最近读了两篇文章,这两篇文章分别从宏观(InfluxData官方博客)和微观(掘金社区技术解析)的角度深入探讨了 FDAP 架构(Flight, DataFusion, Arrow, Parquet)及其在现代数据系统中的应用。
FDAP:新一代数据系统的基石架构
在当今数据爆炸的时代,传统的“大一统”数据平台已难以满足日益多样化和高性能的需求。针对特定场景(如时间序列、日志分析、金融交易等)构建的专用系统,往往能获得10到100倍的性能与成本优势。然而,从零开始构建一个高性能数据库或分析引擎,意味着要重复发明无数个复杂的轮子——内存布局、网络协议、查询优化器、存储格式……这不仅耗时耗力,而且极易出错。
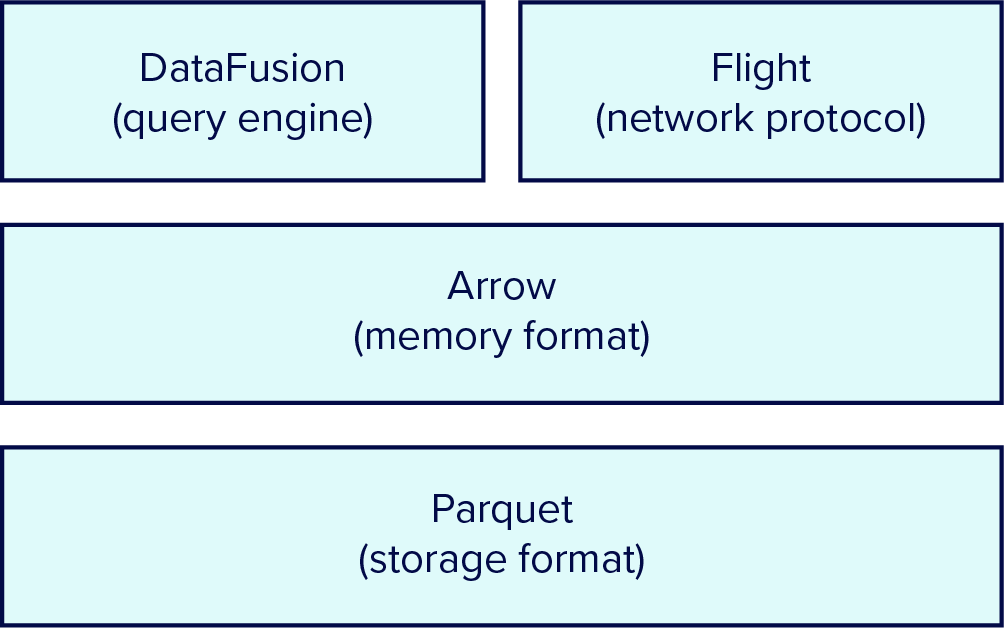
正是在这样的背景下,FDAP 架构应运而生,并迅速成为构建下一代云原生、高性能数据系统的事实标准。FDAP 并非一个单一的产品,而是由四个强大的开源项目组成的协同技术栈:
- Flight: 高效的数据传输层
- DataFusion: 灵活的查询执行引擎
- Arrow: 统一的内存数据格式
- Parquet: 开放的列式存储格式
这套组合拳,让开发者能够将精力聚焦于业务逻辑本身,而非底层基础设施的重复建设。
FDAP 的核心组件:各司其职,协同增效
- Apache Arrow:内存中的通用语言
Arrow 定义了一套标准化的、面向列式的内存数据格式。它解决了不同系统间数据交换时昂贵的序列化/反序列化(SerDe)开销问题。想象一下,Python 的 Pandas、Java 的 Spark、C++ 的计算库,如果都使用 Arrow 作为内存表示,它们之间的数据传递就无需任何转换,如同在同一语言内部操作一样高效。
对于 InfluxDB 3.0 这样的系统而言,采用 Arrow 意味着:
省去了自研内存模型的复杂性:无需再纠结于如何表示空值、处理字节序、设计向量化计算等底层细节。
无缝集成生态:查询结果可以直接被 Pandas、Spark、DuckDB 等工具消费,极大地简化了数据分析工作流。
- Apache Parquet:经济高效的持久化存储
Parquet 是一种开放的、列式存储文件格式,以其卓越的压缩比和高效的谓词下推(Predicate Pushdown)能力而闻名。令人惊讶的是,在 InfluxData 的实践中,通用的 Parquet 格式在综合考虑索引等结构后,其压缩效率甚至比许多专为时间序列设计的私有格式高出5倍。
选择 Parquet 为 InfluxDB 3.0 带来了巨大的互操作性红利:
即插即用:任何支持 Parquet 的系统(如 Snowflake、Presto、Databricks)都可以直接读取 InfluxDB 存储的数据,无需复杂的 ETL 管道。
未来可扩展:依托于庞大的 Parquet 生态,系统可以轻松接入未来的分析、BI 或机器学习工具。
- Apache Arrow Flight & FlightSQL:超高速的数据高速公路
