核心概念概述
- 检索(Retrieval):在信息检索中,指的是从一个大规模文档集合中找到与用户查询相关的文档子集的过程。这是搜索引擎、问答系统等的核心步骤。
- 表示(Representation):如何用计算机可处理的形式来表示查询和文档,是检索效果好坏的关键。
1. 稀疏检索
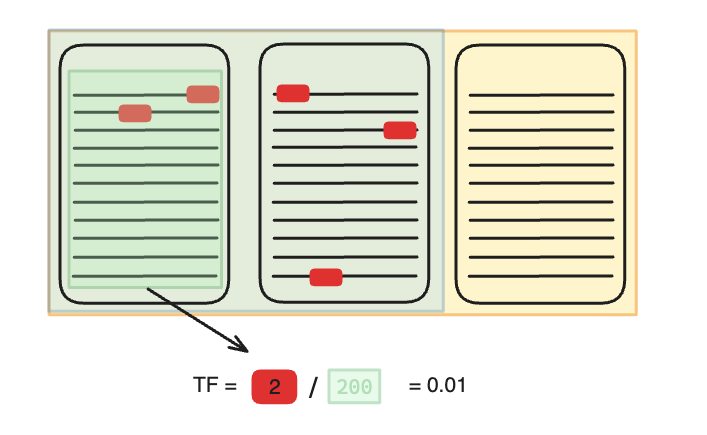
核心思想:
- 使用高维、稀疏的向量来表示查询和文档。
- 向量的维度通常对应于词汇表中的所有词项(Term)。
- 每个维度的值表示该词项在查询或文档中的重要性(权重)。
- 权重计算通常基于词频(TF)、逆文档频率(IDF)等统计信息。
- 关键特征:向量的大部分维度值为 0(稀疏),只有文档或查询中实际出现的词对应的维度值不为 0。
代表算法:
- TF-IDF:词频-逆文档频率,经典权重计算方法。
- BM25:TF-IDF 的改进和概率化版本,是目前最主流的稀疏检索算法,效果稳定且优异。它考虑了词频、文档长度、逆文档频率等因素。
以下是 TF-IDF 和 BM25 的完整计算公式,使用 LaTeX 格式呈现:
TF-IDF 公式
TF-IDF 由两部分组成:词频 (TF) 和 **逆文档频率 (IDF)**。- 词频(TF)
其中:
:词项 在文档 中的出现次数 :文档 的总词项数
逆文档频率 (IDF)
其中::语料库中文档总数 :包含词项 的文档数量
TF-IDF 最终分数
- 词频(TF)
BM25 公式
BM25 在 TF-IDF 基础上引入了词频饱和控制和文档长度归一化。
完整 BM25 分数
组件详解:逆文档频率 (IDF)
:文档总数 :包含词项 的文档数量 :平滑因子,避免除零错误
词频饱和控制
:词项 在文档 中的频率 :饱和度参数(默认值 ) - 作用:抑制高频词的过度影响(非线性增长)
文档长度归一化
:当前文档长度(词项数量) :语料库中文档平均长度 :长度归一化参数(默认 ) - 作用:惩罚长文档,避免长度偏差
- 关键改进对比
