之前在用SeaORM来进行数据持久化,一直没有什么好的解决方案来集成PgVector合SeaORM,这两天在讨论区 看到一篇文章:Using pgVector with SeaORM in Rust
这篇文章值得学习一下
PGVector 与 Rust 中的 SeaORM 现在是 2025 年,大型语言模型风靡一时,但不加选择地使用它们可能会付出高昂的代价。Vector Search 是一种有助于减少冗余并最大限度地减少资源消耗的技术。
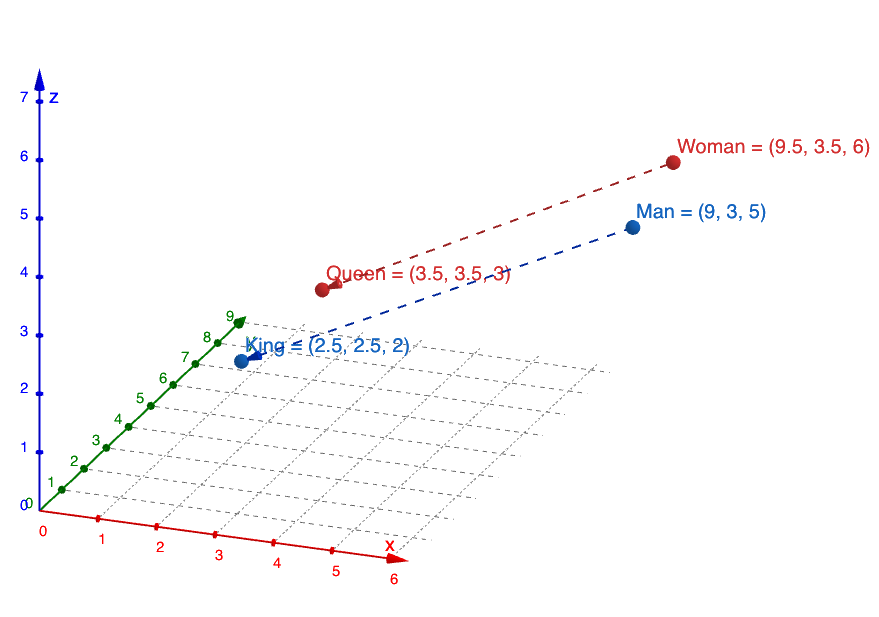
封面图像是嵌入向量背后的直觉的可视化,其中相似的概念在向量空间中被分组在一起,这进一步允许观察到有趣的关系。在这种情况下,无处不在的例子是 King – Man + Woman = Queen。
PGVector 是一个 PostgreSQL 扩展,允许有效地存储和查询矢量数据。它支持向量作并允许对向量进行索引。它本质上通过向量运算增强了 PostgreSQL,有效地将其转变为向量数据库。
另一方面,SeaORM 是支持 PostgreSQL 等数据库的 Rust ORM。SeaORM 是一个易于使用的库,在 Rust 社区中获得了持续的关注。它得到了积极的维护,拥有出色的文档和不断增长的社区支持。
准备 我们希望使这尽可能简单,因此我们将使用 Docker 启动安装了 pgvector 的 PostgreSQL 实例。
对于生产工作负载,您可以在 PostgreSQL 实例上安装 pgvector 扩展,但这不在本文的讨论范围之内。您还可以使用支持自定义扩展的托管 PostgreSQL 服务,包括 pgvector。其中一项服务是 AWS RDS,它允许在 PostgreSQL 实例上启用 pgvector。我将在此处介绍的方法也可以与 AWS RDS 一起使用。
继续并启动安装了 pgvector 的 PostgreSQL 实例:
1 2 3 4 5 6 docker run \ --rm -d \ --name pgvector \ -p 5432:5432 \ -e POSTGRES_PASSWORD=postgres \ pgvector/pgvector:pg16
我们将使用 Terraform 来设置数据库,因此请确保您已安装该数据库。创建一个包含提供程序配置的 provider.tf 文件。我们使用 postgresql 提供程序来管理数据库(包括扩展),并使用 sql 提供程序来运行迁移,这将设置数据库架构。使用的凭据是默认凭据,我们也使用默认数据库。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 terraform { required_version = ">= 1" required_providers { postgresql = { source = "cyrilgdn/postgresql" version = ">= 1.25" } sql = { source = "paultyng/sql" version = ">= 0" } } } provider "postgresql" { host = "localhost" username = "postgres" password = "postgres" sslmode = "disable" } provider "sql" { url = "postgres://postgres:postgres@localhost:5432/postgres" }
创建一个包含数据库设置和迁移的 main.tf 文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 resource "postgresql_extension" "pgvector" { database = "postgres" name = "vector" } resource "sql_migrate" "m0" { depends_on = [postgresql_extension.pgvector] migration { id = "m0" up = <<SQL CREATE TABLE public.embeddings ( id SERIAL PRIMARY KEY, embedding VECTOR(4) ); SQL down = "DROP TABLE IF EXISTS public.embeddings;" } }
首先,postgres 数据库中启用了 pgvector 扩展。
接下来,创建表嵌入。此表将存储嵌入,即 4 维向量。在实际场景中,嵌入的维数会高得多,但为了简单起见,我们在本例中只使用 4 个维度。请注意,VECTOR 类型是 pgvector 特定类型。
要配置数据库并创建表,请在您创建上述 *.tf 文件的文件夹中运行以下命令。
这只是为了确保您从头开始。
1 2 3 4 5 rm -rf \ .terraform \ .terraform.tfstate \ terraform.tfstate.backup \ .terraform.lock.hcl
现在,初始化 Terraform 项目并应用更改。