Flight 是一个基于 gRPC 和 Arrow 构建的高性能 RPC 框架,专为在系统间高效传输 Arrow 数据而设计。在其之上,FlightSQL 定义了一套标准的 SQL 接口。
这对 InfluxDB 3.0 的意义是革命性的:
告别驱动地狱:传统数据库需要为每种语言(JDBC、ODBC、Python DB-API等)维护一套复杂的客户端驱动。而通过实现 FlightSQL,InfluxDB 3.0 自动获得了所有现有 FlightSQL 驱动的支持,省去了一个完整的驱动开发团队。
极致性能:Flight 避免了数据在网络传输过程中的编解码开销,使得大规模数据集的传输速度得到数量级的提升。正如 Dremio 的实践所证明,其性能相比传统 ODBC/JDBC 可提升20-50倍。
- Apache DataFusion:开箱即用的查询大脑
DataFusion 是一个用 Rust 编写的现代化、可扩展的查询引擎,它天然使用 Arrow 作为内存模型。它内置了SQL解析、查询优化、向量化执行、并行处理等企业级OLAP引擎所需的核心功能。
对于 InfluxData 而言,这意味着:
站在巨人的肩膀上:无需投入数十人年的精力去从头构建一个查询引擎。他们只需在 DataFusion 的基础上,专注于实现时间序列特有的功能,如 InfluxQL 语言支持、数据去重、时间窗口填充等。
持续受益于社区:DataFusion 的每一次功能增强和性能优化,都会自动惠及 InfluxDB 3.0。
FDAP 的威力:不止于 InfluxDB
FDAP 架构的价值已被众多前沿项目所验证。除了作为其命名来源的 InfluxDB 3.0,我们还能看到:
- CeresDB:分布式、云原生时间序列数据库。已捐献给apache/horaedb
- Coralogix:全栈可观测平台
- Greptime:云原生时间序列数据库
- Synnada:统一的流媒体和分析平台
- OpenObserve:专为日志、指标和追踪构建的可观测性平台
- Dremio:数据即服务平台。这个分布式 SQL 查询引擎深度利用 Arrow 作为其内存核心,并贡献了 Gandiva(一个基于 LLVM 的高性能表达式编译器)来加速 Arrow 上的计算。
- Spice.ai:一个旨在简化 AI/ML 应用开发的运行时,它通过 Arrow 和 Flight 在数据源与 AI 引擎之间建立高效通道,将可处理的数据规模提升了10-100倍。
总结:拥抱开放标准,释放创新潜能
FDAP 架构的成功,本质上是开放标准和模块化设计理念的胜利。它将构建一个现代数据系统所需的复杂技术分解为几个清晰、独立且高度优化的组件。开发者不再需要“重复造轮子”,而是可以像搭积木一样,组合这些世界级的开源组件,快速构建出高性能、高兼容性的专属解决方案。
正如 LAMP(Linux, Apache, MySQL, PHP/Python/Perl)堆栈曾赋能了第一代互联网应用的繁荣,我们有理由相信,FDAP 架构将成为驱动下一代数据密集型应用(尤其是云原生、AI/ML 和实时分析场景)创新的核心引擎。对于任何希望在数据领域有所建树的团队和个人来说,理解和掌握 FDAP,无疑是把握未来的关键一步。

