分库分表这个技术在之前一家公司其实也有接触。上一家公司在业务上按照用户水平分库的,所以避免了很多业务上的问题,但也只是基于Spring的AbstractRoutingDataSource,根据userId做了简单的路由。之前也在网上听说过sharding-jdbc等中间件,也仅限于了解。所以结合我从内网看到的关于TDDL中间件的文章和外网看到的一些文章,在这篇文章中整理一下我这个新人对分库分表的认识。
1、单库单表
刚开始的时候,应用的数据比较少,业务也不会特别复杂,所以应用只有一个数据库,数据库中的每一张表都是完整的数据,这也是数据库的最初形态。
2、读写分离
随着业务发展,数据量和访问量都不断增长,但大多数业务都是读多写少。比如新闻网站的新闻、购物网站的商品,运营人员在后台编辑好后,所有的互联网用户都可能会去读取这些数据,因此数据库面临的读压力远大于写压力。这个时候在原来数据库(Master)基础上增加一个备用数据库(Slave),备库和主库存储相同的数据,但只提供读服务,不提供写服务。写操作以及事务中的读操作走主库,其他读操作走备库,这样就实现了读写分离。在实现读写分离的基础上也能避免单机故障,导致无法对外提供服务。主数据库宕机,可以自动切换到备库,以实现系统容灾。
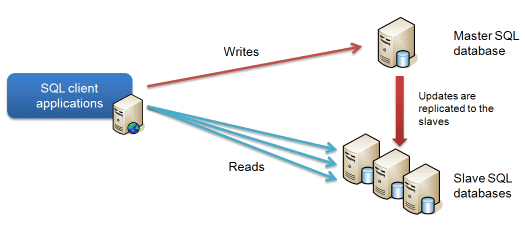
读写分离带来的问题:
- 数据的复制:新写入的数据只会在主库中,备库需要将数据的新增和修改从主库中复制过来。这个一般依靠数据库提供的复制功能实现,比如mysql基于binlog实现的的replication。
- 数据源的选择:读写分离后,我们都知道写要找主库,读要找备库,但是程序不知道。所以程序中应该根据SQL判断出是读操作还是写操作,进而选择要访问的数据库。这就涉及到SQL语法树的解析了,比如Druid连接池就提供了SQL Parser模块。
