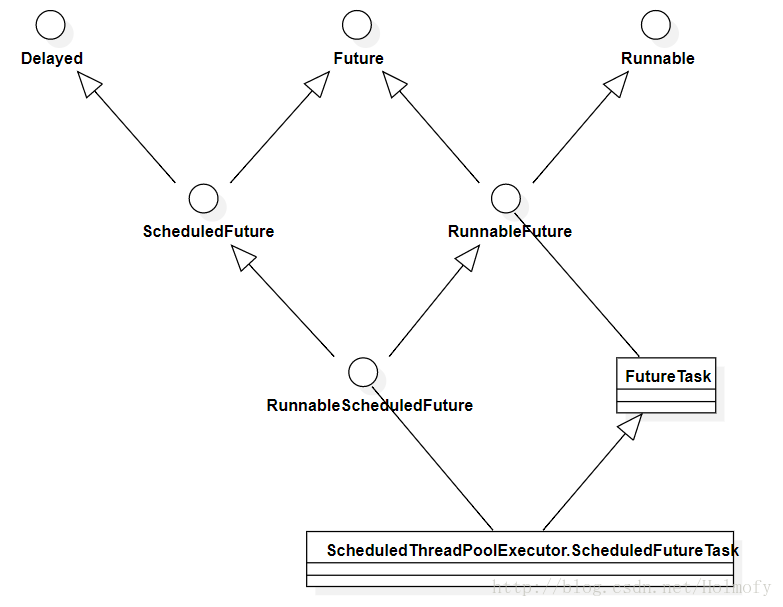
DelayedWorkQueue实现了一个容量无限的二叉堆,DelayQueue底层使用PriorityQueue实现二叉堆各种操作。 DelayedWorkQueue存储了java.util.concurrent.RunnableScheduledFuture接口的实现类,DelayQueue存储java.util.concurrent.Delayed接口的实现类,这两个接口有以下的继承关系(其中ScheduledThreadPoolExecutor内部类ScheduledFutureTask就实现了RunnableScheduledFuture接口)
5. 为什么使用二叉堆 大学学过数据结构的应该学过堆排序吧:堆排序就是用小顶堆(或大顶堆)实现最小(或最大)的元素往堆顶移动。这里的DelayedWorkQueue就是使用二叉堆获取堆中延时最短的任务 。具体的比较策略让我们看下面这个方法:
ScheduledThreadPoolExecutor.ScheduledFutureTask.compareTo()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public int compareTo (Delayed other) { if (other == this ) return 0 ; if (other instanceof ScheduledFutureTask) { ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other; long diff = time - x.time; if (diff < 0 ) return -1 ; else if (diff > 0 ) return 1 ; else if (sequenceNumber < x.sequenceNumber) return -1 ; else return 1 ; } long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS); return (diff < 0 ) ? -1 : (diff > 0 ) ? 1 : 0 ; }
6. 为什么不用DelayQueue的二叉堆实现 java.util.concurrent.DelayQueue就是根据延时获取元素的,那为什么不直接用DalayQueue而重新定义一个DelayedWorkQueue呢。这个问题本质上就是在问DelayQueue与DelayedWorkQueue的区别,我们看一下DelayedWorkQueue注释中的一段话:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 static class DelayedWorkQueue extends AbstractQueue <Runnable> implements BlockingQueue <Runnable> { ... }
大致翻译过来:
1 2 3 4 5 6 7 8 9 10 DelayedWorkQueue类似于DelayQueue和PriorityQueue,是基于“堆”的一种数据结构。 区别就在于ScheduledFutureTask记录了它在堆数组中的索引,这个索引的好处就在于: 取消任务时不再需要从数组中查找任务,极大的加速了remove操作,时间复杂度从O(n)降低到了O(log n), 同时不用等到元素上升至堆顶再清除从而降低了垃圾残留时间。 但是由于DelayedWorkQueue持有的是RunnableScheduledFuture接口引用而不是ScheduledFutureTask的引用, 所以不能保证索引可用,不可用时将会降级到线性查找算法(我们预测大多数任务不会被包装修饰,因此速度更快的情况更为常见)。 所有的堆操作必须记录索引的变化 ————主要集中在siftUp和siftDown两个方法中。一个任务删除后他的headIndex会被置为-1 。 注意每个ScheduledFutureTask在队列中最多出现一次(对于其他类型的任务或者队列不一定只出现一次), 所以可以通过heapIndex进行唯一标识。
这里有几个地方可能有疑问:
1. remove操作的时间复杂度从O(n)降低到了O(log n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public boolean remove (Object x) { final ReentrantLock lock = this .lock; lock.lock(); try { int i = indexOf(x); if (i < 0 ) return false ; setIndex(queue[i], -1 ); int s = --size; RunnableScheduledFuture<?> replacement = queue[s]; queue[s] = null ; if (s != i) { siftDown(i, replacement); if (queue[i] == replacement) siftUp(i, replacement); } return true ; } finally { lock.unlock(); } } private int indexOf (Object x) { if (x != null ) { if (x instanceof ScheduledFutureTask) { int i = ((ScheduledFutureTask) x).heapIndex; if (i >= 0 && i < size && queue[i] == x) return i; } else { for (int i = 0 ; i < size; i++) if (x.equals(queue[i])) return i; } } return -1 ; }
2. 任务的包装修饰
包装修饰主要是指两个ScheduledThreadPoolExecutor.decorateTask方法。这部分内容放在文末“扩展ScheduledThreadPoolExecutor的功能”时讲。
