如何把长期记忆(Long-term Memory)里的东西,精准、少量、不污染地提取到上下文(短期记忆)中?
这件事是 整个 AI 系统是否可靠的决定性因素。
换句话说:
Agent能不能聪明,除了取决于模型参数,更取决于“有没有把对的东西放进上下文”。
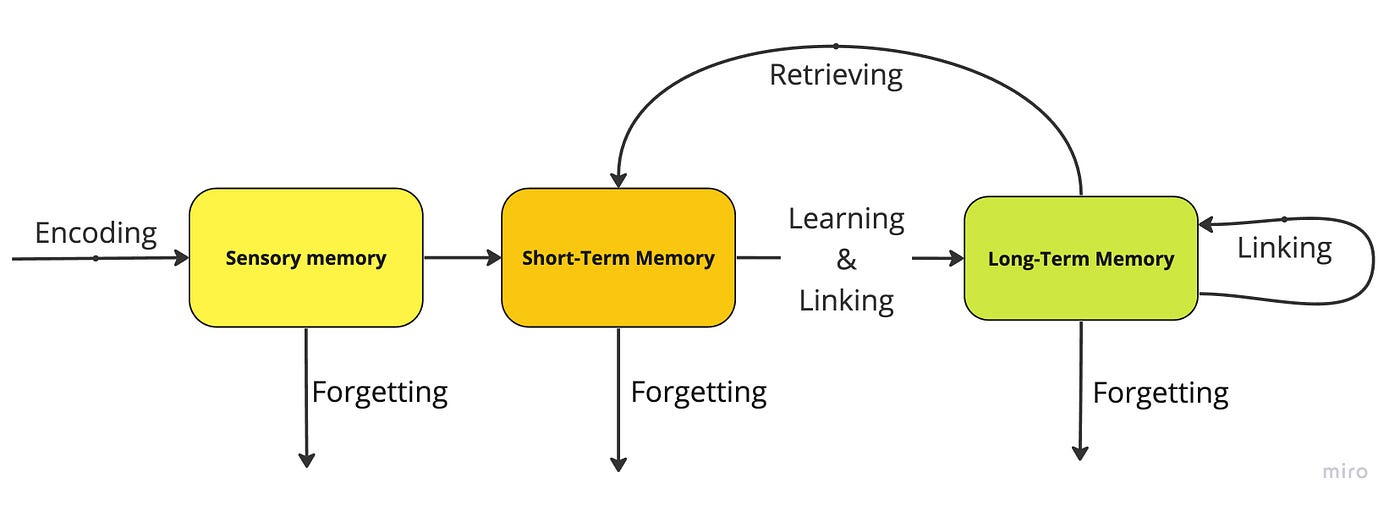
1. 上下文 = 工作记忆(短期)
- 容量有限
- 容易被噪音干扰
- 内容过多会导致幻觉
- 每轮对话都会刷新或丢失
就像人类的“意识层”。
🗂️ 2. 长期记忆 = 外部知识库(Long-term Memory)
可能包含:
- 文档
- 代码
- embeddings
- Skills(能力型记忆)
- 用户偏好
- 历史任务
- 系统状态
- 动态数据库数据
容量巨大,可无限扩展,就像人的“潜意识 + 已学习的知识与经验”。
3. 真正的难点:
如何从无限大的长期记忆中,取出最 relevant 的小片段加载到有限上下文中?
这是整个 AI 体系最关键的问题,因为:
- 太少 → 信息不足,模型做不出好判断
- 太多 → 上下文爆掉,出现幻觉
- 提取错了 → 直接跑偏
- 噪音太多 → 严重干扰 reasoning
“提取什么”比“模型怎么推理”更重要。
AI记忆系统的设计是一个重大课题
研究界和工业界对这个问题有几个不同方向的研究,你可以看到它们非常核心:
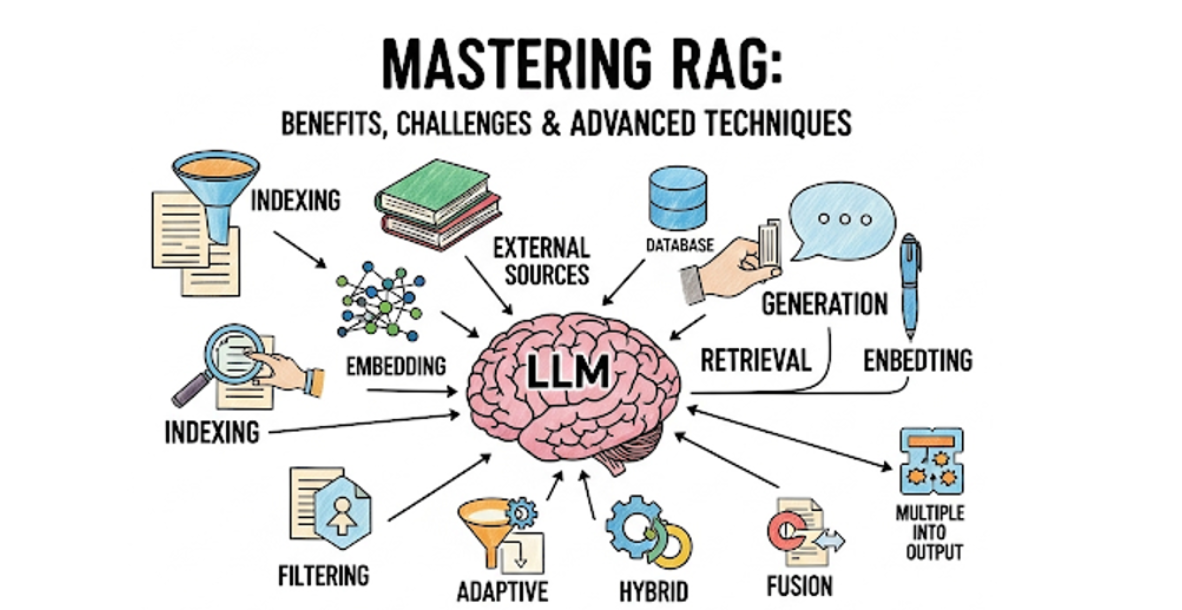
① Retrieval(检索)
也就是传统的 RAG。
问题在于:
- 文档颗粒度怎么切?