3、垂直分库
数据量和访问量仍在持续上升,主备库的压力都在上升。这时可以根据业务特点考虑将数据库进行功能性拆分,也就是把数据库中不同业务单元的数据表划分到不同的数据库中。
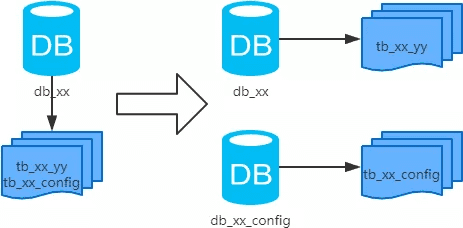
比如新闻网站中,注册用户的信息与新闻数据是没有多大关系的,数据库访问压力大时可以尝试把用户注册信息的表放在一个数据库,新闻相关的表放在另一个数据库中,这样减小了数据库的访问压力,同时便于对每个单独的业务按需进行水平扩展。这就与微服务的思想逐渐靠近,但具体业务拆分如何拆分,怎么控制拆分粒度,这需要根据业务进行仔细考量了。因为垂直分库会带来以下几个问题:
- 事务的ACID将被打破:数据被分到不同的数据库,原来的事务操作将会受很大影响。比如说注册用户时需要在一个事务中往用户表和用户信息表插入一条数据,单机数据库可以利用本地事务很好地完成这件事儿,但是多机就会变得比较麻烦。这个问题就涉及到分布式事务,分布式事务的解决方案有很多,比如使用强一致性的分布式事务框架Seata,或者使用RocketMQ等消息队列实现最终一致性。
- Join联表操作困难:这个也毋庸置疑了,解决方案一般是将联表查询改成多个单次查询,在代码层进行关联。
- 外键约束受影响:因为外键约束和唯一性约束一样本质还是依靠索引实现的,所以分库后外键约束也会收到影响。但外键约束本就不太推荐使用,一般都是在代码层进行约束,这个问题倒也不会有很大影响。
4、垂直分表
除了垂直分库还有垂直分表的方式:主要以字段为依据,按照字段的活跃度,将表中的字段拆分到不同的表中。将热点数据(可能会冗余经常一起查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表。这样主表的单行数据所需的存储空间变小,更多的热点数据就能被缓存下来,进而减少了随机磁盘I/O。拆了之后,要想获得全部数据就需要关联两个表来取数据。