7. 任务的提交 1 2 3 4 5 6 7 8 9 10 11 12 public void execute (Runnable command) { schedule(command, 0 , NANOSECONDS); } public Future<?> submit(Runnable task) { return schedule(task, 0 , NANOSECONDS); } public <T> Future<T> submit (Runnable task, T result) { return schedule(Executors.callable(task, result), 0 , NANOSECONDS); } public <T> Future<T> submit (Callable<T> task) { return schedule(task, 0 , NANOSECONDS); }
我们看到原来ThreadPoolExecutor中的几个提交方法都被重写了,最终调用了个的都是schedule方法,并且这几个方法的延时都为0纳秒。
8. schedule 既然前面任务的提交全部都是交给schedule方法执行,那么让我们看一下schedule相关的几个方法
下面的几个方法也是ScheduledExecutorService接口扩展的几个方法
下面需要注意的主要是scheduleAtFixedRate和scheduleWithFixedDelay两个方法的区别 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 private long triggerTime (long delay, TimeUnit unit) { return triggerTime(unit.toNanos((delay < 0 ) ? 0 : delay)); } long triggerTime (long delay) { return now() + ((delay < (Long.MAX_VALUE >> 1 )) ? delay : overflowFree(delay)); } public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) { if (command == null || unit == null ) throw new NullPointerException (); RunnableScheduledFuture<?> t = decorateTask(command, new ScheduledFutureTask <Void>(command, null , triggerTime(delay, unit))); delayedExecute(t); return t; } public <V> ScheduledFuture<V> schedule (Callable<V> callable, long delay, TimeUnit unit) { if (callable == null || unit == null ) throw new NullPointerException (); RunnableScheduledFuture<V> t = decorateTask(callable, new ScheduledFutureTask <V>(callable, triggerTime(delay, unit))); delayedExecute(t); return t; } public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) { if (command == null || unit == null ) throw new NullPointerException (); if (period <= 0 ) throw new IllegalArgumentException (); ScheduledFutureTask<Void> sft = new ScheduledFutureTask <Void>(command, null , triggerTime(initialDelay, unit), unit.toNanos(period)); RunnableScheduledFuture<Void> t = decorateTask(command, sft); sft.outerTask = t; delayedExecute(t); return t; } public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit) { if (command == null || unit == null ) throw new NullPointerException (); if (delay <= 0 ) throw new IllegalArgumentException (); ScheduledFutureTask<Void> sft = new ScheduledFutureTask <Void>(command, null , triggerTime(initialDelay, unit), unit.toNanos(-delay)); RunnableScheduledFuture<Void> t = decorateTask(command, sft); sft.outerTask = t; delayedExecute(t); return t; } protected <V> RunnableScheduledFuture<V> decorateTask ( Runnable runnable, RunnableScheduledFuture<V> task) { return task; } protected <V> RunnableScheduledFuture<V> decorateTask ( Callable<V> callable, RunnableScheduledFuture<V> task) { return task; }
总结来说就是fixRate是以任务开始时间计算间隔,而fixDelay是以任务结束时间计算间隔 。
9. delayedExecute 上面的几个方法都是将runnable或callable包装成ScheduledFutureTask对象,最终都是丢给delayedExecute方法去执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 private void delayedExecute (RunnableScheduledFuture<?> task) { if (isShutdown()) reject(task); else { super .getQueue().add(task); if (isShutdown() && !canRunInCurrentRunState(task.isPeriodic()) && remove(task)) task.cancel(false ); else ensurePrestart(); } } void ensurePrestart () { int wc = workerCountOf(ctl.get()); if (wc < corePoolSize) addWorker(null , true ); else if (wc == 0 ) addWorker(null , false ); }