组件 TF-IDF BM25 改进 词频 (TF) 线性增长: 非线性饱和: 文档长度处理 无 显式归一化: IDF 平滑 基础: 鲁棒平滑: 可调参数 无 参数化: (控制饱和度) 和 (控制长度惩罚) - 核心优势总结
BM25 通过 非线性 TF 饱和 和 文档长度归一化 解决了 TF-IDF 的两大缺陷:
- 避免长文档主导结果(例如一篇 10,000 词的文档偶然多次出现查询词)
- 抑制关键词重复堆砌(例如关键词重复 100 次不代表相关性线性增加 100 倍)
- 参数可调(通过
和 适配不同场景的数据分布) 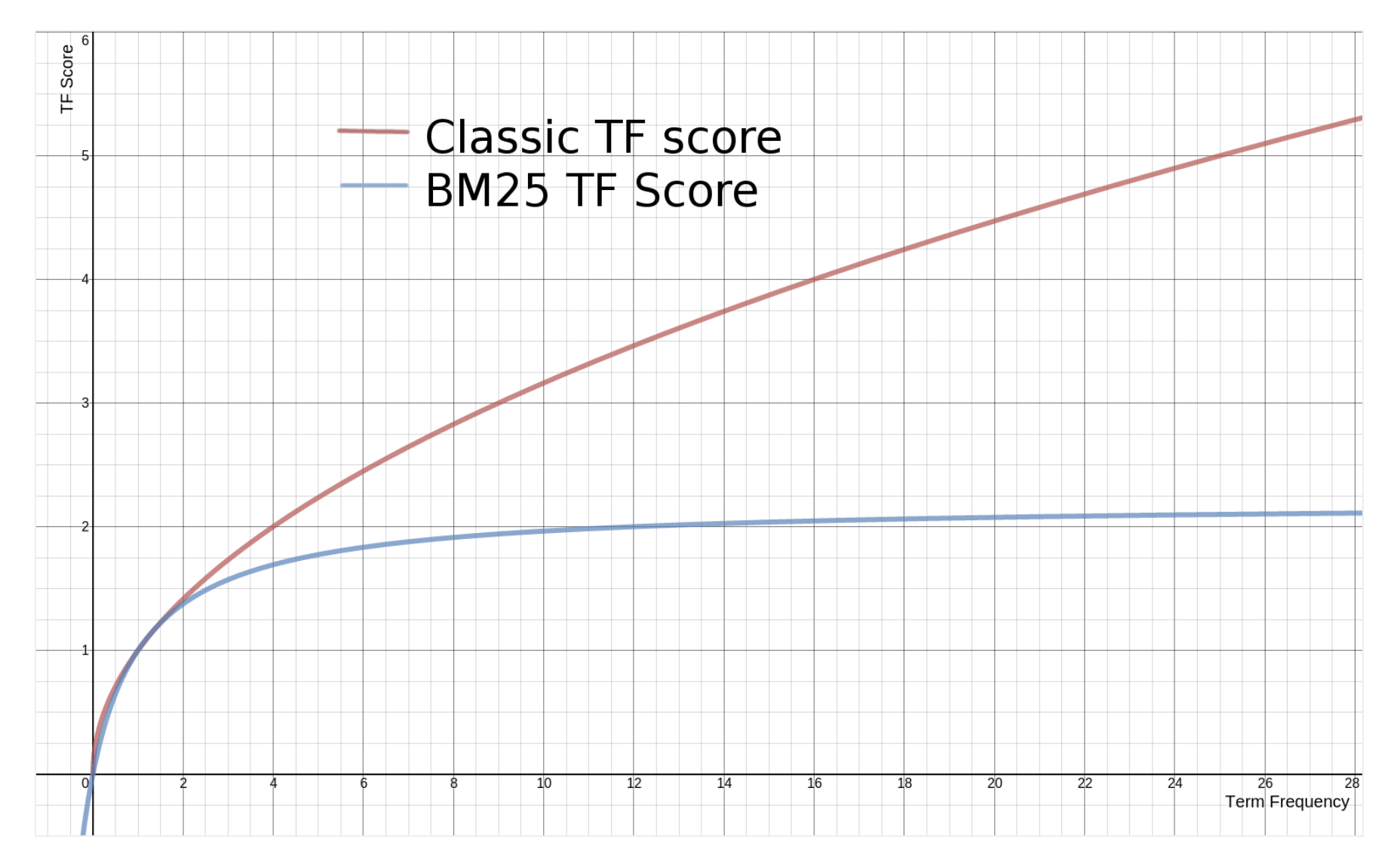
计算相关性:
- 查询向量
q和文档向量d的相关性得分通常通过它们向量的点积(Dot Product)q · d计算。 - 点积的结果本质上是查询和文档中共同出现的词项权重乘积之和。
- 查询向量
优点:
- 可解释性强:得分直接来源于共同词项及其权重,容易理解为什么某文档被召回。
- 效率高:可以利用倒排索引(Inverted Index)实现非常高效的检索(仅需处理包含查询词的文档)。索引构建和查询速度通常很快。
- 无需训练数据:经典方法(如BM25)不需要特定的训练语料来学习参数(虽然参数可以调优)。
- 对精确匹配效果好:当查询包含明确关键词时,效果通常很好。
缺点:
- 词汇鸿沟问题:无法处理同义词(
carvsautomobile)、近义词(bigvslarge)、一词多义(bank可以是河岸或银行)等问题。查询和文档必须包含相同的词项才能匹配。 - 语义理解有限:主要基于词形(lexical)匹配,缺乏对深层语义的理解。
- 长尾/复杂查询效果可能不佳:对于表述模糊、依赖语义而非关键词的查询效果可能不如稠密检索。
- 词汇鸿沟问题:无法处理同义词(
典型应用:
- 传统搜索引擎(如早期的Google,现在核心BM25仍是重要组成部分)。
- 需要高效、可解释检索结果的场景。
- 作为更复杂检索系统的第一级召回器(快速筛选候选文档)。
2. 稠密检索
- 核心思想:
- 使用低维、稠密的向量(通常称为嵌入向量)来表示查询和文档。
- 向量维度通常在几百到几千维。