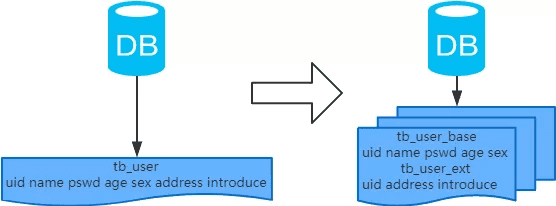
比如用户表数据,用户的用户名、密码、年龄、性别、手机号等字段会被经常查询,而用户的家庭住址、个人介绍等字段又长而且不常访问,所以将这些字段拆分出来单独存一张表,可以让数据库的缓存更高效。
5、水平分库分表
数据量继续增长,特别对于电商、社交媒体这样的UGC(User Generated Content)业务,数据增长会随着业务扩大达到惊人的地步,每张表都存放着大量的数据,任何CRUD都将变成一次极其消耗性能的操作。
以MySQL为例进行简单的估算,假设主键使用8字节的bigint形式存储,InnoDB默认页大小为16KB,一页能存
根据推算一页能存下大概1000个Key。
根据B+树的结构,不考虑InnoDB的聚簇索引为了后续插入和修改预留的
我们先考虑主键是随机插入的最差情况
最好的情况下主键单调递增插入
假如MySQL服务器有足够的内存能将前三层索引缓存在内存中,索引只有三层,那么通过聚簇索引访问数据只需一次磁盘I/O。而当我们数据量过大,索引层级达到四层或四层以上时,通过聚簇索引访问就需要两次以上的磁盘I/O了。
所以当数据达到一定量级后,水平拆分显得尤为重要——将一张大表拆分成多张结构相同的子表。
比如将一张5千万的用户表水平拆分成5张表后,每张表只有1千万的数据。
不过水平拆分有两种策略:
5.1、水平分表
水平分表——以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
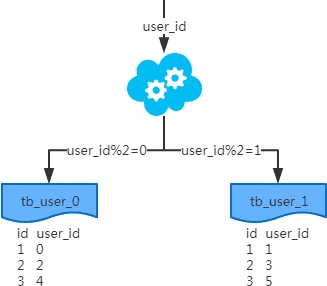
其实MySQL的分区表能提供类似的功能。区别在于MySQL底层会自动分成多个文件存储,而手动分表需要在代码层改写SQL,根据分表字段映射到真正的表名。显然后者成本有点高。