1 2 terraform init terraform apply --auto-approve
如果您连接到数据库并检查它,您会注意到一些 pgvector 特定的元素。
先决条件现已满足,我们可以开始查看一些 Rust 代码 :smiling-ferris-emoticon:
代码 首先让我们创建一个新的 Rust 项目。为此我们将使用 Cargo。我假设您已经在这里安装了 Rust 工具链。
1 2 cargo new pgvector-seaorm cd pgvector-seaorm
将所需的依赖项添加到 Cargo.toml 文件。
1 2 3 [dependencies] sea-orm = { version = "1" , features = ["sqlx-postgres" , "runtime-tokio-native-tls" ] }tokio = { version = "1" , features = ["rt" , "rt-multi-thread" , "macros" ] }
tokio 是 sea-orm 使用的异步运行时,在 Rust 异步生态系统中无处不在。
PgVector newtype 我们将使用一个新类型来更优雅地表示嵌入。创建一个新文件 src/pg_vector.rs 并添加以下代码。
1 2 3 4 use sea_orm::DeriveValueType;#[derive(Clone, Debug, PartialEq, DeriveValueType)] pub struct PgVector (pub Vec <f32 >);
数据库表模型 我们需要定义一个表示嵌入表中实体的模型。为此,创建一个新文件 src/embedding.rs 并添加以下代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 use crate::pg_vector::PgVector;use sea_orm::entity::prelude::*;#[derive(Clone, Debug, DeriveEntityModel)] #[sea_orm(table_name = "embeddings" )] pub struct Model { #[sea_orm(primary_key, auto_increment = true)] pub id: i32 , #[sea_orm(select_as = "FLOAT4[]" )] pub embedding: PgVector, } #[derive(Copy, Clone, Debug, EnumIter, DeriveRelation)] pub enum Relation {}impl ActiveModelBehavior for ActiveModel {}
大多数细节和注释都是不言自明的。
然而,需要注意的是,SeaORM 本身并不支持 VECTOR 类型。因此,如果没有 select_as 注释,SeaORM 将无法正确映射到 PgVector 类型。为了实现这一点,我们使用 select_as 注释来告诉 SeaORM 将嵌入列从 VECTOR 转换为 FLOAT4[]。这样 SeaORM 就可以正确地将列映射到 PgVector 类型。
查询数据库 我们现在将编写一些代码来与数据库交互。使用以下代码覆盖 src/main.rs 文件的内容。
建立连接 一些 use 语句尚未使用,但将会使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 mod embedding;mod pg_vector;use pg_vector::PgVector;use sea_orm::sea_query::OnConflict;use sea_orm::{Database, DbBackend, EntityTrait, FromQueryResult, JsonValue, Set, Statement};#[tokio::main] async fn main () -> Result <(), Box <dyn std::error::Error>> { let db = Database::connect ("postgres://postgres:postgres@localhost:5432/postgres" ).await ?; Ok (()) }
插入数据 我们现在将一些数据插入到嵌入表中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 let vectors = vec! [ embedding::ActiveModel { id: Set (1 ), embedding: Set (PgVector (vec! [0.1 , 0.8 , 0.5 , 0.3 ])), }, embedding::ActiveModel { id: Set (2 ), embedding: Set (PgVector (vec! [0.4 , 0.2 , 0.7 , 0.9 ])), }, embedding::ActiveModel { id: Set (3 ), embedding: Set (PgVector (vec! [0.9 , 0.5 , 0.1 , 0.6 ])), }, ]; embedding::Entity::insert_many (vectors) .on_conflict ( OnConflict::column (embedding::Column::Id) .update_column (embedding::Column::Embedding) .to_owned (), ) .exec (&db) .await ?;
获取所有数据 我们现在将查询数据库以获取所有嵌入。
1 2 3 4 5 6 7 embedding::Entity::find () .all (&db) .await ? .iter () .for_each(|embedding| { dbg!(embedding); });
你应该得到这个输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 [src/main.rs:42:13] embedding = Model { id: 1, embedding: PgVector( [ 0.1, 0.8, 0.5, 0.3, ], ), } [src/main.rs:42:13] embedding = Model { id: 2, embedding: PgVector( [ 0.4, 0.2, 0.7, 0.9, ], ), } [src/main.rs:42:13] embedding = Model { id: 3, embedding: PgVector( [ 0.9, 0.5, 0.1, 0.6, ], ), }
PGVector 操作 更有趣的是使用 pgvector 提供的向量操作。此查询获取给定向量的最近邻居。
使用 pgvector 特定的构造 <-> 来计算向量之间的距离。 将向量转换为 FLOAT4[],以便允许 SeaORM 将数据转换为 embedding::Model 使用的 PgVector 类型。同样,如果不使用转换,SeaORM 将无法使用 VECTOR 类型。 1 2 3 4 5 6 7 8 9 10 11 embedding::Entity::find () .from_raw_sql (Statement::from_sql_and_values ( DbBackend::Postgres, r#"SELECT "id", "embedding"::FLOAT4[] FROM "public"."embeddings" ORDER BY "embedding" <-> $1::VECTOR LIMIT 1"# , [PgVector (vec! [0.3 , 0.1 , 0.6 , 0.5 ]).into ()], )) .one (&db) .await ? .iter ().for_each(|embedding| { dbg!(embedding); });
结果是:
1 2 3 4 5 6 7 8 9 10 11 [src/main.rs:55:13] embedding = Model { id: 2, embedding: PgVector( [ 0.4, 0.2, 0.7, 0.9, ], ), }
最后我们举例说明如何获取两个向量之间的距离:
1 2 3 4 5 6 7 8 9 10 11 JsonValue::find_by_statement (Statement::from_sql_and_values ( DbBackend::Postgres, r#"SELECT "embedding" <-> '[0.5, 0.8, 0.0, -0.6]' AS "distance" FROM "public"."embeddings";"# , [], )) .all (&db) .await ? .iter () .for_each(|distance| { dbg!(distance); });
结果是:
1 2 3 4 5 6 7 8 9 [src/main.rs:68:9] distance = Object { "distance": Number(1.1045361146699684), } [src/main.rs:68:9] distance = Object { "distance": Number(1.7635192467093759), } [src/main.rs:68:9] distance = Object { "distance": Number(1.3038404993264), }
您会注意到,在这种情况下不需要将向量转换为 FLOAT4[],因为没有选择 VECTOR 类型的列进行检索。
结论 在 Rust 中将 pgvector 与 SeaORM 结合使用是一种强大的组合。只需做两件事即可实现此目的:
使用 select_as = “FLOAT4[]” 注释引用 VECTOR 类型的模型列。 当选择 VECTOR 类型的列以便通过 SeaORM 进行检索时,将 VECTOR 类型转换为 FLOAT4[]。 我还创建了一个包含完整代码的支持 GitHub 存储库 。
github上的代码仓库已经没有了