- 关键特征:向量的每个维度通常都有非零值(稠密),每个维度代表某种潜在的语义特征。这些特征是通过深度神经网络学习得到的。
- 代表模型:
- 双塔模型(Dual Encoder):最常见架构。一个神经网络编码器将查询映射为向量
q,另一个(通常共享参数)将文档映射为向量d。 - 预训练语言模型驱动:如基于BERT的模型(DPR, ANCE, ColBERT等)。这些模型利用大规模语料上预训练得到的强大语义理解能力。
- 双塔模型(Dual Encoder):最常见架构。一个神经网络编码器将查询映射为向量
- 计算相关性:
- 查询向量
q和文档向量d的相关性得分通过计算它们之间的向量相似度得到,最常用的是余弦相似度(Cosine Similarity)cos(q, d)。 - 相似度衡量的是它们在低维语义空间中的“距离”或“方向一致性”。
- 查询向量
- 优点:
- 强大的语义表示能力:能有效捕捉同义词、近义词、语义关联(
AI和机器学习),缓解词汇鸿沟问题。 - 对复杂/模糊查询效果好:能更好地理解查询的意图和上下文语义。
- 迁移学习潜力:预训练语言模型的知识可以迁移到特定领域任务。
- 强大的语义表示能力:能有效捕捉同义词、近义词、语义关联(
- 缺点:
- 可解释性差:难以解释为什么某个向量代表了某个语义,以及为什么两个向量相似。是一个“黑盒”。
- 需要大量训练数据:训练高质量的稠密检索模型通常需要大量的标注数据(查询-相关文档对)。
- 计算开销大:
- 训练成本高:需要GPU资源和时间训练模型。
- 索引构建复杂:需要为所有文档生成稠密向量(嵌入),存储空间需求大(比稀疏索引大得多)。
- 检索效率挑战:计算所有文档向量的余弦相似度在大规模库中非常慢(
O(N))。通常需要借助近似最近邻搜索技术来加速。
- 对精确匹配可能不如BM25:如果查询就是精确的关键词组合,BM25可能更直接有效。
- 典型应用:
- 开放域问答(Open-Domain QA)。
- 需要深度语义理解的检索任务(如对话系统、推荐系统)。
- 作为稀疏检索的补充,提高召回结果的相关性和多样性(混合检索)。
RAG 详细分步流程
第一阶段:数据准备(预处理,通常是离线完成)