分表能够解决单表数据量过大带来的查询效率下降的问题,但是却无法给数据库的并发处理能力带来质的提升。所以这个适合数据量上来但是并发访问量没上来的情况。
我上一家公司做的系统其实就是这一类型,数据量很大,但是访问量很小。但是我们并没有采用水平分表的策略,而是使用水平分库。由于MySQL实例进程支持多个数据库,我们将多个库分配在同一个数据库实例上以共享数据库硬件资源。一方面方便后续拆分成多个数据库实例,一方面避免了前面说的表名映射问题。
5.2、水平分库

这种方式明显更容易扩展——库多了,io和cpu的压力自然可以成倍缓解。
5.3、水平分库分表带来的问题
自增主键会有影响:分表中如果使用的是自增主键的话,那么就不能产生唯一的 ID 了,因为逻辑上来说多个分表其实都属于一张表,数据库的自增主键无法标识每一条数据。一般采用分布式的id生成策略解决这个问题。
比如我上一家公司在分库之上有一个目录库,里面存了数据量不是很大的系统公共信息,其中包括一张类似于Oracle的sequence的
hibernate_sequence表用于实现的id序列生成。有些单表查询会变成多表:比如说 count 操作,原来是一张表的问题,现在要从多张分表中共同查询才能得到结果。
排序和分页影响较大:比如
order by id limit 10按照10个一页取出第一页,原来只需要一张表执行直接返回给用户,现在有5个分库要从5张分表分别拿出10条数据然后排序,返回50条数据中最前面的10条。当翻到第二页的时候,需要每张表拿出20条数据然后排序,返回100条数据中的第二个11~20条。很明显这个操作非常损耗性能。
6、分库扩容问题
通常为了保证数据平均分配在多个分库中大多会采用hash的方式进行水平分库。
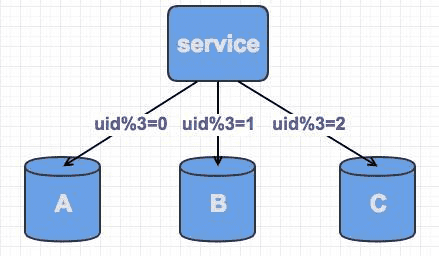
当数据量上涨后,容量无法支撑需要扩容,在原来的基础上再加一个库。
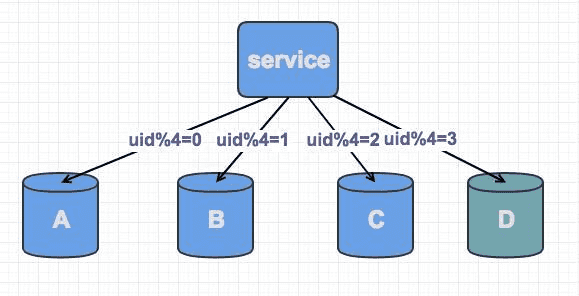
不过此时由于分片规则进行了变化(uid%3 变为uid%4),大部分的数据,无法命中在原有的数据库上了,需要重新分配,大量数据需要迁移。
6.1、一致性Hash
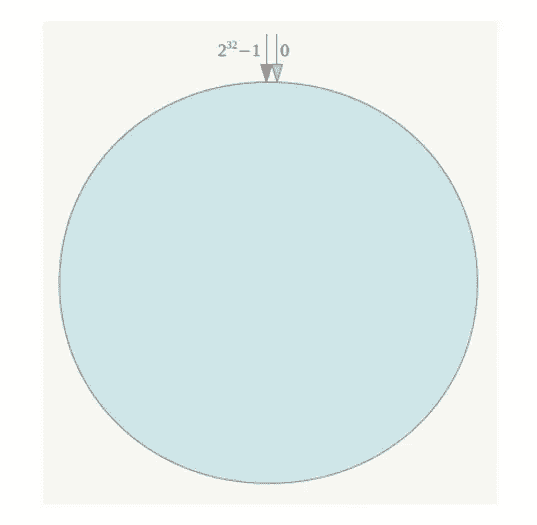
一致性Hash是麻省理工的David Karger教授在一篇论文中提出来的,现在被用在很多分布式系统中。
简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下:
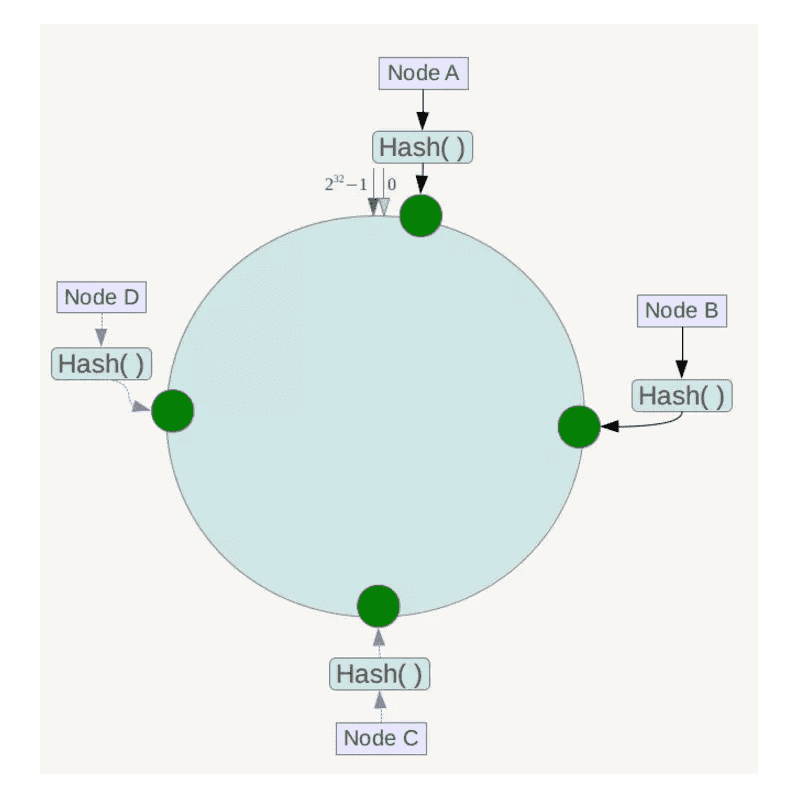
将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
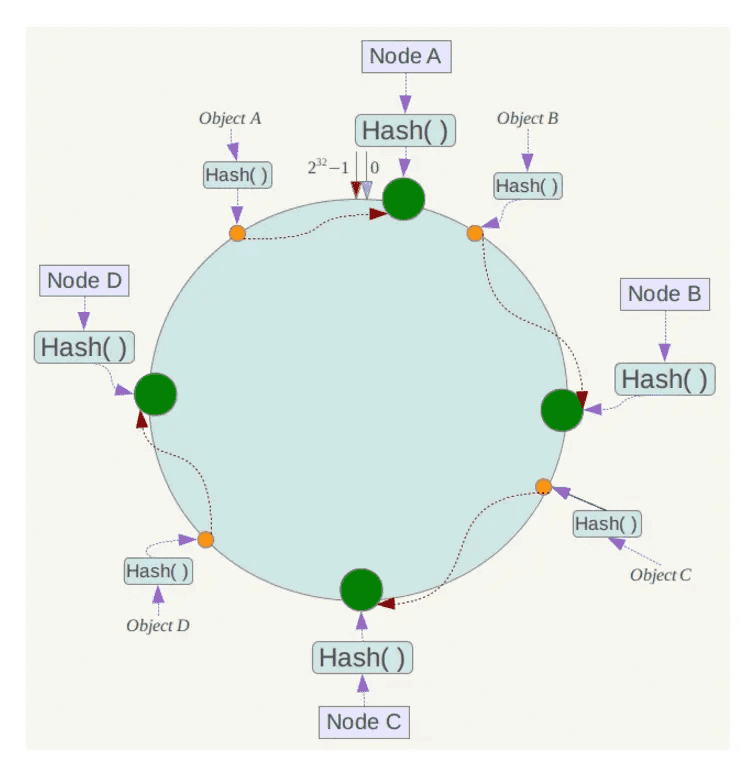
一致性哈希算法的容错性:
假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
一致性哈希算法的可扩展性:
如果在系统中增加一台服务器Node X,如下图所示:
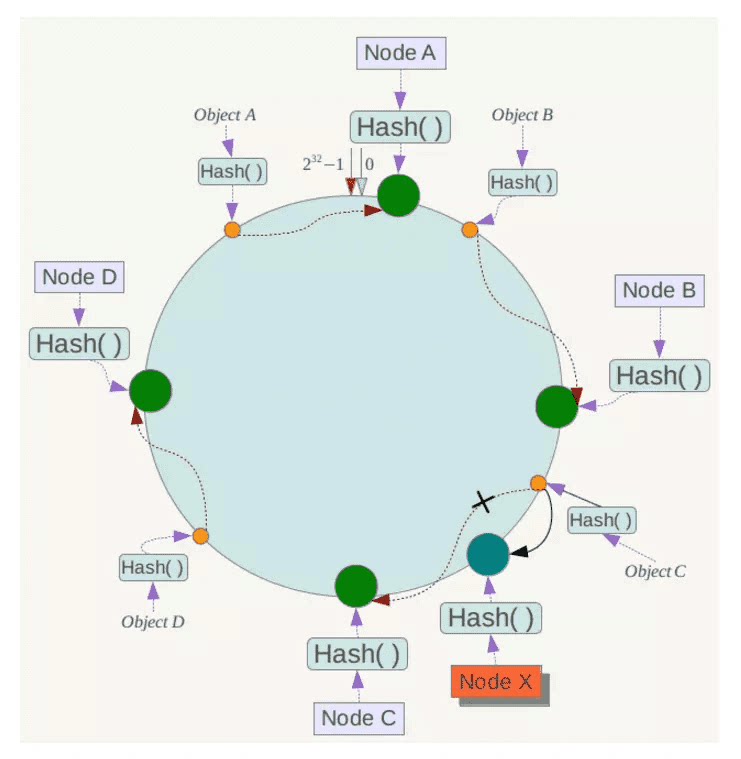
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。
另外,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务器,其环分布如下:
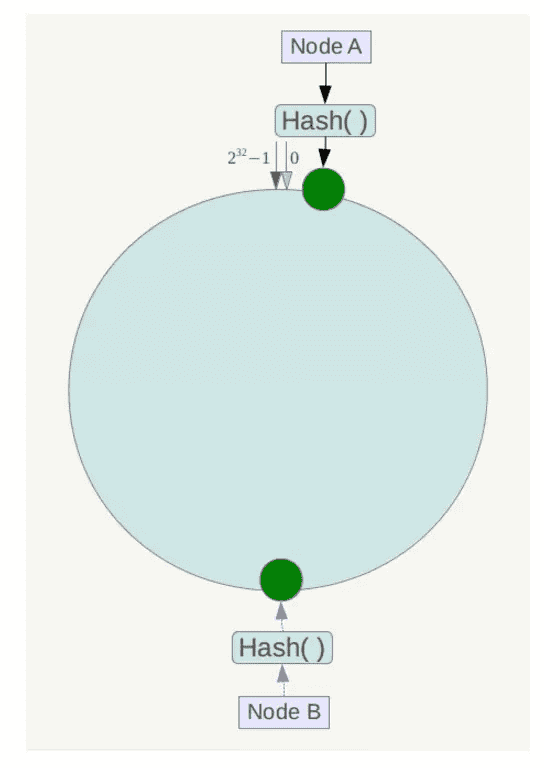
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
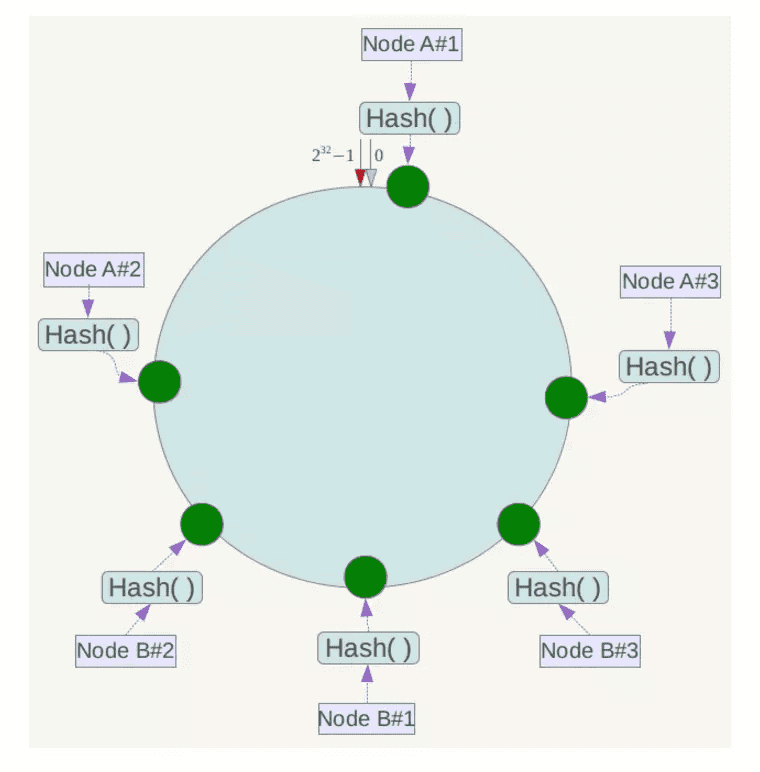
下面是Java语言的实现代码(Wikipedia上还有其他语言的实现):
1 | import java.util.Collection; |
7、分库分表中间件——TDDL
可以看出,数据库从单机走向分布式将会面临很多的问题。TDDL就是解决这个问题而生的。
TDDL(Taobao Distribute Data Layer)是整个淘宝数据库体系里面具有非常重要的一个中间件产品,在公司内部具有广泛的使用。我已知的市面上两个开源数据库中间件sharding-sphere和mycat也是解决这一问题的。
TDDL基于JDBC Driver之上,所以下层可以支持多种数据库类型。整个中间件实现了 JDBC规范,开发可以和往常一样使用JDBC Tempalte、MyBatis、Hibernate ORM等各种持久层技术。
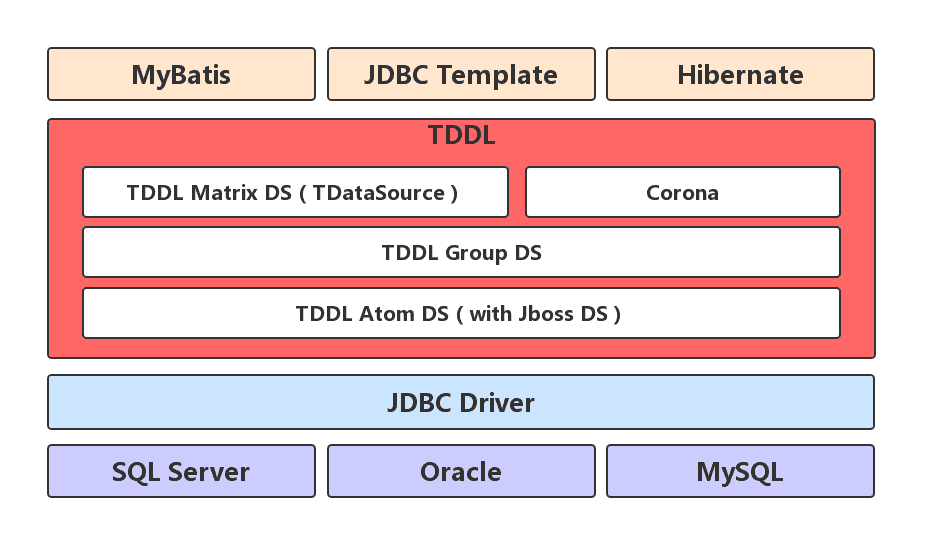
7.1、TDDL基本架构
TDDL主要分成三层:Matrix层、Group层、Atom层,分别对应TDataSource、TGroupDataSource、TAtomDataSource。
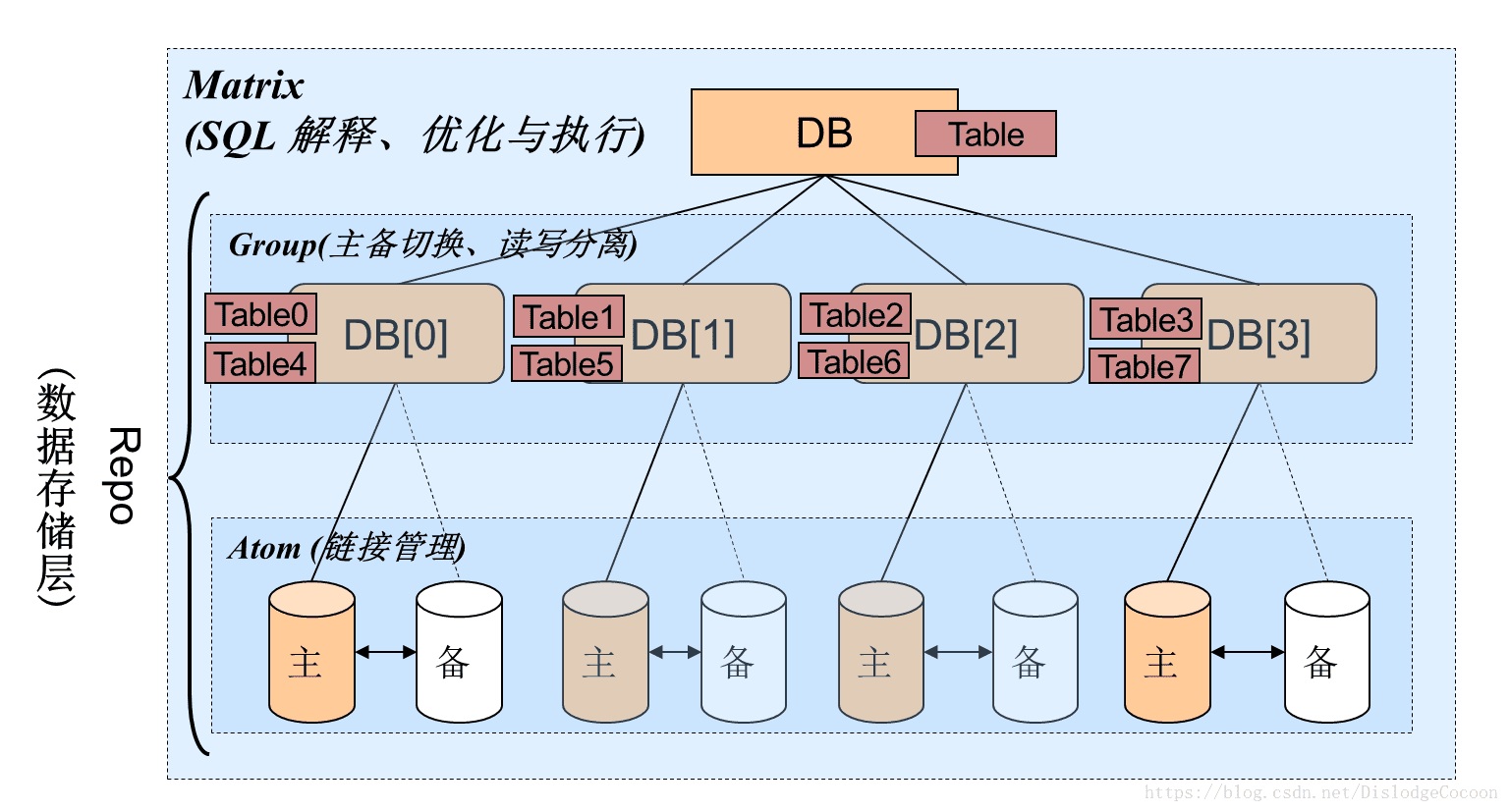
1、Matrix层(TDataSource)
- 实现分库分表,支持多个Group
- SQL的解释、优化、执行
- 规则管理
- Atom执行结果的合并
2、Group层(TGroupDataSource)
- 持有多个Atom
- 读写分离、主备切换
- 权重选择、重试策略
3、Atom层(TAtomDataSource)
- 数据源信息(ip、port、password)管理,可动态修改数据源
- 连接池管理
- 默认使用DruidDataSource
7.2、TDDL相关配置
可以通过文件形式配置spring.tddl.*的property。具体可以参看TddlAutoConfiguration、TddlJdbcAutoConfiguration、TddlSpringAutoConfiguration相关代码。这种方式不太推荐。TDDL主要还是用Diamond来提供各种配置信息。
参考资料:
TDDL 基础:https://www.atatech.org/articles/59193
认识 TDDL 数据层:https://www.atatech.org/articles/153342
TDDL:来自淘宝的分布式数据层:https://www.biaodianfu.com/tddl.html
TDDL动态数据源开源-基本说明:http://jm.taobao.org/2012/04/27/tddl-open-source-intro/
分布式数据库中间件—TDDL的使用介绍:https://www.2cto.com/database/201806/752199.html
MySQL:互联网公司常用分库分表方案汇总:https://yq.aliyun.com/articles/752683
十分钟入门RocketMQ:http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/
InnoDB物理结构:https://dev.mysql.com/doc/refman/8.0/en/innodb-physical-structure.html
分库分表平滑扩容:https://www.cnblogs.com/barrywxx/p/11532122.html
五分钟看懂一致性哈希算法:https://juejin.im/post/5ae1476ef265da0b8d419ef2

