2025年结束,过去一年里,AI火爆的一批。从开年梁文峰深度求索的DeepSeek爆火,再到Cursor / Claude Code这种AI编码工具出现,真的颠覆了程序员的三观。AI终于从只会聊天的机器人,变成了能真正赋能工作的生产力工具。而这都归功于AI Agent,所以2025年也被称为AI Agent元年。
年底的时候姚顺雨入职腾讯的事儿爆火了,回国前他写了篇《The Second Half》(中文版:AI进入下半场)。
看了一下他的几篇论文,ToT思维树: 利用大型语言模型进行有意识的问题解决和ReAct Agent架构(中文版:LLM Agent 的开山之作)最具影响力。其中ReAct是Prompt工程时代的“分水岭论文”,也是Agent时代的“理论起点”。
这篇文章我记录一下我对AI Agent的一些思考和代码实践。
AI Agent = LLM 作为决策器(Planner) + 工具执行循环(Act Loop)
AI本质是基于统计的经验主义的概率模型
1. 数据的“炼金术”:词嵌入 (Word Embeddings)
AI 并不认识“苹果”或“开心”这些词。在它的世界里,一切都是数字。
- 向量空间: AI 会把每一个词转化成一串长长的数字坐标(向量)。
- 语义相近: 在这个高维空间里,“猫”和“狗”的坐标离得很近,而“猫”和“手机”就离得很远。
- 逻辑运算: 著名的例子是:$国王 - 男人 + 女人 = 女王$。AI 通过这种数学关系来理解人类世界的逻辑。
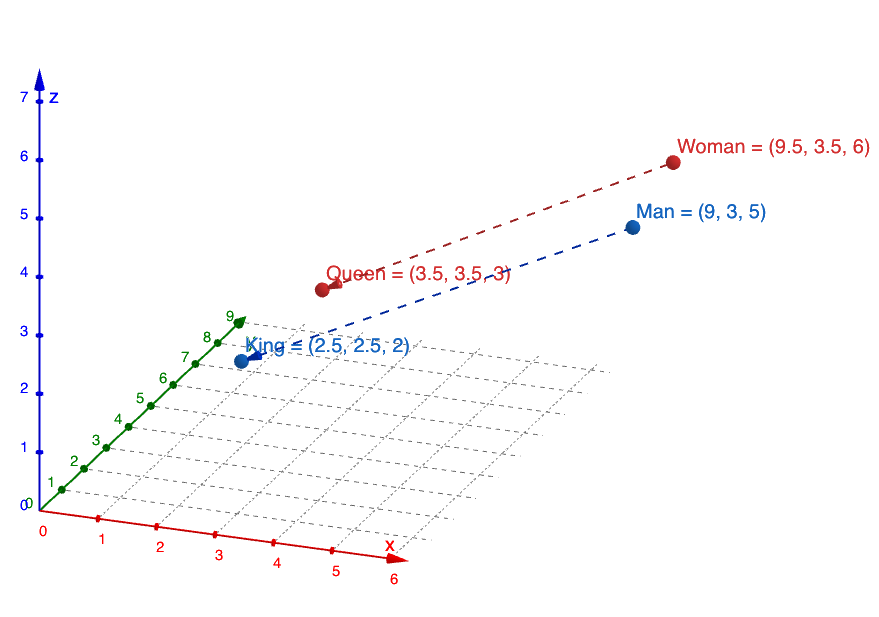
只不过这个向量是在高维空间中表示,比如常见的预训练模型:
- BERT-base: 768 维
- BERT-large: 1024 维
- BGE-small (v1.5): 384 维
- BGE-base (v1.5): 768 维
- BGE-large (v1.5/M3): 1024 维
- GPT的text-embedding-ada-002: 1536 维
