局部敏感哈希是为了解决一个核心问题:在海量数据中快速找到相似或近似的项目,避免进行代价高昂的“两两比较”。
想象一下,你有几百万张图片、几百万篇文档,或者几亿个用户的行为记录。你想找出相似的图片、相似的文档,或者兴趣相似的用户。如果每对数据都去精确计算它们的相似度(比如余弦相似度、Jaccard相似系数),那计算量是天文数字。这就是 LSH 这类技术大展身手的地方。
1. LSH(局部敏感哈希):核心思想
- “局部敏感”是什么意思? 指的是哈希函数对输入数据的局部变化(相似性)敏感。
- 与传统哈希的区别:
- 传统哈希(如MD5, SHA-1): 核心目标是均匀分布和抗碰撞。输入数据哪怕只有一丁点不同(比如改了一个字符),哈希值就会变得天差地别。这是为了安全性和唯一性。
- LSH: 核心目标是保持相似性。如果两个输入数据很相似,那么经过LSH哈希后,它们有很高的概率得到相同或非常接近的哈希值(比如在同一个“桶”里)。反之,如果两个输入数据很不相似,那么它们有很高的概率得到完全不同的哈希值(在不同的“桶”里)。
- 核心机制:
- 设计一组特殊的哈希函数(
LSH Family)。 - 对每个数据点应用这些哈希函数,得到一个哈希签名(通常是一个由多个哈希值组成的短向量或一串比特)或者直接映射到桶ID。
- 关键点: 相似的数据点有很大的概率会被映射到相同的桶或者哈希签名非常接近。
- 设计一组特殊的哈希函数(
- 如何加速搜索?
- 建立索引: 把所有数据点根据它们的LSH哈希值(或桶ID)放入不同的“桶”中。
- 查询: 当你要找一个查询点
q的相似点时:- 计算
q的LSH哈希值(或桶ID)。 - 只去
q所在的那个(或那几个)桶里找候选点。 - 对这些少量的候选点进行精确的相似度计算(如果需要非常精确的结果)。
- 计算
- 巨大优势: 避免了与所有数据点进行精确比较!只需要比较桶里的少量候选点。
- LSH家族: LSH不是一个具体的算法,而是一类算法的框架。针对不同的相似度度量方式(如Jaccard相似度、余弦相似度、欧氏距离等),需要设计不同的LSH函数族。
- 核心目标: 用概率和近似换取速度和可扩展性。它可能漏掉一些相似点(假阴性),也可能放进一些不太相似的点(假阳性),但能极大提高效率。
简单比喻:
想象一个巨大的图书馆,书按照主题相似度(而不是精确的字母顺序)自动归类到书架上。如果你想找和《哈利波特》相似的书:
- LSH 就像图书馆的归类系统,它会自动把《哈利波特》放到一个标记为“青少年奇幻魔法冒险”的书架上。
- 你只需要去那个书架上找,而不用翻遍整个图书馆。
- 这个书架上的书(候选集)很可能就是你要找的相似书。虽然可能漏掉一两本在别的奇幻架上的好书(假阴性),也可能混进来一两本不那么像的冒险书(假阳性),但大大缩小了搜索范围。
2. MinHash:针对集合相似度(Jaccard相似度)的LSH
- 解决什么问题? 快速估计两个集合的 Jaccard相似度。
- Jaccard相似度:
。衡量两个集合的交集大小占并集大小的比例。范围在 [0, 1] 之间。常用于文档(词袋模型)、用户行为( )等。
- Jaccard相似度:
- 核心思想: MinHash 是 LSH 框架下的一种具体实现,专门为 Jaccard 相似度设计的哈希函数。