10. ScheduledFutureTask.run 添加线程后,线程肯定会从阻塞队列中获取任务,并执行任务的run方法,也就是ScheduledFutureTask的run方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private class ScheduledFutureTask <V> extends FutureTask <V> implements RunnableScheduledFuture <V> { ... public void run () { boolean periodic = isPeriodic(); if (!canRunInCurrentRunState(periodic)) cancel(false ); else if (!periodic) ScheduledFutureTask.super .run(); else if (ScheduledFutureTask.super .runAndReset()) { setNextRunTime(); reExecutePeriodic(outerTask); } } private void setNextRunTime () { long p = period; if (p > 0 ) time += p; else time = triggerTime(-p); } }
11. ScheduledThreadPoolExecutor的其他配置项 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class ScheduledThreadPoolExecutor extends ThreadPoolExecutor implements ScheduledExecutorService { private volatile boolean continueExistingPeriodicTasksAfterShutdown; private volatile boolean executeExistingDelayedTasksAfterShutdown = true ; private volatile boolean removeOnCancel = false ; }
12. 继承ScheduledThreadPoolExecutor对任务进行包装 ThreadPoolExecutor提供了beforeExecute,afterExecute,terminated三个钩子方法让我们重载以进行扩展。
ScheduledThreadPoolExecutor也提供了两个方法给我们扩展,下面是JDK文档提供的一个简单例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class CustomScheduledExecutor extends ScheduledThreadPoolExecutor { static class CustomTask <V> implements RunnableScheduledFuture <V> { ... } protected <V> RunnableScheduledFuture<V> decorateTask ( Runnable r, RunnableScheduledFuture<V> task) { return new CustomTask <V>(r, task); } protected <V> RunnableScheduledFuture<V> decorateTask ( Callable<V> c, RunnableScheduledFuture<V> task) { return new CustomTask <V>(c, task); } }
13. ScheduledThreadPoolExecutor尚有的缺点 ScheduledThreadPoolExecutor是使用纳秒为单位进行任务调度,它底层使用的是System.nanoTime()来获取时间:
1 2 3 final long now () { return System.nanoTime(); }
这个时间是相对于JVM虚拟机启动的时间,这个纳秒值在$2^{63}纳秒 \approx 292年$后会溢出(几乎可以忽略溢出问题),ScheduledThreadPoolExecutor也对溢出进行了处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 long triggerTime (long delay) { return now() + ((delay < (Long.MAX_VALUE >> 1 )) ? delay : overflowFree(delay)); } private long overflowFree (long delay) { Delayed head = (Delayed) super .getQueue().peek(); if (head != null ) { long headDelay = head.getDelay(NANOSECONDS); if (headDelay < 0 && (delay - headDelay < 0 )) delay = Long.MAX_VALUE + headDelay; } return delay; }
既然ScheduledThreadPoolExecutor已经处理了,那还有什么问题吗。问题就在于我们无法使用yyyy-MM-dd HH-mm-ss这种精确时间点 的方式进行任务的调度。
不过在SpringTask Quartz cron表达式 来精确任务的调度时间。后续如果有机会对这些框架的原理进行分析。
SpringTask既可以单独使用也可以整合Quartz使用,除了Quartz还有一个轻量级的Cron4j 可以实现任务调度,不过Cron4j并没有用线程池(估计那时候java5还没出来),每个任务都会去创建一个新线程。