- GPT的text-embedding-3-large: 3072 维
既然是“炼金术”,训练模型的数据质量也决定了模型的智能程度,也就是计算机领域常说的“Garbage in, Garbage out”。DeepSeek训练成本低的原因出了极其省钱的架构 (MLA/MoE)和极致的硬件压榨,还有关键的一点是高质量数据。这就像从小看名著长大的小孩和从小看言情小说爽文长大的小孩,自然思考能力差距很大。你用知乎或者维基百科等语料数据训练出来的模型输出的都是结构化表达、知识科普、多角度分析,你用微博、抖音等语料数据训练出来的模型输出的都是情绪偏见、互联网流行梗。。。
2. 核心引擎:Transformer 架构与注意力机制
2017 年 Google 提出的Transformer是现在所有大模型的基石。
- 注意力机制 (Attention): 当 AI 读到“他把苹果给了小明,因为它熟透了”时,它能精准地通过“注意力”判断出“它”指代的是“苹果”而不是“小明”。
- 并行处理: 以前的 AI 是一字一句读,现在的 AI 是把整篇文章“瞬间”吞下,同时分析所有词与词之间的联系。
3. 本质:超级“接龙”游戏
不管外表看起来多么像人类,AI 的底层逻辑始终是预测概率。
- 概率预测: 当你问“今天天气”,AI 并不是在“思考”,而是在计算:在“今天天气”后面,出现“不错”的概率是 80%,出现“火星”的概率是 0.001%。
- 涌现能力: 当模型规模大到一定程度(比如几千亿个参数)时,这种简单的“接龙”突然表现出了推理、编程、甚至幽默感。科学家管这叫“涌现”(Emergence)。用通俗的话说就是“读书百遍,其义自见”
AI 工作流程 = 将文字变数字 → 在高维空间找关系 → 计算下一个字出现的最高概率。
ReAct
现在的大模型更像是一个知识渊博的学者,他读了全世界文档、书籍、论文,但是大模型的知识只停留在训练完成前采集的数据,没有新的数据喂给他。