- MinHash值(签名)计算:
- 准备: 假设全集包含所有可能出现的元素(如所有单词)。
- 选择哈希函数: 选择一个能将全集元素均匀映射到数字(比如0到某个大数)的哈希函数
h(e)。 - 计算单个MinHash值: 对于一个集合
S,计算它的MinHash值m(S)就是:**m(S) = min{ h(e) for e in S }。也就是用哈希函数h映射集合S中所有元素,然后取映射结果中最小的那个值**作为S的MinHash签名。
- 神奇的性质:
P(m(A) = m(B)) = Jaccard(A, B)- 两个集合
A和B的MinHash值相等的概率,恰好等于它们的Jaccard相似度! - 如果
A和B完全一样(J=1),那它们的MinHash必然相等。 - 如果
A和B完全不同(J=0),那它们的MinHash不可能相等。 - 如果
A和B部分相同(0<J<1),它们MinHash相等的概率就是J。
- 两个集合
- 实际使用(签名矩阵):
- 单个MinHash值估计Jaccard相似度方差太大,不稳定。
- 通常使用
k个独立的哈希函数h1, h2, ..., hk。 - 对每个集合
S,计算k个MinHash值:[m1(S), m2(S), ..., mk(S)]。这个向量就是S的 MinHash签名。 - 两个集合
A和B的签名向量中,相同位置MinHash值相等的比例,就是Jaccard(A, B)的一个无偏估计。k越大,估计越准,但计算和存储开销也越大。
- 如何用于LSH(分桶):
- 目标: 把 Jaccard 相似度大于某个阈值
s的集合对找出来。 - 方法(Band Partition): 把
k维的 MinHash 签名分成b个 band(段),每个 band 包含r行(k = b * r)。 - 分桶规则: 对于每个集合的签名:
- 对每个 band,把这个 band 里面的
r个 MinHash 值拼接起来当作这个 band 的桶ID。 - 同一个集合会被放入
b个不同的桶(每个band一个桶)。
- 对每个 band,把这个 band 里面的
- 碰撞(相似)条件: 如果两个集合
A和B在至少一个 band 上,它们对应的r个值完全相等(即这个band的桶ID相同),那么它们就被认为是一个候选对。 - 原理: 调整
b和r可以控制召回率和精确率。r越小(band越宽),越容易碰撞(召回高,精度可能低);r越大(band越窄),越难碰撞(召回低,精度高)。
- 目标: 把 Jaccard 相似度大于某个阈值
- 应用场景: 文档去重(判断网页是否镜像/转载)、推荐系统(寻找有相似物品集合的用户)、基因序列分析(寻找有相似序列片段的基因)。
简单比喻:
假设每个顾客的购物车是一个集合(里面是商品ID)。MinHash 就像给每个顾客发一张“特征卡”:
- 有
k个考官(哈希函数),每个考官对购物车里的所有商品打分(哈希值)。 - 每个考官只记录他看到的最低分(MinHash值)并写在顾客的特征卡对应位置上。
- 比较两个顾客:看他们的特征卡上,有多少个考官记录的最低分是相同的。比例越高,说明他们购物车里的商品重合度(Jaccard相似度)越高。