- 如何避免召回噪音?
- 多轮任务上下文如何保持一致性?
- 如何做 hierarchical retrieval?
这已经是一个大课题。
② Routing(路由)
即:
给定长期记忆,我们应该让哪个 Agent 或 Skill 上场?
这是 Multi-Agent System 的另一个根本难题。
Routing 不好 → Agent 用不对的信息、做不对的事。
③ Memory Ranking(记忆排序)
系统要决定:
- 哪些信息最重要?
- 哪些信息应该遗忘?
- 哪些技能应该更优先?
- 哪些历史内容应该合并成总结?
这其实是“AI 大脑的注意力系统”。
④ Context Compression(上下文压缩)
包括:
- 压缩句子
- 压缩任务状态
- 压缩之前 agent 的决策链
比如:
- ReAct traces
- 思维链(CoT)
- Agent state
这些不能无限增长,需要压缩,不然会爆。
⑤ Memory Rewriting(记忆重写)
类似人类会“总结成脑内模型”:
- 动态总结
- 抽象
- 合并
- 提炼为新技能(Skill)
这其实是 AI 的“学习过程”。
未来最强的 AI 可能是:
通过 Memory Rewriting 持续把经验写成 Skills 的系统
⑥ Grounding(事实校验)
避免幻觉最关键的一步:
- 提取到上下文的内容是否真实?
- 是否对应正确来源?
- 是否经过验证?
美国大厂内部都在研究“Retrieval → Grounding → Reasoning”三段式 pipeline。
总结
未来所有强 AI 系统的核心都不是模型本身,而是:
如何管理记忆 → 如何提取记忆 → 如何在短期记忆中构建思考链条。
这就是 AI 的“前额叶皮层 + 海马体”类比。
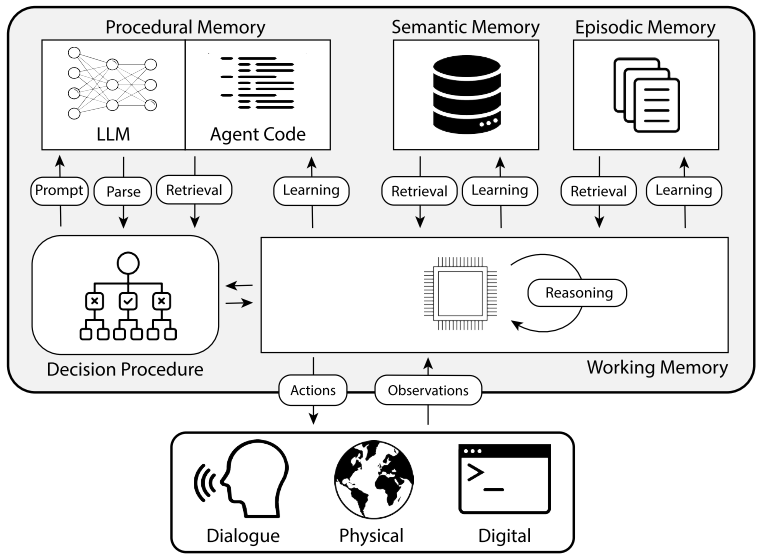
- 工作记忆(上下文)= 前额叶皮层 = 推理区
- 长期记忆(RAG/Skills/知识库)= 海马体 + 大脑皮层
- 检索模块 = 注意力系统
- 压缩与抽象模块 = 人类的梦境与学习过程
AI 的智能 = 模型能力 × 上下文质量 × 记忆检索质量