所以在此之前大模型的方向是通过RAG去检索外部的文档数据,这在之前的一篇文章中有过记录。RAG就是在模型生成答案前,先从外部系统检索相关知识,再把这些知识作为上下文交给模型生成回答返回给用户。
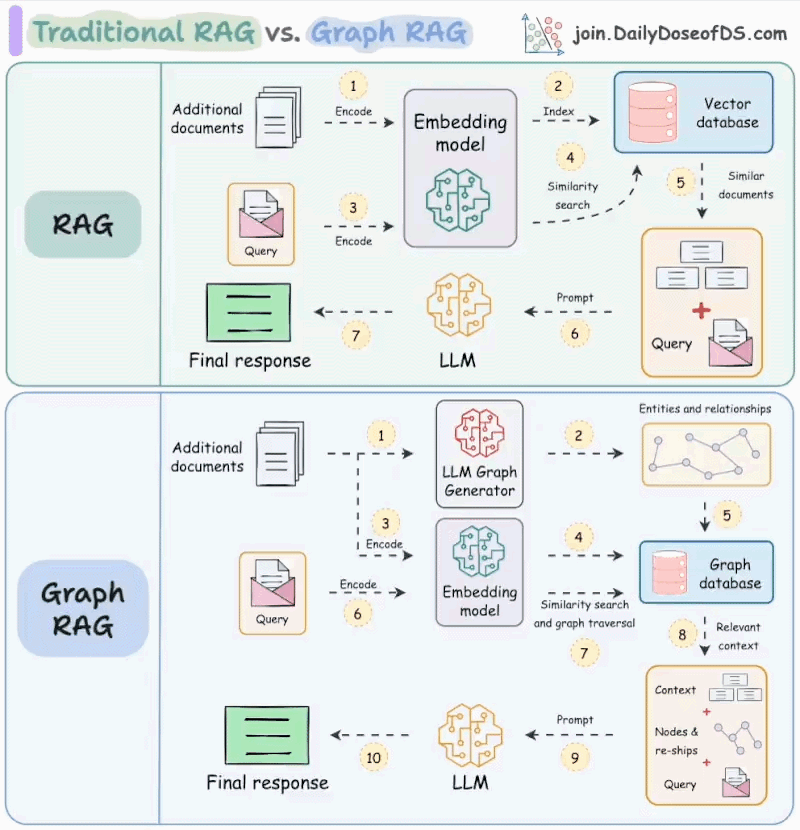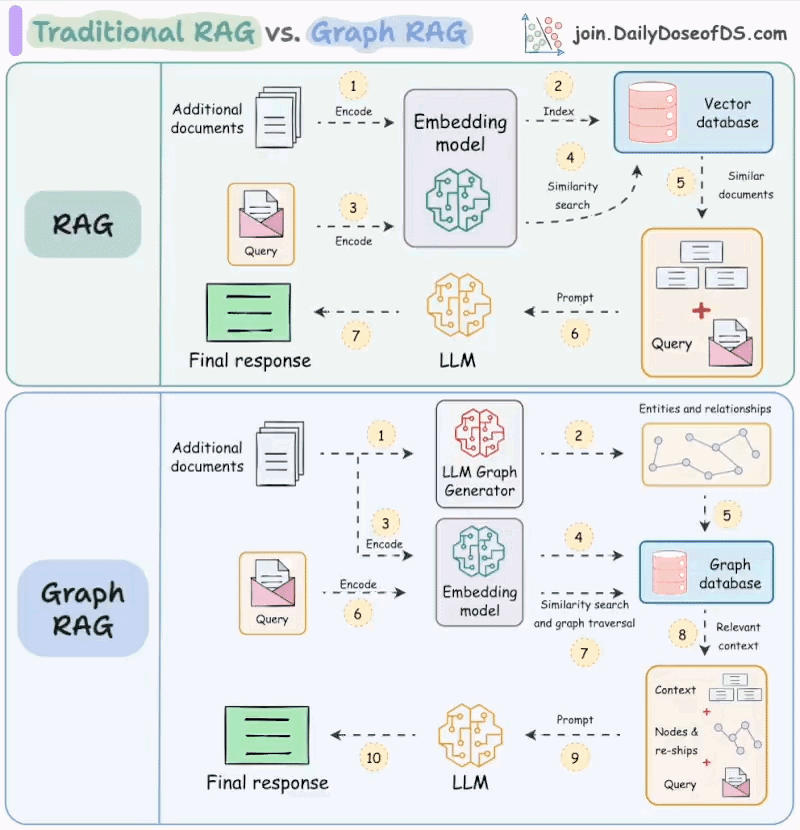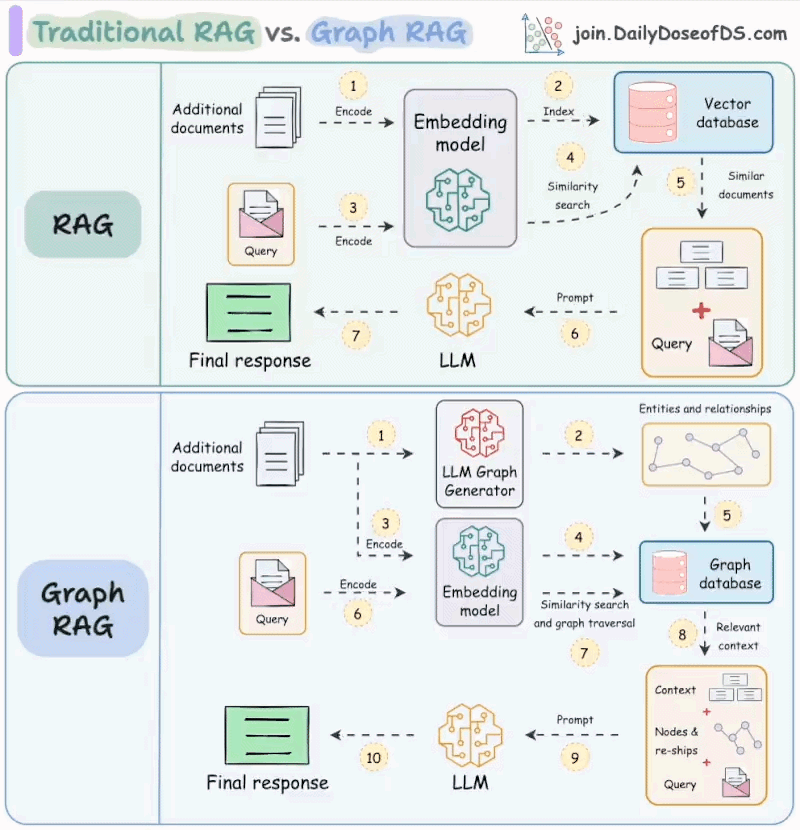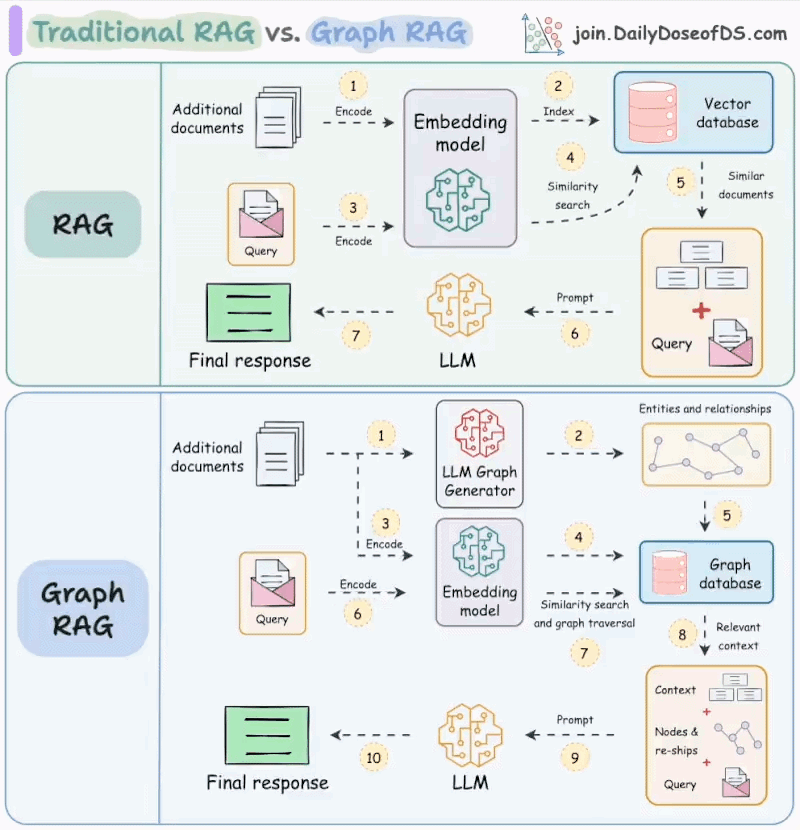
但是RAG仍然只是停留在信息的检索,没有对外部世界产生影响。即使是GraphRAG 本质上仍然是在解决“回答得更准”的问题,而不是“把事情做完”。
当问题只需要一个确定答案时,检索足够;但一旦任务需要决策、执行和反馈,仅仅把外部信息塞进上下文提示词就显得力不从心。模型无法根据中间结果调整行为,也无法主动调用外部能力去改变系统状态。
从工程角度看,RAG 的能力边界非常清晰:它只能“读”,不能“写”。
检索系统负责把外部世界的状态投射进模型的上下文,但模型本身并不具备改变这些状态的能力。无论是调用接口、修改配置、触发任务,还是根据中间结果重新规划流程,RAG 都无法完成闭环。
一旦目标从“生成答案”升级为“完成任务”,大模型就必须具备行动能力,而这正是 Agent 架构出现的直接原因。RAG可以作为Agent的信息来源,辅助大模型决策。
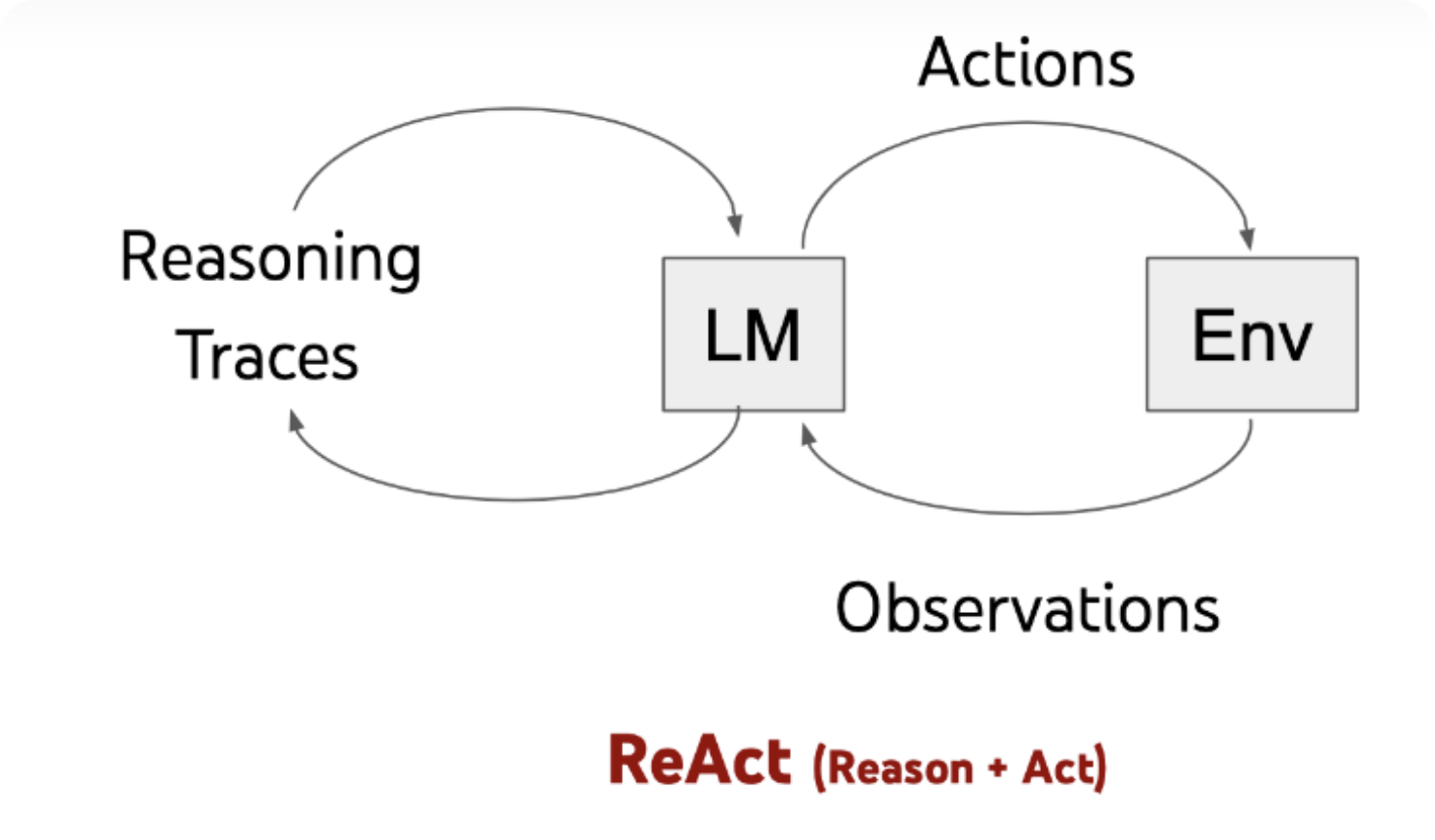
ReAct结合Reasoning和Action,将推理的内容转化成可实践的任务,再根据任务执行后环境反馈的错误再进行反思,如此循环最终达到目标。
1 | 生成提示词 → 调用 AI → 解析响应 → 执行工具 → 重复直到完成 |
稍微工程化成这样:
1 | 1. 构造上下文 / 提示词(Prompt + State) |
这就是 Agent Loop(ReAct / Tool-Use Loop)。
The Rise and Potential of Large Language Model Based Agents: A Survey