- LSH分桶:把特征卡撕成
b条(band)。规定:只要两个顾客的某一条上的所有分数完全一样,就把他们当成“可能相似”的候选顾客,放到一起待查。
3. SimHash:针对高维特征向量(余弦相似度)的LSH
- 解决什么问题? 快速估计高维特征向量之间的余弦相似度或海明距离关系。常用于文本相似度(Google用于网页去重)。
- 核心思想: SimHash 也是 LSH 框架下的一种具体实现。它把高维特征向量(如文档的词频/权重向量)降维、压缩成一个固定长度(如64位)的二进制指纹(Fingerprint)。关键是:原始向量越相似,生成的SimHash指纹之间的海明距离(Hamming Distance,二进制串不同比特位的数量)就越小。
- SimHash指纹计算步骤(以文本为例):
- 特征提取: 将文档分词,提取特征(通常是词)及其权重(可以是词频、TF-IDF等)。得到特征-权重对
(feature_i, weight_i)。 - 传统哈希: 对每个特征
feature_i用一个标准哈希函数(如MD5, MurmurHash)映射成一个f位的二进制串H(feature_i)(例如64位)。 - 加权: 创建一个长度为
f的向量V(初始值全为0)。- 遍历
H(feature_i)的每一位j:- 如果
H(feature_i)的第j位是1,那么V[j] += weight_i。 - 如果
H(feature_i)的第j位是0,那么V[j] -= weight_i。
- 如果
- 简单理解:每个特征根据其权重,对
f个维度分别进行“投票”。1投正票,0投负票。
- 遍历
- 生成指纹: 遍历向量
V的每一位j:- 如果
V[j] > 0,则最终SimHash指纹的第j位设为1。 - 如果
V[j] < 0,则最终SimHash指纹的第j位设为0。 - (如果
V[j] == 0,可以随机设为0或1,但概率很小)
- 如果
- 输出: 得到一个
f位的二进制串(如0101...1101),这就是文档的SimHash指纹。
- 特征提取: 将文档分词,提取特征(通常是词)及其权重(可以是词频、TF-IDF等)。得到特征-权重对
- 关键性质: 两个原始向量的余弦相似度越高,它们对应的SimHash指纹之间的海明距离就越小。存在理论上的概率保证。
- 如何用于LSH(分桶):
- 目标: 把海明距离小于某个阈值
d的指纹对(即原始向量相似度高)找出来。 - 方法: 有多种分桶策略,一种常见且高效的是多表索引:
- 投影(Projection): 将
f位的指纹分成k个不相交的片段(称为“关键码”或“索引码”)。例如,一个64位指纹分成4个16位的片段。 - 分桶: 对每个片段位置(如第1个16位、第2个16位…),建立一个独立的哈希表。
- 存储: 对于一个指纹
F:- 将其
k个片段分别作为k个哈希表的键(Key)。 - 将指向原始数据(或ID)的指针放入这
k个哈希表中对应键的桶里。(同一个数据点会被放入k个桶)
- 将其
- 查询: 对于查询指纹
Q:- 同样将其分成
k个片段。 - 分别用这
k个片段作为键,去对应的k个哈希表里查找。 - 把
k个桶里找到的所有数据点的指针合并起来,作为候选集。
- 同样将其分成
- 原理: 如果两个指纹的海明距离很小(很相似),那么它们有很大概率在至少一个片段上完全相同(因为海明距离小意味着大部分比特相同,而片段是随机划分的,相同的部分很可能落在同一个片段内)。因此,相似的指纹有很大概率在至少一个桶里发生碰撞。
- 投影(Projection): 将
- 调参:
k(片段数/表数)和片段长度影响召回率和精度。k越大,召回率越高(因为碰撞机会多),但桶的数量也越多,内存开销和候选集可能变大。片段长度越短,碰撞越容易(召回高精度低);越长,碰撞越难(召回低精度高)。
- 目标: 把海明距离小于某个阈值
- 应用场景: 大规模网页去重(检测内容相似的网页)、论文查重、新闻聚合(聚合报道同一事件的新闻)。Google 爬虫使用该算法来查找接近重复的页面。
简单比喻:
想象给每篇文档拍一个“模糊照片”(SimHash指纹):
- 文档里的每个词(特征)根据它的重要性(权重)投出一张模糊的选票(加权哈希),这张选票上画满了
f个小格子(比特位),有些格子标+(1),有些标-(0)。 - 把所有词的选票叠在一起。对于每个小格子:
- 如果总的“+”票多于“-”票,照片的这个格子涂黑(1)。
- 如果总的“-”票多于“+”票,照片的这个格子留白(0)。
- 最终得到一张黑白格子组成的照片(二进制指纹)。内容相似的文章,拍出来的照片(指纹)看起来也相似(海明距离小)。
- LSH分桶:把这张照片切成
k个条带(片段)。规定:只要两篇文章的照片有任意一个条带完全一样,就把它们当成“可能相似”的候选文章,放到一起待查。
总结与比较
| 特性 | LSH (框架) | MinHash (具体LSH实现) | SimHash (具体LSH实现) |
|---|---|---|---|
| 核心目标 | 快速近似近邻搜索 | 快速估计集合的Jaccard相似度 | 快速估计高维向量的余弦相似度 |
| 数据表示 | 取决于具体实现 | 集合 (元素) | 高维特征向量 (特征+权重) |
| 相似度度量 | 取决于具体实现 | Jaccard相似系数( | 余弦相似度 / 海明距离 |
| 输出 | 桶ID / 哈希签名 (用于分桶) | MinHash签名 (整数向量) | SimHash指纹 (固定长度二进制串) |
| 关键性质 | 相似点高概率同桶/签名接近 | P(m(A)=m(B)) = Jaccard(A,B) | 原始向量相似度高 => 指纹海明距离小 |
| 主要应用 | 海量数据近邻搜索、去重、聚类 | 文档去重、推荐(用户-物品集合)、基因 | 网页/文档去重、查重、新闻聚合 |
| 分桶方式 | 取决于具体实现 | Band Partition | 多表索引 (按片段分桶) |
| 优势 | 框架通用,大幅降低比较次数 | 理论漂亮,直接估计Jaccard | 指纹紧凑,海明距离计算快 |
| 权衡 | 概率性(假阴/假阳),需调参 | 签名较长,存储开销可能大 | 对特征权重敏感 |
核心思想再强调:
- LSH 是指导思想: 设计哈希函数,让相似的东西有高概率“撞”到一起(得到相同/相近的哈希值或桶ID),从而可以只在小范围内进行精确比较。
- MinHash 是 LSH 的“打集合相似度”专家: 专门解决“这两个集合(比如购物车、词袋)有多像?”的问题,用签名相等比例估计Jaccard相似度。
- SimHash 是 LSH 的“打高维向量相似度”专家: 专门解决“这两个高维向量(比如TF-IDF向量)有多像?”的问题,把向量压缩成指纹,用指纹的海明距离反映原始余弦相似度。
通过利用 LSH 的思想,以及 MinHash 或 SimHash 这样的具体工具,我们就能在浩瀚的数据海洋中,高效地捞出那些“相似”的鱼儿。万篇文档,或者几亿个用户的行为记录。你想找出相似的图片、相似的文档,或者兴趣相似的用户。如果每对数据都去精确计算它们的相似度(比如余弦相似度、Jaccard相似系数),那计算量是天文数字。这就是 LSH 这类技术大展身手的地方。
rust开源实现:https://github.com/serega/gaoya
ImgHash: aHash、dHash、pHash、Blockhash
MinHash和SimHash是针对文本的LSH算法,但是用在图片上会有问题:
如果我们把图像像素直接当作特征,塞进 SimHash,有几个问题:
- 高维且稠密
- 图像动辄几十万像素,每个像素都是实数(RGB),不是稀疏的离散词。
- SimHash 对这种输入会“淹没”在噪声里,无法得到稳定的签名。
- 不具备语义稳定性
- 一张图亮度调高 10%,像素整体偏大,但语义完全没变。
- SimHash 会得到完全不同的 bit 向量(不鲁棒)。
- 缺乏视觉先验
- 文本中“词序变化”对语义影响小,SimHash 能容忍。
- 图像中旋转、缩放、裁剪很常见,SimHash 没有机制去消除这种变化。
aHash (Average Hash, 平均哈希)
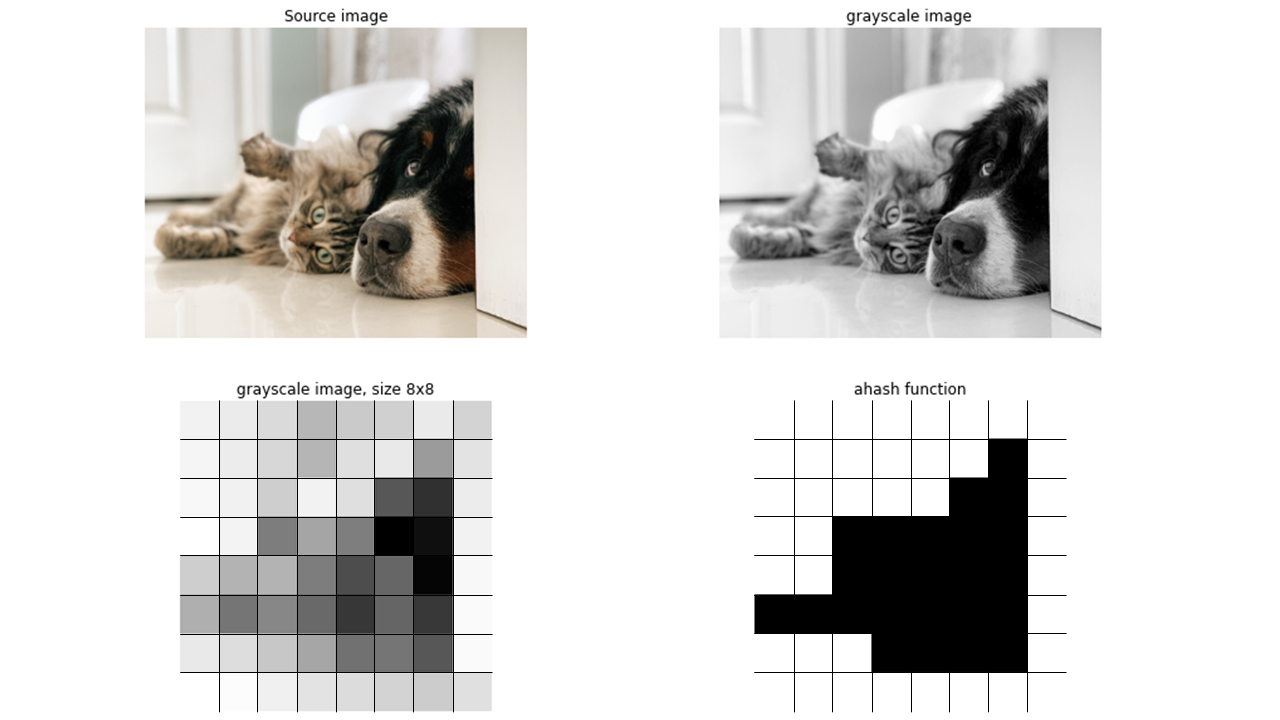
原理
- 将图片缩小为 8×8(或其他固定尺寸),转为灰度图。
- 计算所有像素的平均灰度值。
- 大于等于平均值 → 记 1;小于 → 记 0。
- 得到一个 64-bit 的签名。
特点
- 简单快速,鲁棒性好(缩放、轻微压缩)。
- 对亮度、对比度调整比较敏感。
适用场景
- 快速去重、找完全相同或轻微编辑的图。
pHash (Perceptual Hash, 感知哈希)

原理
- 将图片缩小为 32×32,转为灰度。
- 计算 DCT(离散余弦变换)。
- 取左上角 8×8 的低频部分(去掉 DC 分量)。
- 比较每个系数与平均值 → 得到 64-bit 哈希。
特点
- 提取频域信息,更关注图像结构而不是亮度。
- 对亮度/对比度变化鲁棒。
- 更复杂计算,但效果好。
适用场景
- 相似图片检测(不同颜色、轻微编辑、加水印)。
dHash (Difference Hash, 差异哈希)
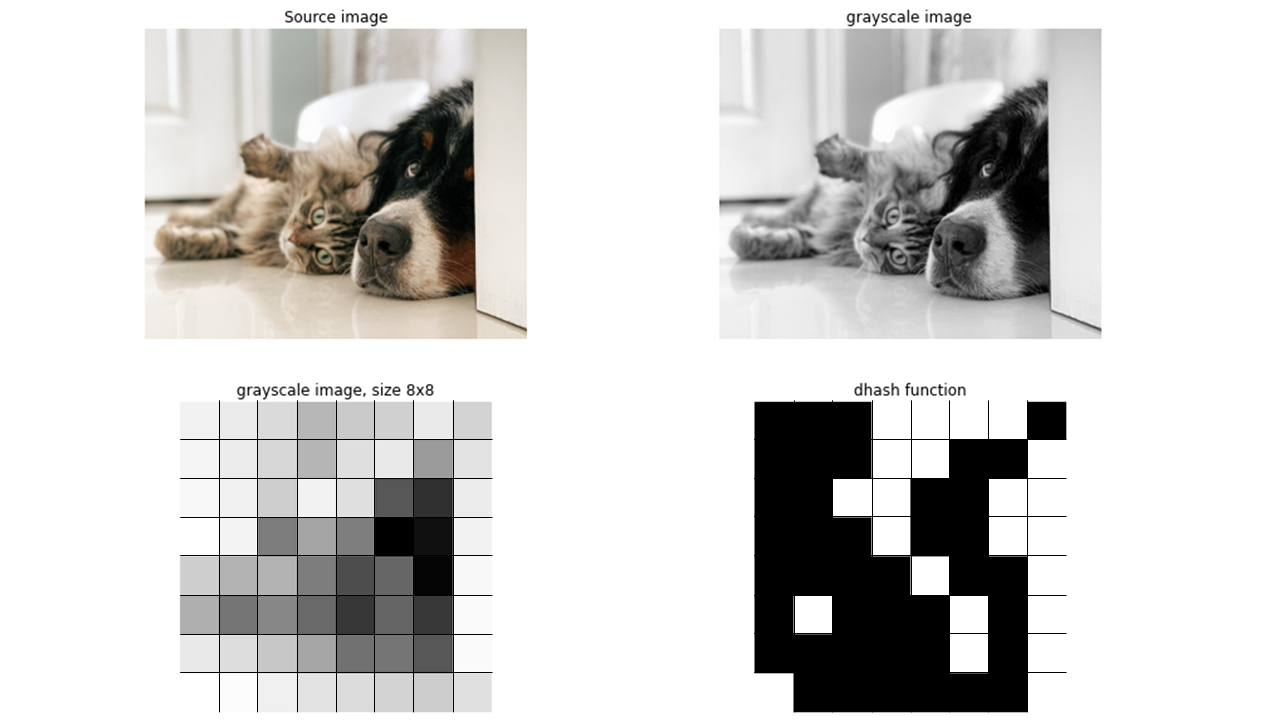
原理
- 将图片缩小为 9×8,转为灰度。
- 按行比较相邻像素:如果左像素 > 右像素 → 1,否则 0。
- 得到 64-bit 哈希。
特点
- 捕捉边缘/梯度特征,比 aHash 更鲁棒。
- 对旋转敏感。
- 算法简单,速度快。
适用场景
- 图片去重、快速相似度检索。
在开源的imgHash库中提供了三类dHash的实现
🔹 1. Gradient (水平差异哈希,类似 dHash)
原理
- 把图缩小为 9×8,转为灰度。
- 逐行比较相邻像素:如果
左 > 右→ 1,否则 → 0。 - 得到 8×8 = 64 bit 哈希。
特点
- 捕捉 水平边缘 信息。
- 类似经典的 dHash。
- 对缩放、亮度变化鲁棒,但对 旋转 较敏感。
🔹 2. VertGradient (垂直差异哈希)
原理
- 把图缩小为 8×9,转为灰度。
- 逐列比较相邻像素:如果
上 > 下→ 1,否则 → 0。 - 得到 8×8 = 64 bit 哈希。
特点
- 捕捉 垂直边缘 信息。
- 能弥补
Gradient的不足。 - 对垂直翻转/上下裁剪更鲁棒。
🔹 3. DoubleGradient (双向差异哈希)
原理
- 直接结合了
Gradient和VertGradient。 - 得到 128 bit 哈希(水平 64bit + 垂直 64bit)。
特点
- 综合水平与垂直信息,更稳健。
- 相比单一梯度,更抗旋转、抗噪声。
- 计算稍慢,但信息量更丰富。
📊 总结表
| 算法 | 对应概念 | 提取特征 | 哈希长度 | 优点 | 缺点 |
|---|---|---|---|---|---|
| Gradient | dHash | 水平梯度 | 64 bit | 简单、快 | 对旋转敏感 |
| VertGradient | 垂直 dHash | 垂直梯度 | 64 bit | 补充水平不足 | 单向信息 |
| DoubleGradient | dHash 组合 | 水平+垂直 | 128 bit | 更稳健、信息丰富 | 比较慢 |
Gradient= 水平版 dHashVertGradient= 垂直版 dHashDoubleGradient= 两者拼接,效果更强
Blockhash
原理
- 将图像划分为 n×n 块。
- 计算每个块的平均灰度。
- 和全图的平均灰度或局部比较,生成 bit。
- 得到一个更长的指纹(一般 256bit 或 1024bit)。
特点
- 通过块结构提高鲁棒性,能适应更复杂的场景。
- 比 aHash/dHash/pHash 更“精细”,但计算更慢。
适用场景
- 大规模图片库去重(比如几千万张图)。
- 需要更高精度的场景(比如图库版权检测)。
总结对比表
| 算法 | 核心思路 | 长度 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|---|
| aHash | 平均灰度 | 64bit | 快速、简单 | 对亮度敏感 | 基础去重 |
| pHash | DCT 低频 | 64bit | 结构特征强、鲁棒性好 | 较慢 | 相似图检测 |
| dHash | 邻像素差 | 64bit | 快速、边缘特征 | 旋转敏感 | 相似度检索 |
| Blockhash | 分块均值 | 256–1024bit | 鲁棒性强、精度高 | 计算量大 | 海量图库去重 |
👉 可以这么理解:
- aHash:像“全局亮度签名”
- dHash:像“边缘签名”
- pHash:像“图像结构签名”
- Blockhash:像“局部块特征签名”