这一步是构建RAG系统的基础,类似于为模型准备一个“参考图书馆”。
- 加载数据(Loading):从指定的数据源(如公司内部的PDF、Word文档、API文档、网页、数据库等)获取原始数据。
- 转换数据(Splitting):将文档转换成更小的、具有语义的文本片段(chunks)。这是因为大模型有上下文窗口限制,且小块文本更易于精准检索。
- 方法:通常使用文本分割器(Text Splitter),按字符、标记(token)或标题等自然断点进行分割。
- 向量化(Embedding):使用嵌入模型(Embedding Model)(如OpenAI的text-embedding-ada-002、Cohere的模型、开源的BGE模型等)将每个文本块转换为一个高维数值向量(Vector)。这个向量代表了该文本的语义信息。
- 存储(Storing):将这些向量及其对应的原始文本内容,存入一个专门的向量数据库(Vector Database)(如Chroma, Pinecone, Weaviate, Qdrant等)。向量数据库的优势在于能高效地进行相似性搜索。
第二阶段:检索(Retrieval - 实时)
当用户提出一个问题时,系统会在这个“参考图书馆”里查找最相关的资料。
- 查询向量化(Query Embedding):当用户输入一个问题(Query)时,系统使用同一个嵌入模型将这个问题也转换为一个向量。
- 向量相似性搜索(Similarity Search):系统在向量数据库中,搜索与“查询向量”最相似的前K个文本块向量(K是一个可设定的数量,例如Top 5)。
- 度量标准:通常使用余弦相似度(Cosine Similarity)等方法来计算向量间的相似度。
- 获取上下文(Retrieve Context):系统根据上一步找到的向量,从数据库中取出对应的原始文本块(Chunks)。这些文本块就是与用户问题最相关的“证据”或“上下文”。
第三阶段:增强生成(Augmented Generation - 实时)
现在,大模型拿到了“参考资料”,开始生成答案。
构造提示词(Prompt Construction):系统构造一个最终的提示词(Prompt),发送给大语言模型(如GPT-4等)。这个提示词通常由三部分组成:
- 指令(Instruction):告诉模型它的角色和任务(例如:“你是一个有帮助的助手,请根据以下上下文回答问题。”)
- 检索到的上下文(Retrieved Context):将第7步中获取到的所有相关文本块作为背景信息。
- 用户问题(User Question):原始的用户问题。
- 示例:
指令: 请严格根据提供的上下文内容来回答问题。如果答案不在上下文中,请回答“根据已知信息无法回答该问题”。
上下文: {这里插入从向量数据库检索到的相关文本块1、2、3…}
问题: {用户的原始问题}
答案:
生成回答(Generation):大语言模型接收到这个精心构造的提示词后,会基于提供的上下文(而不是仅凭其内部记忆)来生成一个准确、可靠的答案。
返回答案(Response):将生成的答案返回给用户。
3. 知识图谱增强检索
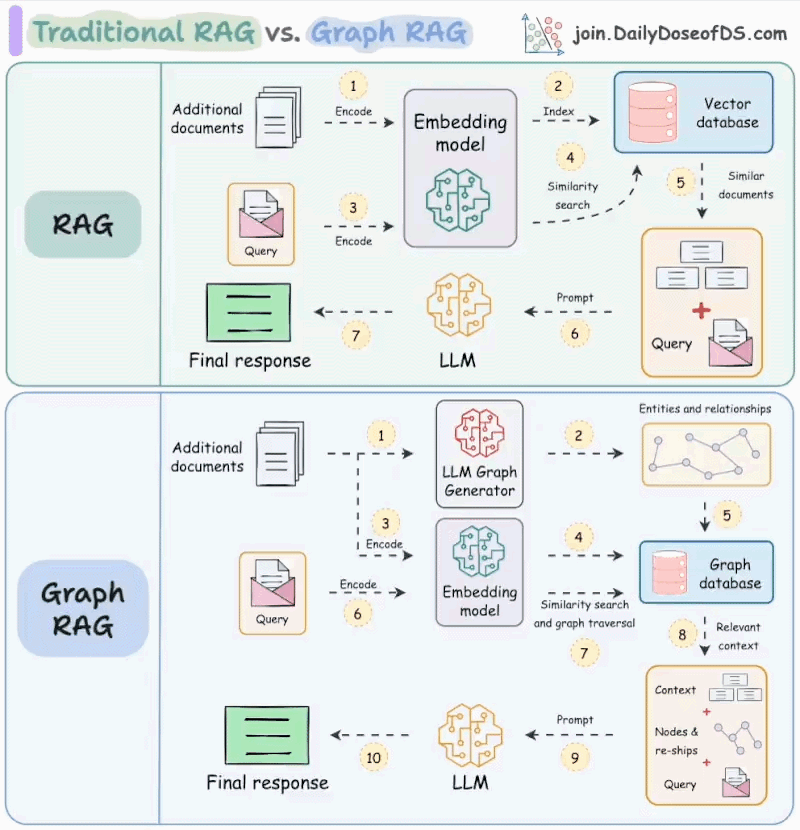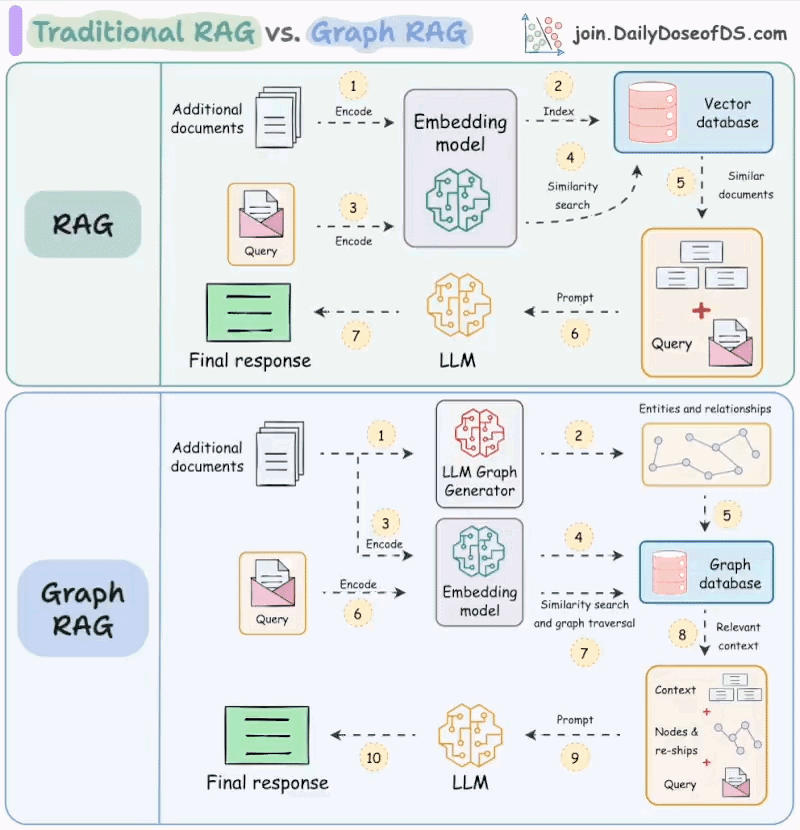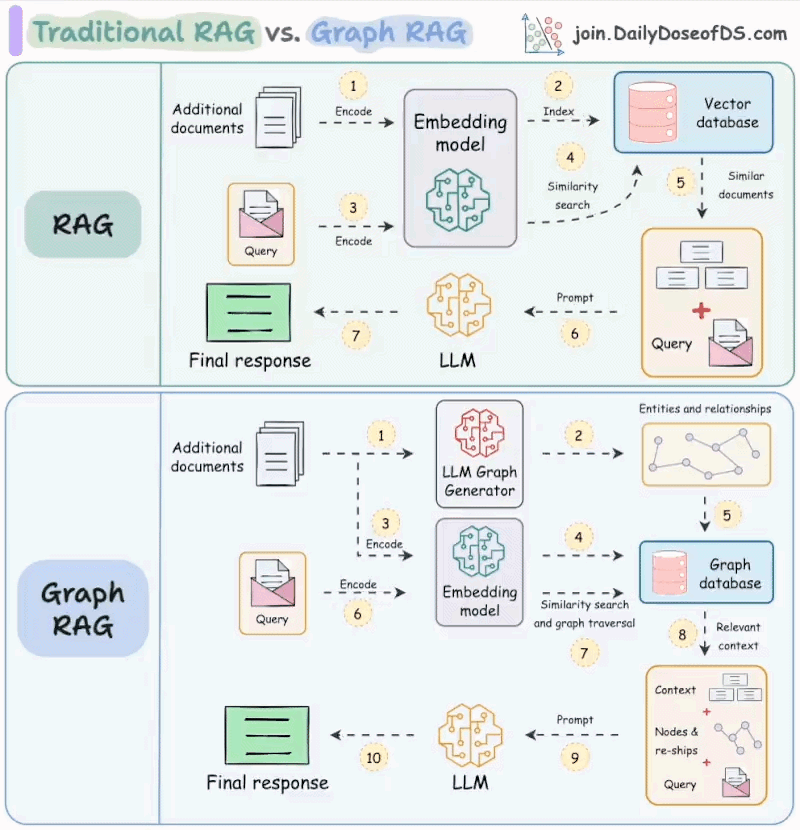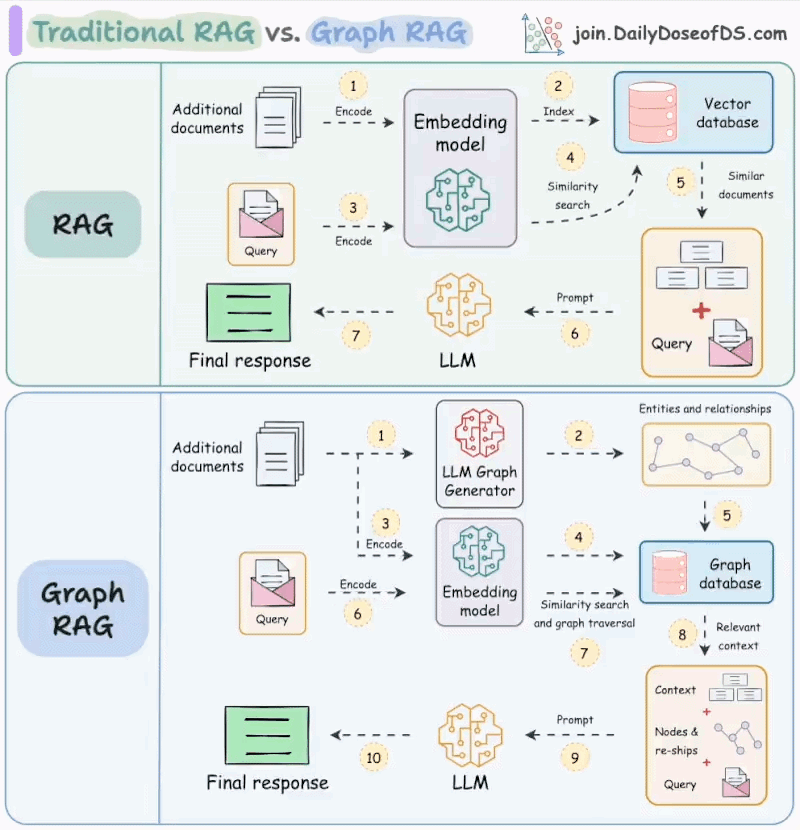
- 核心思想:
- 不是独立的检索模型,而是利用外部结构化的知识图谱来增强现有的检索模型(稀疏或稠密)。
- 知识图谱是一个由实体(Entity)、实体属性(Attribute)和实体间关系(Relation)组成的语义网络。
- 目标是将KG中包含的丰富语义信息(实体链接、关系、类型、描述等)融入到检索过程中,提升对查询和文档的理解。
- 增强方式:
- 查询扩展/重写:
- 识别查询中的实体。
- 利用KG查找该实体的别名、同义词、相关实体(如:
Steve Jobs->Apple Inc.创始人 ->Apple产品iPhone)。 - 将扩展得到的信息(别名、相关实体词)加入到原始查询中,再用稀疏/稠密模型检索。
- 文档表示增强:
- 识别文档中的实体。
- 将实体在KG中的信息(类型、关系、描述文本的嵌入)融入到文档的向量表示中(稀疏或稠密)。
- 联合检索/排序:
- 在检索或排序阶段,不仅考虑查询-文档的匹配度,也考虑文档中实体与查询中实体的语义关联度(通过KG中的路径、关系等计算)。
- 构建图神经网络模型,同时建模文本信息和KG结构信息。
- 实体链接(Entity Linking):将文本中提到的实体指称项链接到KG中对应的实体,这是很多增强方法的基础步骤。
- 查询扩展/重写:
- 优点:
- 引入结构化知识:提供额外的、明确的语义信息,弥补纯文本理解的不足。
- 提升语义理解深度:更好地理解实体间关系、实体类型、背景知识。
- 缓解歧义:帮助区分一词多义(利用实体上下文)。
- 可解释性潜力:通过实体链接和关系路径,可以提供部分解释(如:文档被召回是因为提到了与查询实体相关的另一个实体X)。
- 缺点:
- 依赖高质量KG:检索效果高度依赖于所使用的知识图谱的覆盖面、准确度和时效性。构建和维护高质量KG成本高昂。
- 实体链接错误传播:如果实体链接步骤出错,后续增强可能引入噪声甚至错误。
- 系统复杂度增加:需要集成实体识别、链接、KG查询等多个模块,系统架构更复杂。
- 领域依赖性强:特定领域的KG可能难以获取或构建。
- 典型应用:
- 需要深度领域知识的检索(如医疗、金融、法律)。
- 百科问答、事实核查。
- 需要理解实体间复杂关系的场景。
- 任何希望利用结构化知识提升纯文本检索效果的领域。
在RAG中Embdding Model不存在“绝对最好”,只有“最合适”:
- 中文为主的 RAG:BGE 系列(bge-m3 / bge-large-zh)是目前性价比和效果最均衡的选择
- 中英混合 / 通用检索:bge-m3 或 text-embedding-3-large(OpenAI)
- 极致效果、不差钱:OpenAI embedding(text-embedding-3-large)
目前北京智源人工智能研究院的BGE几乎是当前检索领域开源 Embedding 的事实标准,中文语义检索明显强于 sentence-transformers
总结对比表
| 特性 | 稀疏检索 (如 BM25) | 稠密检索 (如 DPR, ANCE) | 知识图谱增强检索 (KG-Augmented) |
|---|---|---|---|
| 核心表示 | 高维稀疏向量 (词袋) | 低维稠密向量 (嵌入) | 利用KG增强稀疏或稠密向量/检索过程 |
| 匹配基础 | 词形 (Lexical) 匹配 | 语义 (Semantic) 匹配 | 语义 + 结构化知识 |
| 解决词汇鸿沟 | 弱 | 强 | 强 (通过实体、同义词、关系) |
| 可解释性 | 高 (基于词项) | 低 (黑盒向量) | 中等 (依赖实体链接和关系路径) |
| 训练数据需求 | 无/低 (BM25参数可调) | 高 (需要大量标注对) | 中等/高 (依赖KG和可能的链接模型训练) |
| 索引/检索效率 | 非常高 (倒排索引) | 较低 (需ANN加速稠密向量搜索) | 中等 (取决于基础检索模型+KG操作开销) |
| 计算开销(训练) | 极低 | 非常高 (GPU训练) | 高 (KG构建/维护 + 模型训练) |
| 计算开销(推理) | 低 | 中等/高 (向量计算/ANN) | 中等 (基础模型推理 + KG查询/计算) |
| 典型优势场景 | 关键词明确查询,高效召回 | 语义复杂/模糊查询,理解深层含义 | 需要领域知识、理解实体关系的查询 |
| 主要缺点 | 词汇鸿沟,语义理解弱 | 可解释性差,需训练数据,效率挑战 | 依赖KG质量,系统复杂,实体链接可能出错 |
发展趋势与融合
- 混合检索:当前最先进的检索系统通常结合稀疏检索和稠密检索。例如:
- 第一级:用BM25快速召回一批候选文档(高召回)。
- 第二级:用稠密检索模型对候选文档进行精细化重排(高精度)。
- 或者,将稀疏检索分数和稠密检索分数线性融合(如
score = α * BM25 + β * Dense)。
- 知识融入稠密模型:研究者致力于将KG知识直接编码到预训练语言模型中(如在预训练或微调阶段融入KG信息),让模型本身学习到更多结构化知识,减少对外部KG查询的依赖。
- 端到端学习:探索将KG信息、检索、排序甚至答案生成整合到一个端到端的可训练框架中。