中文版:大型语言模型智能体的兴起与潜力的调查
真实 Agent 一定比这几步复杂,这只是 “能跑起来的最小 Agent”,工业级通常会加这些层:
1. 状态(State / Memory)
- short-term memory(当前任务上下文)
- long-term memory(历史、向量库)
- working memory(中间结果)
否则 Agent 会“失忆”。
2. 约束与控制(Guardrail)
- 最大循环次数(防止死循环)
- 工具白名单
- 输出 Schema 校验
- 成本 / token 限制 (上下文工程)
3. 失败处理(Recovery)
- Tool 执行失败 → 反馈给 LLM
- 解析失败 → 让 LLM 重试 / 修正格式
- 结果不满足目标 → 自我反思(self-critique)
4. 终止条件(Done / Stop)
终止不只是:
- “LLM 说完成了”
而是:
- 达成目标条件
- 没有可执行 Action
- 达到最大迭代
- 置信度 / 评分达标
这也是为什么目前最成功的Agent是Cursor、Claude Code这类编程工具,因为编程这类工作可以通过判断代码编译是否成功,测试用例能不能过(Spec Driven Development),来判断任务是否达成目标。程序的结果机器是可以验证的。还有一个关键的因素是,代码因为有git做版本控制,即使模型出现幻觉,也可以回滚。所以Coding Agent是目前落地最成功的Agent场景。
像Manus这样的想做成通用的Agent受限于模型自身能力,目前实际体验效果并没有编程领域Agent带来的震撼性强。
维度 Coding GUI 状态可观测 高 低 行为可回滚 是(git) 否 结果可验证 是(test) 难 噪音 低 极高 权限风险 可控 极高 Agent 可行性 ≈ 状态可观测 × 行为可回滚 × 结果可验证 ÷ 风险
这个抽象,本质就是一个「状态机」
从工程角度看,Agent = 一个可控的状态机:
1 | ┌────────┐ |
LangGraph/AutoGen/CrewAI/Spring AI Agent等AI Agent框架本质都是在管这个循环。
工程化落地:AI Agent框架
ReAct 循环本身很简单,Agent框架不是为“能跑”而生的,而是为“能长期稳定地跑在真实世界”而生的。
最小 ReAct 循环真的很简单,最简版 ReAct,大概就这么点逻辑:
1 | while not done: |
我这里有rust版本实现的ReAct-Loop可以运行起来看一看
模型输出不稳定(这是第一个地狱)
你以为 LLM 会乖乖按照你系统提示词里要求的格式输出:
1 | { "tool": "search", "args": { "q": "xxx" } } |
现实可能是: JSON 少个括号、字段拼错、输出半截自然语言、tool name 拼错
大模型并不像传统应用程序一样是“严格执行指令的程序”,大模型的本质是基于概率的token权重模型:在给定上下文的情况下,预测下一个 token 的概率最大值,从而组合成最终的文本返回。即使是相同prompt,相同上下文,重复调用也不一定得到相同的返回,有篇文章专门介绍了《在LLM推断中击败非确定性》。你要求大模型严格按json格式输出,但模型会觉得加一句解释,或者返回markdown更友好,人类友好性 vs 机器友好性冲突时,模型常选前者。
Tool的模式
Agent开发的核心就是提供Tool供大模型决策调用。目前Agent的Tool有三个运行模式:Function Call、MCP、SubAgent。
1、 Function Call
我写的ReAct-Loop这个例子就是Function Call,这是最简单的模式:就是Agent自身提供一个函数调用作为“Tool”丢给大模型。对于有参数的函数还要把参数和返回值的schema喂给大模型。
2、 MCP
MCP是Anthropic公司于2024年11月提出来的。MCP相当于把Function Call做成了可被调用的JSON-RPC服务,这样的好处是Agent与Tool解耦。MCP-Server通过标准的协议定义并暴露自己提供的服务:
1 | { |
Agent注册MCP服务供大模型调用。
MCP 本质上就是把「function call」标准化、外部化、服务化
3、 SubAgent / MultiAgent
SubAgent ≈ 把一个 agent 封装成一个 tool,供主 agent 调用。这么做的目的是把复杂性问题拆分成子问题交给SubAgent,这主要是解决上下文复杂度,防止主问题prompt爆炸。
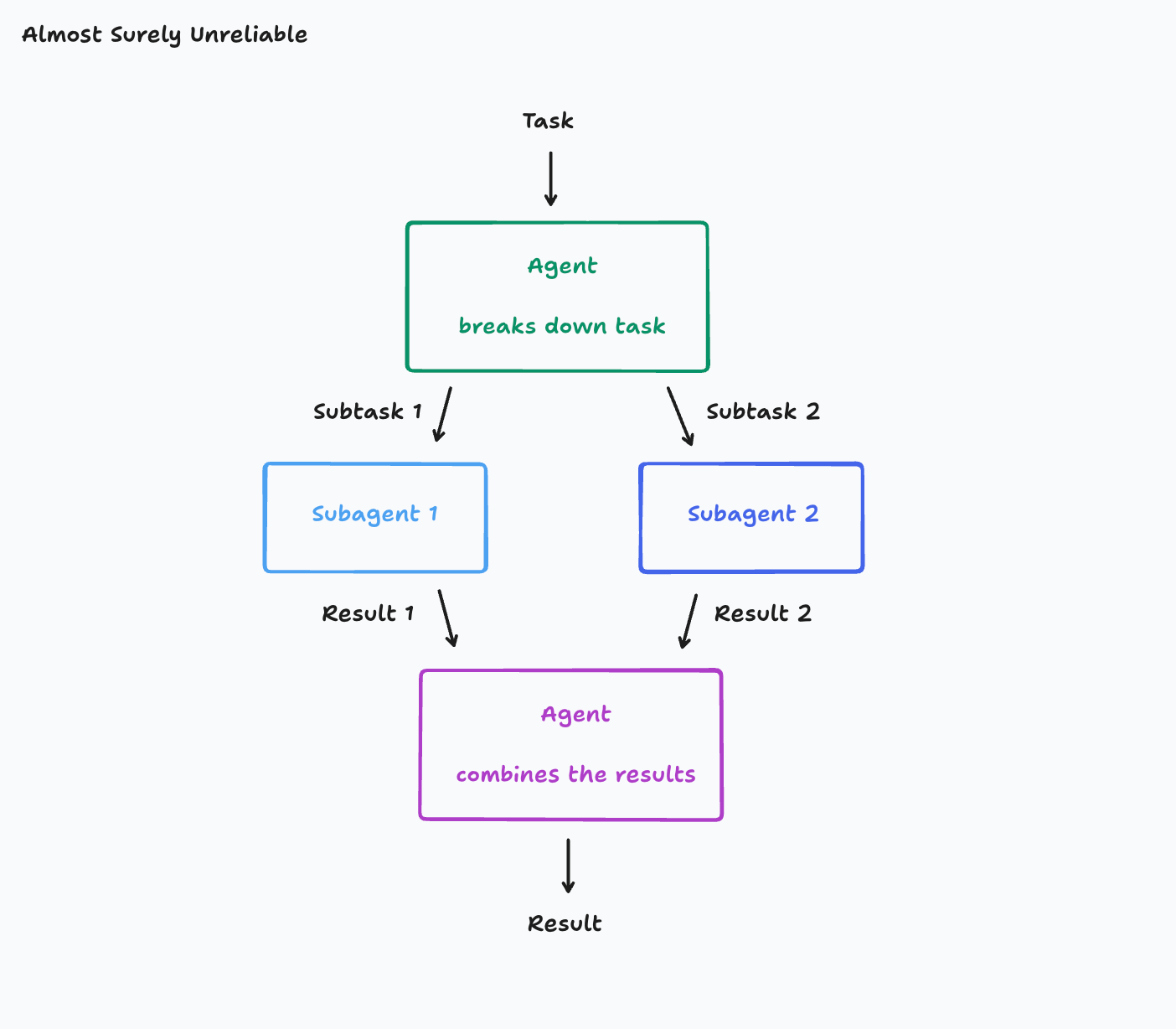
这里有篇文章专门讲了多Agent架构 / 选择合适的多Agent架构
4、 A2A:Agent间的远程编排协议
和MCP类似,Agent间为了解耦也搞了个JSON-RPC协议。A2A协议由Google于2025年4月提出的,这和微服务很像:Agent-to-Agent (A2A) 协议支持在运行于不同服务器上的 Agent 之间进行对话转移,这些服务器可能位于不同的数据中心或由不同的组织管理。此能力支持分布式 Agent 架构和微服务部署。
你可能和我一样有个疑问:既然Agent可以作为Tool,那自然也可以通过MCP远程暴露给调用方,为什么还多此一举再搞个A2A协议?
A2A官网有句话定位很准:
Build with
ADK (or any framework), equip with
MCP (or any tool), and communicate with
A2A, to remote agents, local agents, and humans.
| 概念 | 本质 |
|---|---|
| Function tool | 无推理的原子能力 |
| MCP tool | 远程、标准化的 function tool |
| Sub-agent | 有推理能力的复合 tool |
| A2A | 多个 Sub-agent 之间的组织与协作机制(复合 tool 的编排层) |
目前各大厂的Agent框架
RAG相关开源项目:
- https://github.com/microsoft/graphrag
- https://github.com/infiniflow/ragflow
- https://github.com/HKUDS/LightRAG
- https://github.com/Tencent/WeKnora
Agent框架:
- https://github.com/microsoft/autogen
- https://github.com/google/adk-python
- https://github.com/openai/openai-agents-python
- https://github.com/anthropics/anthropic-sdk-python
- https://github.com/crewaiinc/crewai
- https://github.com/pydantic/pydantic-ai
国内大厂的:
- https://github.com/agentscope-ai/agentscope
- https://github.com/TencentCloudADP/youtu-agent
- https://github.com/spring-ai-alibaba/DataAgent
- https://github.com/alibaba/spring-ai-alibaba/tree/main/spring-ai-alibaba-agent-framework
Rust社区相关库
- https://github.com/zavora-ai/adk-rust
- https://github.com/Abraxas-365/langchain-rust
- https://github.com/sobelio/llm-chain
推荐阅读:

