Java提供给我们软件国际化的解决方案,这些国际化API基于Unicode标准,并且包括文本、(货币)数字、日期以及用户自定义对象的适配,从而使得软件能够应用到任何国家或地区。国际化英文为“Internationalization”,通常简写成i18n(实际开发经常使用简写)。更多有关Java国际化的内容可以参考Oracle的相关网站 。
文字国际化 Java语言基于Unicode字符集。Unicode是一种国际字符集标准,支持世界上所有主要文字以及常见技术符号。早期Unicode规定所有字符固定16bit宽(也就是UCS-2),但是Unicode标准中的字符早已超过16bit所能表示的范围,现规定的代码点范围在U+0000到U+10FFFF之间。Java标准使用的UTF-16定义的编码方式允许使用一个或两个16bit单位来表示所有的Unicode代码点。
Java基本数据类型char是一个无符号的16bit整数,可以表示U+0000到U+FFFF范围内的码点(BMP平面字符),同时也可作为UTF-16的码元,即32bit编码中的一半(两个char拼成一个字的辅助平面字符,但这种字符使用频率很低)。
更多有关字符编码的知识可以参考我的这篇文章
Java平台中表示字符序列的各种类型如:char[]、java.lang.CharSequence的实现类(如String类)以及java.text.CharacterIterator的实现类都是UTF-16序列。大多数Java源代码是使用ASCII(一种7bit字符编码方式)或ISO-8859-1(西欧8bit字符编码)或GBK(中国国标扩展编码)所编写的,但在处理之前都被转换为UTF-16编码。
Character类作为基本数据类型char的包装类,里面有很多确定字符属性的静态方法,如isLowerCase、isTitleCase和isDigit等,在Java5之前这些方法只有char作为参数,所以只接受U+0000到U+FFFF范围内的码点,Java5之后这些方法有了int类型作为参数的重载方法,这样就能表示所有Unicode代码点。
区域识别与本地化 1. Locale—地区性 Java平台将语言和地区分开定义,但均使用Locale类表示,Locale类通常代表特定地理位置,政权或文化区域。国际化的API中都有重载的方法要求提供一个Locale类的实例,而Locale类中有许多的静态常量用于表示常见的国家和地区的本地化对象。比如:Local.CHINA,Local.CANADA,Local.JAPEN。
官网有Java支持的所有国家或地区语言的列表
2. ResourceBundle—国际化资源 通常我们的应用或系统不会将字符(串)等信息硬编码编译到Java字节码中,而是将这些信息以资源文件的形式存储在磁盘中,这是我们通常需要ResourceBundle这个类。
ResourceBundle是一个抽象类,代表着程序中所使用资源集合(字符串或图片路径等)。将资源和Java类一起打包,可以利用Java类加载机制来查找资源,ResourceBundle中包含特定区域的资源对象,当一个程序需要该区域的资源,程序可以从资源包中加载它,这样开发人员编写代码,可以不用关注特定区域的资源问题(资源文件可以单独维护)。
Java平台资源文件主要是properties格式
ResourceBundle中有几个重载的静态方法getBundle可以用来根据资源名(不包括区域信息的基本名称)来获取ResourceBundle对象,有ResourceBundle对象后即可通过getString,getObject等方法传入Key即可获取对应的Value。
示例:
比如你有两个特定区域的资源:MyResource_en.properties和MyResource_zh.properties:
java代码获取资源文件内容
1 2 3 4 ResourceBundle res = ResourceBundle.getBundle("MyResource" );String value = res.getString("key" );
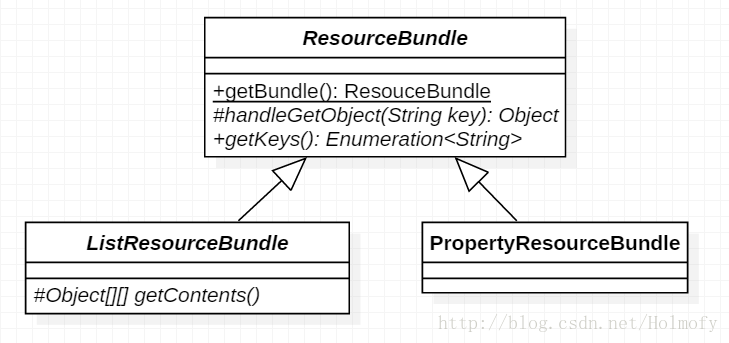
ResourceBundle的子类
ResourceBundle有两个子类:ListResourceBundle和PropertyResourceBundle。
1、ListResourceBundle是一个抽象类,需要我们继承并实现Object[][] getContents()方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class MyResources extends ResourceBundle { public Object handleGetObject (String key) { if (key.equals("okKey" )) return "Ok" ; if (key.equals("cancelKey" )) return "Cancel" ; return null ; } public Enumeration<String> getKeys () { return Collections.enumeration(keySet()); } protected Set<String> handleKeySet () { return new HashSet <String>(Arrays.asList("okKey" , "cancelKey" )); } } public class MyResources_zh extends MyResources { public Object handleGetObject (String key) { if (key.equals("cancelKey" )) return "取消" ; return null ; } protected Set<String> handleKeySet () { return new HashSet <String>(Arrays.asList("cancelKey" )); } }
可以看出JDK的sun包中有很多这种方式书写的资源:
2、PropertyResourceBundle就是ResourceBundle通过get方法获取资源的形式,它使用的是Properties工具类获取.properties文件中的信息。
日期与时间的处理 java.util.Date类代表着毫秒精度的日期时间,该类有几个方法可以获取日期中的年、月、日、时、分、秒等信息。但是由于该类依赖于时区,与国际化不兼容,大部分方法已经被弃用,通常我们使用Calendar类来转换日期和时间,并通过DateFormat类来格式化或解析日期时间字符串。
Calendar Calendar是一个抽象类,它用于一个整数的计算机纪元点时间转换成年、月、日、星期等信息。GregorianCalendar类是Calendar实现类,它根据格林尼治时间历法(公历)来实现。同时Calendar类提供了getInstance静态工厂方法来创建Calendar实例对象。
TimeZone TimeZone是一个抽象类,封装了一个相对于GMT(格林尼治标准时间)的偏移值。TimeZone.getTimeZone工厂方法能通过指定zoneID来创建一个TimeZone实例对象。另外TimeZone还有一个SimpleTimeZone实现类可以创建TimeZone对象。
Calendar类及其子类会使用TimeZone进行本地时间与UTC(通用标准时间)之间的转换。
格式化 i18n中重要的一个部分就是文本格式化,这些功能主要在java.text包中:
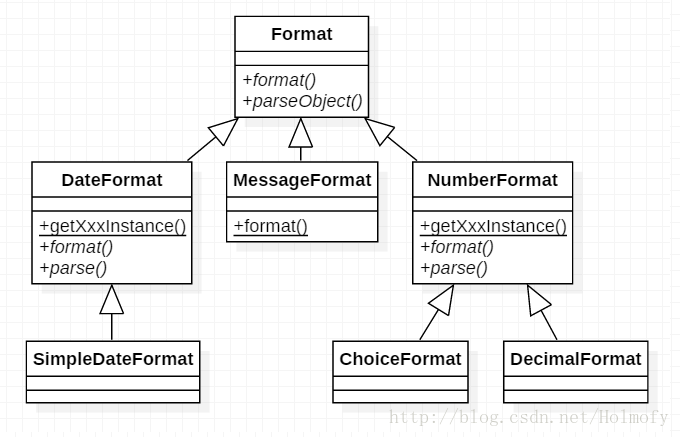
主要分为三类:
DateFormat:日期格式化。根据区域不同使用不同的日期格式,可以自定义日期显示的格式。 MessageFormat:信息格式化。根据区域不同使用不同语言的字符显示信息,比如谷歌的网站对于不同的国家会以不同的语言显示网页信息。 NumberFormat:数字格式化。根据不同区域使用不同的数字格式,比如货币显示,西方国家会每隔三位加一个空格或逗号。 Format类主要有两个抽象方法需要子类去实现:
format方法用于将对象格式化成字符串。parseObject方法用于将字符串按格式解析成对象。DateFormat和NumberFormat这两个是抽象类,它们都有静态工厂方法getXxxInstance来获取该类的实例对象,同时它们也提供了子类可以实例化。
日期时间格式化 DateFormat DateFormat有几个静态工厂方法getXxxInstance,DateFormat提供了几个标准的时间格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static final int FULL = 0 ;public static final int LONG = 1 ;public static final int MEDIUM = 2 ;public static final int SHORT = 3 ;
默认时期格式为:
1 2 3 4 public static final int DEFAULT = MEDIUM;
通过getXxxInstance方法可以传入这些常量设置日期或时间的格式,这几个getXxxInstance方法最终都辗转调用下面这个方法:
1 private static DateFormat get (int timeStyle, int dateStyle, int flags, Locale loc)
其中timeStyle代表时间的显示格式(时分秒部分),dateStyle代表日期的显示格式(年月日部分),这两个参数就是上面四个常量;flags参数有三种状态:1表示值显示时间部分,2表示只显示日期部分,3表示日期时间都显示;loc参数用于指定国家和地区,从而应对不同国家的时间格式。
DateFormat底层使用Calendar和TimeZone(Calendar内部)来解析时间,可以通过这两个属性的getter/setter方法来设置日期和时区。
有了DateFormat对象并设置了日期时间后即可调用它的format(格式化日期)或parse(解析日期)方法。
1 2 3 4 5 6 7 8 DateFormat df = DateFormat.getDateTimeInstance(DateFormat.LONG, DateFormat.LONG, Locale.CHINA); String timeString = df.format(System.currentTimeMillis());System.out.println(timeString); Date parse = df.parse(timeString);System.out.println(parse); System.out.println(parse.getTime());
输出结果:
1 2 3 2017年8月4日 上午11时04分31秒 Fri Aug 04 11:04:31 CST 2017 1501815871000
SimpleDateFormat SimpleDateFormat是DateFormat的子类,可以由开发者自己定义解析格式。
示例:
1 2 3 4 5 6 SimpleDateFormat df = new SimpleDateFormat ("yyyy/MM/dd HH:mm:ss" );String timeStr1 = df.format(System.currentTimeMillis());System.out.println(timeStr1); df.applyPattern("yyyy年MM月dd日-HH时mm分ss秒S毫秒" ); String timeStr2 = df.format(System.currentTimeMillis());System.out.println(timeStr2);
输出结果:
1 2 2017/08/04 11:03:23 2017年08月04日-11时03分23秒119毫秒
官方API文档中 给出了SimpleDateFormat的各种pattern的规则。
数字格式化 NumberFormat NumberFormat和DateFormat类似,也提供了几个标准的数字格式:
1 2 3 4 5 private static final int NUMBERSTYLE = 0 ; private static final int CURRENCYSTYLE = 1 ; private static final int PERCENTSTYLE = 2 ; private static final int SCIENTIFICSTYLE = 3 ; private static final int INTEGERSTYLE = 4 ;
我们不需要指定数字格式,NumberFormat已经为我们封装了这几个风格样式并提供给我们静态方法:
1 2 3 4 5 6 7 8 9 10 11 12 public final static NumberFormat getInstance () ; public final static NumberFormat getInstance (Locale inLocale) ; public final static NumberFormat getNumberInstance () ; public final static NumberFormat getNumberInstance (Locale inLocale) ; public final static NumberFormat getIntegerInstance () ; public final static NumberFormat getIntegerInstance (Locale inLocale) ; public final static NumberFormat getCurrencyInstance () ; public final static NumberFormat getCurrencyInstance (Locale inLocale) ; public final static NumberFormat getPercentInstance () ; public final static NumberFormat getPercentInstance (Locale inLocale) ; final static NumberFormat getScientificInstance () ; static NumberFormat getScientificInstance (Locale inLocale) ;
示例:
1 2 3 4 5 6 7 8 9 10 11 12 NumberFormat[] formats = { NumberFormat.getInstance(), NumberFormat.getNumberInstance(), NumberFormat.getIntegerInstance(), NumberFormat.getCurrencyInstance(), NumberFormat.getPercentInstance() }; for (int i = 0 ; i < formats.length; i++) { System.out.println(formats[i].format(100L )); System.out.println(formats[i].format(123.456F )); }
输出结果:
1 2 3 4 5 6 7 8 9 10 100 123.456 100 123.456 100 123 ¥100.00 ¥123.46 10 ,000 %12 ,346 %
DecimalFormat 该类允许我们自定义十进制数字的格式化。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 DecimalFormat format; format = new DecimalFormat ("####,####,###0.0# 圆整" ); System.out.println(format.format(12345678.90F )); System.out.println(format.format(-12345678.90F )); format.applyPattern("0.0#####E0####" ); System.out.println(format.format(1234567894987654321.90F )); System.out.println(format.format(12.34F )); format.applyPattern("00.0#E0##" ); System.out.println(format.format(1234567894987654321.90F )); System.out.println(format.format(12.34F ));
运行结果:
1 2 3 4 5 6 1234 ,5679.0 圆整-1234 ,5679.0 圆整 1.2345679396E18 1.2340000153E1 12.3457E17 12.34E0
信息格式化 所谓“信息”格式化,其实就是字符串格式化,可以通过MessageFormat这个类构造一个字符串显示给终端用户。不过在这之前要说说JDK1.0开始就已经存在的老牌API——java.util.Formatter。
java.util.Formatter 我们知道String类中有一个静态方法String.format(String format, Object... args)和C语言中的sprintf函数极为相似,这个方法底层就是用了java.util.Formatter类来实现,而待会儿要讲的MessageFormat类功能远比这个类功能强大(指的是格式化字符串这方面),所以在这之前我们先来说说java.util.Formatter这个类。
我们知道C语言中有几个I/O流的函数:printf,sprintf,fprintf(在C11标准中还提供了这几个方法的安全版本,防止溢出)。
而java.util.Formatter类能实现类似于C语言中的这几个函数,只需要在构造方法中传入不同的输出流即可,下面列一个表把C语言中的函数与Java中的Formatter类的应用进行对比:
C语言函数 Java API 备注 printf(const char *format, ...)System.out.format(String format, Object ... args)System.out是一个PrintStream对象,该对象底层使用java.util.Formatter对象进行格式化输出。 sprintf( char *buffer, const char *format, ... )String.format(String format, Object... args)String.format方法每次调用都会new一个Formatter对象。 fprintf( FILE *stream, const char *format, ... )new Formatter(new File(filename)).format(String format, Object ... args)Formatter类可以直接封装输出流,你可以直接传入一个文件名或文件对象。
但是由于Java是面向对象的语言,format参数是Object类型,所以如果我们想要格式化输出自定义对象,则该对象必须实现java.util.Formattable接口,但实际上JDK中没有任何类实现了该接口,这样做还不如重载Object.toString方法。另外由于java中String是不可变的对象,所以String.format方法并没有像sprintf函数一样灵活性。
而相反MessageFormat类中有一个方法:
1 public final StringBuffer format (Object[] arguments, StringBuffer result, FieldPosition pos) ;
这个方法使用的是StringBuffer类作为存储字符串的缓冲区,这才契合了sprintf的功能。
java.text.MessageFormat 前面扯到C语言和Java API中格式化输出的对比,接下来就继续谈谈MessageFormat的强大功能。
MessageFormat融合了前面讲到的DateFormat,NumberFormat的功能,我们可以直接通过new关键字创建MessageFormat的对象。MessageFormat有以下两个构造方法:
1 2 public MessageFormat (String pattern) ;public MessageFormat (String pattern, Locale locale) ;
MessgaeFormat类还提供了一个静态方法,如果MessageFormat使用较多不建议使用这个静态方法,因为该方法要创建MessageFormat对象:
1 2 3 4 public static String format (String pattern, Object ... arguments) { MessageFormat temp = new MessageFormat (pattern); return temp.format(arguments); }
构造方法中需要传递一个pattern参数,MessageFormat的pattern语法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 MessageFormatPattern: String MessageFormatPattern FormatElement String FormatElement: { ArgumentIndex } { ArgumentIndex , FormatType } { ArgumentIndex , FormatType , FormatStyle } FormatType: one of number | date | time | choice FormatStyle: short medium long full integer currency percent SubformatPattern
先来看一个例子:
1 2 3 4 5 6 7 8 int place = 7 ;String event = "一场战斗" ;String result = MessageFormat.format( "在 {1,date} 的 {1,time} , 在第{0,number,integer}区发生了{2}。" , place, new Date (), event); System.out.println(result);
运行结果:
1 在 2017-8-4 的 21:37:37 , 在第7区发生了一场战斗。
在模式字符串中我们可以插入{ ArgumentIndex , [FormatType , [FormatStyle]] }这样的语法作为占位符,可以在后面的变长参数中填充这些占位符。
占位符语法中有三个参数:
FormatType FormatStyle Subformat Created (none) (none) nullnumber(none) NumberFormat.getInstance(getLocale())integerNumberFormat.getIntegerInstance(getLocale())currencyNumberFormat.getCurrencyInstance(getLocale())percentNumberFormat.getPercentInstance(getLocale())SubformatPattern newDecimalFormat(subformatPattern,DecimalFormatSymbols.getInstance(getLocale()))date(none) DateFormat.getDateInstance(DateFormat.DEFAULT, getLocale())shortDateFormat.getDateInstance(DateFormat.SHORT, getLocale())mediumDateFormat.getDateInstance(DateFormat.DEFAULT, getLocale())longDateFormat.getDateInstance(DateFormat.LONG, getLocale())fullDateFormat.getDateInstance(DateFormat.FULL, getLocale())SubformatPattern newSimpleDateFormat(subformatPattern, getLocale())time(none) DateFormat.getTimeInstance(DateFormat.DEFAULT, getLocale())shortDateFormat.getTimeInstance(DateFormat.SHORT, getLocale())mediumDateFormat.getTimeInstance(DateFormat.DEFAULT, getLocale())longDateFormat.getTimeInstance(DateFormat.LONG, getLocale())fullDateFormat.getTimeInstance(DateFormat.FULL, getLocale())SubformatPattern newSimpleDateFormat(subformatPattern, getLocale())choiceSubformatPattern newChoiceFormat(subformatPattern)
有了这张表,就知道FormatType 与前面的NumberFormat和DateFormat之间的关系了。
继续看两个例子:
1、对磁盘空间的使用情况进行格式化处理
1 2 3 4 5 6 7 8 9 10 11 Object[][] testArgs = { { 0 , "MyDisk" }, { 1 , "MyDisk" }, { 1234 , "MyDisk" } }; MessageFormat form = new MessageFormat ("The disk \"{1}\" contains {0} file(s)." );for (int i = 0 ; i < testArgs.length; i++) { System.out.println(form.format(testArgs[i])); }
输出结果:
1 2 3 The disk "MyDisk" contains 0 file(s). The disk "MyDisk" contains 1 file(s). The disk "MyDisk" contains 1 ,234 file(s).
2、对与磁盘中文件数为0的情况,显示no file,对于文件数为1的情况,显示one file。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Object[][] testArgs = { { 0 , "MyDisk" }, { 1 , "MyDisk" }, { 1234 , "MyDisk" } }; MessageFormat form = new MessageFormat ("The disk \"{1}\" contains {0}." );double [] filelimits = { 0 , 1 , 2 };String[] filepart = { "no files" , "one file" , "{0,number} files" }; ChoiceFormat fileform = new ChoiceFormat (filelimits, filepart);form.setFormatByArgumentIndex(0 , fileform); for (int i = 0 ; i < testArgs.length; i++) { System.out.println(form.format(testArgs[i])); }
输出结果:
1 2 3 The disk "MyDisk" contains no files. The disk "MyDisk" contains one file. The disk "MyDisk" contains 1,234 files.
ChoiceFormat是一个选区格式化(可以理解为分支语句),使用它我们可以在pattern模式串中写分支语句(有点类似于正则表达式中的条件分支),比如上面的需求我们可以这样实现:
1 2 3 4 5 6 7 8 9 10 11 12 Object[][] testArgs = { { 0 , "MyDisk" }, { 1 , "MyDisk" }, { 1234 , "MyDisk" } }; MessageFormat form = new MessageFormat ( "The disk \"{1}\" contains {0, choice, 0#no files|1#one file|1<{0,number,integer} files}." ); for (int i = 0 ; i < testArgs.length; i++) { System.out.println(form.format(testArgs[i])); }
更多有关ChoiceFormat的信息可以参考官方文档
字符串操作 字符串比较 String类实现了Comparable接口所以提供了一个compareTo方法,但是该方法是直接比较字符的Unicode编码值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public int compareTo (String anotherString) { int len1 = value.length; int len2 = anotherString.value.length; int lim = Math.min(len1, len2); char v1[] = value; char v2[] = anotherString.value; int k = 0 ; while (k < lim) { char c1 = v1[k]; char c2 = v2[k]; if (c1 != c2) { return c1 - c2; } k++; } return len1 - len2; }
但是Unicode中文字符并没有严格的排序(有一说是按笔画排序,但在Unicode官网 下的编码表中看并没有严格按笔画排序),而且我们通常习惯按照中文拼音对中文字符串进行排序。Java已经给我们提供了相应的解决方案。
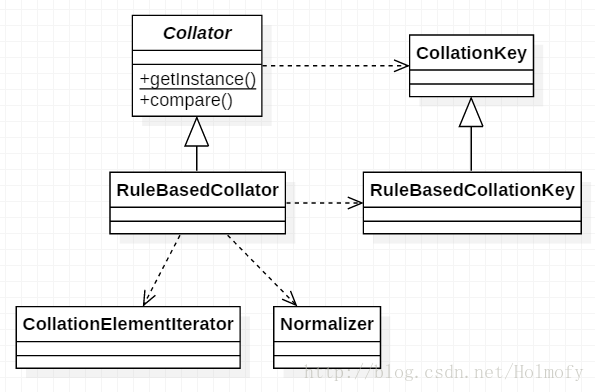
Collator Collator类能按照相应国家和区域的习惯进行字符串比较,我们可以使用它来对字符(串)进行排序。
Collator类是一个抽象类,其子类实现了特定的比较策略,目前Java平台提供了一个子类RuleBasedCollator,能适用于广泛的语言。当然我们可以继续创建它的子类来适应我们其他独特的需求。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("林志炫" ); list.add("杨洋" ); list.add("刘亦菲" ); list.add("邓紫棋" ); list.add("赵丽颖" ); list.add("周杰伦" ); list.add("邓超" ); list.add("孙俪" ); list.add("刘诗诗" ); list.add("杨宗纬" ); list.add("林志颖" ); list.sort(null ); System.out.println("String默认排序:" ); printList(list); list.sort(new Comparator <String>() { Collator collator = Collator.getInstance(Locale.CHINESE); @Override public int compare (String o1, String o2) { return collator.compare(o1, o2); } }); System.out.println(); System.out.println("Collator排序:" ); printList(list); } public static void printList (List<String> list) { list.forEach(new Consumer <String>() { @Override public void accept (String t) { System.out.print(t + " " ); } }); }
输出结果:
1 2 3 4 String默认排序: 刘亦菲 刘诗诗 周杰伦 孙俪 杨宗纬 杨洋 林志炫 林志颖 赵丽颖 邓紫棋 邓超 Collator排序: 邓超 邓紫棋 林志颖 林志炫 刘诗诗 刘亦菲 孙俪 杨洋 杨宗纬 赵丽颖 周杰伦
虽然Collator能完成基本的字符排序,但如果相对繁体等不常用的字进行排序,这个方法就不行了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 list.add("林志炫" ); list.add("杨洋" ); list.add("楊洋" ); list.add("刘亦菲" ); list.add("劉亦菲" ); list.add("邓紫棋" ); list.add("鄧紫棋" ); list.add("赵丽颖" ); list.add("趙麗穎" ); list.add("周杰伦" ); list.add("周杰倫" ); list.add("邓超" ); list.add("鄧超" ); list.add("孙俪" ); list.add("孫儷" ); list.add("刘诗诗" ); list.add("劉詩詩" ); list.add("杨宗纬" ); list.add("楊宗緯" ); list.add("林志颖" );
输出结果:
1 2 3 4 String默认排序: 刘亦菲 刘诗诗 劉亦菲 劉詩詩 周杰伦 周杰倫 孙俪 孫儷 杨宗纬 杨洋 林志炫 林志颖 楊宗緯 楊洋 赵丽颖 趙麗穎 邓紫棋 邓超 鄧紫棋 鄧超 Collator排序: 邓超 邓紫棋 林志颖 林志炫 刘诗诗 刘亦菲 孙俪 杨洋 杨宗纬 赵丽颖 周杰伦 周杰倫 劉亦菲 劉詩詩 孫儷 楊洋 楊宗緯 趙麗穎 鄧超 鄧紫棋
关于中文排序的问题,这里 有一篇文章给出了几个解决方案
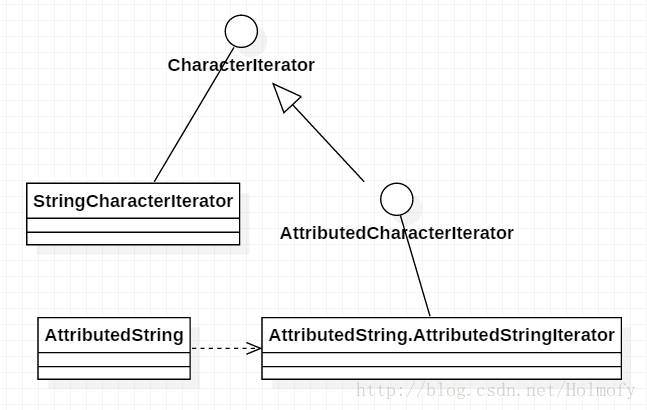
字符串迭代 java.text.StringCharacterIterator类封装好了字符串迭代功能,这个类很鸡肋,和普通的for循环迭代没啥区别。
StringCharacterIterator是CharcterIterator接口的实现类,CharcterIterator接口中定义了Unicode字符双向迭代的规则。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 public void traverseForward (CharacterIterator iter) { for (char c = iter.first(); c != CharacterIterator.DONE; c = iter.next()) { processChar(c); } } public void traverseBackward (CharacterIterator iter) { for (char c = iter.last(); c != CharacterIterator.DONE; c = iter.previous()) { processChar(c); } }
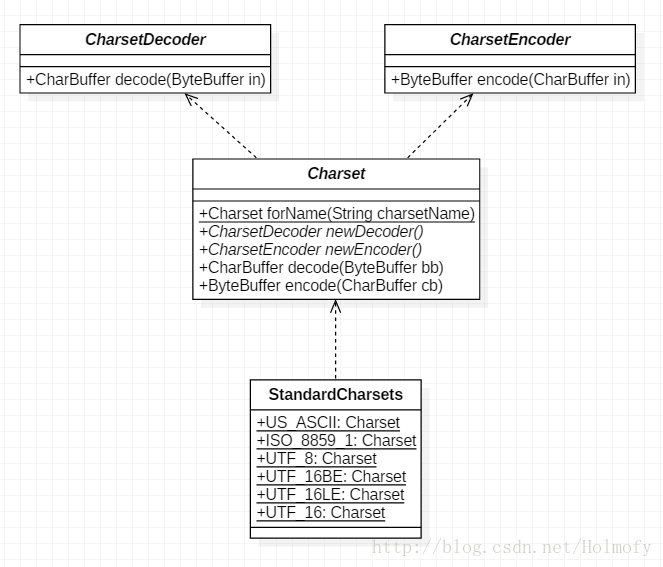
编码转换 Java使用Unicode作为编码方法,经常会出现将将程序中的数据输出到外部(磁盘文件或网络响应等),最常用的两个类就是InputStreamReader和OutputStreamWriter,这两个类后期也是用Charset类来实现核心功能的。Charset采用spi设计模式,允许我们开发自定义的编解码器。
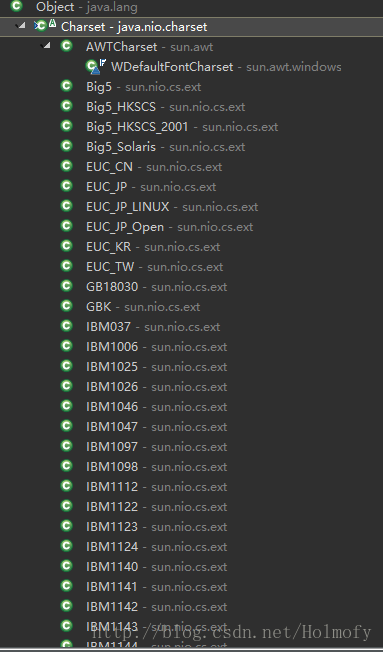
Charset 写个例子看一下Charset支持哪些编码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public static void main (String[] args) { SortedMap<String, Charset> charsets = Charset.availableCharsets(); for (String name : charsets.keySet()) { System.out.print("Name:" ); System.out.print(name); Charset charset = charsets.get(name); System.out.print(" " ); System.out.print("DisplayName:" ); System.out.print(charset.displayName()); System.out.print(" " ); System.out.print("Aliases:" ); Set<String> aliases = charset.aliases(); for (String alias : aliases) { System.out.print(alias); System.out.print(" " ); } System.out.println(); } }
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 Name:Big5 DisplayName:Big5 Aliases:csBig5 Name:Big5-HKSCS DisplayName:Big5-HKSCS Aliases:big5-hkscs big5hk Big5_HKSCS big5hkscs Name:CESU-8 DisplayName:CESU-8 Aliases:CESU8 csCESU-8 Name:EUC-JP DisplayName:EUC-JP Aliases:csEUCPkdFmtjapanese x-euc-jp eucjis Extended_UNIX_Code_Packed_Format_for_Japanese euc_jp eucjp x-eucjp Name:EUC-KR DisplayName:EUC-KR Aliases:ksc5601-1987 csEUCKR ksc5601_1987 ksc5601 5601 euc_kr ksc_5601 ks_c_5601-1987 euckr Name:GB18030 DisplayName:GB18030 Aliases:gb18030-2000 Name:GB2312 DisplayName:GB2312 Aliases:gb2312 euc-cn x-EUC-CN euccn EUC_CN gb2312-80 gb2312-1980 Name:GBK DisplayName:GBK Aliases:CP936 windows-936 Name:IBM-Thai DisplayName:IBM-Thai Aliases:ibm-838 ibm838 838 cp838 Name:IBM00858 DisplayName:IBM00858 Aliases:cp858 858 PC-Multilingual-850+euro cp00858 ccsid00858 Name:IBM01140 DisplayName:IBM01140 Aliases:cp1140 1140 cp01140 ebcdic-us-037+euro ccsid01140 Name:IBM01141 DisplayName:IBM01141 Aliases:1141 cp1141 cp01141 ccsid01141 ebcdic-de-273+euro Name:IBM01142 DisplayName:IBM01142 Aliases:1142 cp1142 cp01142 ccsid01142 ebcdic-no-277+euro ebcdic-dk-277+euro Name:IBM01143 DisplayName:IBM01143 Aliases:1143 cp01143 ccsid01143 cp1143 ebcdic-fi-278+euro ebcdic-se-278+euro Name:IBM01144 DisplayName:IBM01144 Aliases:cp01144 ccsid01144 ebcdic-it-280+euro cp1144 1144 Name:IBM01145 DisplayName:IBM01145 Aliases:ccsid01145 ebcdic-es-284+euro 1145 cp1145 cp01145 Name:IBM01146 DisplayName:IBM01146 Aliases:ebcdic-gb-285+euro 1146 cp1146 cp01146 ccsid01146 Name:IBM01147 DisplayName:IBM01147 Aliases:cp1147 1147 cp01147 ccsid01147 ebcdic-fr-277+euro Name:IBM01148 DisplayName:IBM01148 Aliases:cp1148 ebcdic-international-500+euro 1148 cp01148 ccsid01148 Name:IBM01149 DisplayName:IBM01149 Aliases:ebcdic-s-871+euro 1149 cp1149 cp01149 ccsid01149 Name:IBM037 DisplayName:IBM037 Aliases:cp037 ibm037 ibm-037 csIBM037 ebcdic-cp-us ebcdic-cp-ca ebcdic-cp-nl ebcdic-cp-wt 037 cpibm37 cs-ebcdic-cp-wt ibm-37 cs-ebcdic-cp-us cs-ebcdic-cp-ca cs-ebcdic-cp-nl Name:IBM1026 DisplayName:IBM1026 Aliases:cp1026 ibm-1026 1026 ibm1026 Name:IBM1047 DisplayName:IBM1047 Aliases:ibm-1047 1047 cp1047 Name:IBM273 DisplayName:IBM273 Aliases:ibm-273 ibm273 273 cp273 Name:IBM277 DisplayName:IBM277 Aliases:ibm277 277 cp277 ibm-277 Name:IBM278 DisplayName:IBM278 Aliases:cp278 278 ibm-278 ebcdic-cp-se csIBM278 ibm278 ebcdic-sv Name:IBM280 DisplayName:IBM280 Aliases:ibm280 280 cp280 ibm-280 Name:IBM284 DisplayName:IBM284 Aliases:csIBM284 ibm-284 cpibm284 ibm284 284 cp284 Name:IBM285 DisplayName:IBM285 Aliases:csIBM285 cp285 ebcdic-gb ibm-285 cpibm285 ibm285 285 ebcdic-cp-gb Name:IBM290 DisplayName:IBM290 Aliases:ibm290 290 cp290 EBCDIC-JP-kana csIBM290 ibm-290 Name:IBM297 DisplayName:IBM297 Aliases:297 csIBM297 cp297 ibm297 ibm-297 cpibm297 ebcdic-cp-fr Name:IBM420 DisplayName:IBM420 Aliases:ibm420 420 cp420 csIBM420 ibm-420 ebcdic-cp-ar1 Name:IBM424 DisplayName:IBM424 Aliases:ebcdic-cp-he csIBM424 ibm-424 ibm424 424 cp424 Name:IBM437 DisplayName:IBM437 Aliases:ibm437 437 ibm-437 cspc8codepage437 cp437 windows-437 Name:IBM500 DisplayName:IBM500 Aliases:ibm-500 ibm500 500 ebcdic-cp-bh ebcdic-cp-ch csIBM500 cp500 Name:IBM775 DisplayName:IBM775 Aliases:ibm-775 ibm775 775 cp775 Name:IBM850 DisplayName:IBM850 Aliases:cp850 cspc850multilingual ibm850 850 ibm-850 Name:IBM852 DisplayName:IBM852 Aliases:csPCp852 ibm-852 ibm852 852 cp852 Name:IBM855 DisplayName:IBM855 Aliases:ibm855 855 ibm-855 cp855 cspcp855 Name:IBM857 DisplayName:IBM857 Aliases:ibm857 857 cp857 csIBM857 ibm-857 Name:IBM860 DisplayName:IBM860 Aliases:ibm860 860 cp860 csIBM860 ibm-860 Name:IBM861 DisplayName:IBM861 Aliases:cp861 ibm861 861 ibm-861 cp-is csIBM861 Name:IBM862 DisplayName:IBM862 Aliases:csIBM862 cp862 ibm862 862 cspc862latinhebrew ibm-862 Name:IBM863 DisplayName:IBM863 Aliases:csIBM863 ibm-863 ibm863 863 cp863 Name:IBM864 DisplayName:IBM864 Aliases:csIBM864 ibm-864 ibm864 864 cp864 Name:IBM865 DisplayName:IBM865 Aliases:ibm-865 csIBM865 cp865 ibm865 865 Name:IBM866 DisplayName:IBM866 Aliases:ibm866 866 ibm-866 csIBM866 cp866 Name:IBM868 DisplayName:IBM868 Aliases:ibm868 868 cp868 csIBM868 ibm-868 cp-ar Name:IBM869 DisplayName:IBM869 Aliases:cp869 ibm869 869 ibm-869 cp-gr csIBM869 Name:IBM870 DisplayName:IBM870 Aliases:870 cp870 csIBM870 ibm-870 ibm870 ebcdic-cp-roece ebcdic-cp-yu Name:IBM871 DisplayName:IBM871 Aliases:ibm871 871 cp871 ebcdic-cp-is csIBM871 ibm-871 Name:IBM918 DisplayName:IBM918 Aliases:918 ibm-918 ebcdic-cp-ar2 cp918 Name:ISO-2022-CN DisplayName:ISO-2022-CN Aliases:csISO2022CN ISO2022CN Name:ISO-2022-JP DisplayName:ISO-2022-JP Aliases:csjisencoding iso2022jp jis_encoding jis csISO2022JP Name:ISO-2022-JP-2 DisplayName:ISO-2022-JP-2 Aliases:csISO2022JP2 iso2022jp2 Name:ISO-2022-KR DisplayName:ISO-2022-KR Aliases:csISO2022KR ISO2022KR Name:ISO-8859-1 DisplayName:ISO-8859-1 Aliases:819 ISO8859-1 l1 ISO_8859-1:1987 ISO_8859-1 8859_1 iso-ir-100 latin1 cp819 ISO8859_1 IBM819 ISO_8859_1 IBM-819 csISOLatin1 Name:ISO-8859-13 DisplayName:ISO-8859-13 Aliases:iso_8859-13 ISO8859-13 iso8859_13 8859_13 Name:ISO-8859-15 DisplayName:ISO-8859-15 Aliases:ISO8859-15 LATIN0 ISO8859_15_FDIS ISO8859_15 cp923 8859_15 L9 ISO-8859-15 IBM923 csISOlatin9 ISO_8859-15 IBM-923 csISOlatin0 923 LATIN9 Name:ISO-8859-2 DisplayName:ISO-8859-2 Aliases:ISO8859-2 ibm912 l2 ISO_8859-2 8859_2 cp912 ISO_8859-2:1987 iso8859_2 iso-ir-101 latin2 912 csISOLatin2 ibm-912 Name:ISO-8859-3 DisplayName:ISO-8859-3 Aliases:ISO8859-3 ibm913 8859_3 l3 cp913 ISO_8859-3 iso8859_3 latin3 csISOLatin3 913 ISO_8859-3:1988 ibm-913 iso-ir-109 Name:ISO-8859-4 DisplayName:ISO-8859-4 Aliases:8859_4 latin4 l4 cp914 ISO_8859-4:1988 ibm914 ISO_8859-4 iso-ir-110 iso8859_4 csISOLatin4 iso8859-4 914 ibm-914 Name:ISO-8859-5 DisplayName:ISO-8859-5 Aliases:ISO_8859-5:1988 csISOLatinCyrillic iso-ir-144 iso8859_5 cp915 8859_5 ibm-915 ISO_8859-5 ibm915 915 cyrillic ISO8859-5 Name:ISO-8859-6 DisplayName:ISO-8859-6 Aliases:ASMO-708 8859_6 iso8859_6 ISO_8859-6 csISOLatinArabic ibm1089 arabic ibm-1089 1089 ECMA-114 iso-ir-127 ISO_8859-6:1987 ISO8859-6 cp1089 Name:ISO-8859-7 DisplayName:ISO-8859-7 Aliases:greek 8859_7 greek8 ibm813 ISO_8859-7 iso8859_7 ELOT_928 cp813 ISO_8859-7:1987 sun_eu_greek csISOLatinGreek iso-ir-126 813 iso8859-7 ECMA-118 ibm-813 Name:ISO-8859-8 DisplayName:ISO-8859-8 Aliases:8859_8 ISO_8859-8 ISO_8859-8:1988 cp916 iso-ir-138 ISO8859-8 hebrew iso8859_8 ibm-916 csISOLatinHebrew 916 ibm916 Name:ISO-8859-9 DisplayName:ISO-8859-9 Aliases:ibm-920 ISO_8859-9 8859_9 ISO_8859-9:1989 ibm920 latin5 l5 iso8859_9 cp920 920 iso-ir-148 ISO8859-9 csISOLatin5 Name:JIS_X0201 DisplayName:JIS_X0201 Aliases:JIS0201 csHalfWidthKatakana X0201 JIS_X0201 Name:JIS_X0212-1990 DisplayName:JIS_X0212-1990 Aliases:JIS0212 iso-ir-159 x0212 jis_x0212-1990 csISO159JISX02121990 Name:KOI8-R DisplayName:KOI8-R Aliases:koi8_r koi8 cskoi8r Name:KOI8-U DisplayName:KOI8-U Aliases:koi8_u Name:Shift_JIS DisplayName:Shift_JIS Aliases:shift_jis x-sjis sjis shift-jis ms_kanji csShiftJIS Name:TIS-620 DisplayName:TIS-620 Aliases:tis620 tis620.2533 Name:US-ASCII DisplayName:US-ASCII Aliases:ANSI_X3.4-1968 cp367 csASCII iso-ir-6 ASCII iso_646.irv:1983 ANSI_X3.4-1986 ascii7 default ISO_646.irv:1991 ISO646-US IBM367 646 us Name:UTF-16 DisplayName:UTF-16 Aliases:UTF_16 unicode utf16 UnicodeBig Name:UTF-16BE DisplayName:UTF-16BE Aliases:X-UTF-16BE UTF_16BE ISO-10646-UCS-2 UnicodeBigUnmarked Name:UTF-16LE DisplayName:UTF-16LE Aliases:UnicodeLittleUnmarked UTF_16LE X-UTF-16LE Name:UTF-32 DisplayName:UTF-32 Aliases:UTF_32 UTF32 Name:UTF-32BE DisplayName:UTF-32BE Aliases:X-UTF-32BE UTF_32BE Name:UTF-32LE DisplayName:UTF-32LE Aliases:X-UTF-32LE UTF_32LE Name:UTF-8 DisplayName:UTF-8 Aliases:unicode-1-1-utf-8 UTF8 Name:windows-1250 DisplayName:windows-1250 Aliases:cp1250 cp5346 Name:windows-1251 DisplayName:windows-1251 Aliases:cp5347 ansi-1251 cp1251 Name:windows-1252 DisplayName:windows-1252 Aliases:cp5348 cp1252 Name:windows-1253 DisplayName:windows-1253 Aliases:cp1253 cp5349 Name:windows-1254 DisplayName:windows-1254 Aliases:cp1254 cp5350 Name:windows-1255 DisplayName:windows-1255 Aliases:cp1255 Name:windows-1256 DisplayName:windows-1256 Aliases:cp1256 Name:windows-1257 DisplayName:windows-1257 Aliases:cp1257 cp5353 Name:windows-1258 DisplayName:windows-1258 Aliases:cp1258 Name:windows-31j DisplayName:windows-31j Aliases:MS932 windows-932 csWindows31J Name:x-Big5-HKSCS-2001 DisplayName:x-Big5-HKSCS-2001 Aliases:Big5_HKSCS_2001 big5-hkscs-2001 big5hk-2001 big5-hkscs:unicode3.0 big5hkscs-2001 Name:x-Big5-Solaris DisplayName:x-Big5-Solaris Aliases:Big5_Solaris Name:x-euc-jp-linux DisplayName:x-euc-jp-linux Aliases:euc_jp_linux euc-jp-linux Name:x-EUC-TW DisplayName:x-EUC-TW Aliases:euctw cns11643 EUC-TW euc_tw Name:x-eucJP-Open DisplayName:x-eucJP-Open Aliases:eucJP-open EUC_JP_Solaris Name:x-IBM1006 DisplayName:x-IBM1006 Aliases:ibm1006 ibm-1006 1006 cp1006 Name:x-IBM1025 DisplayName:x-IBM1025 Aliases:ibm-1025 1025 cp1025 ibm1025 Name:x-IBM1046 DisplayName:x-IBM1046 Aliases:ibm1046 ibm-1046 1046 cp1046 Name:x-IBM1097 DisplayName:x-IBM1097 Aliases:ibm1097 ibm-1097 1097 cp1097 Name:x-IBM1098 DisplayName:x-IBM1098 Aliases:ibm-1098 1098 cp1098 ibm1098 Name:x-IBM1112 DisplayName:x-IBM1112 Aliases:ibm1112 ibm-1112 1112 cp1112 Name:x-IBM1122 DisplayName:x-IBM1122 Aliases:cp1122 ibm1122 ibm-1122 1122 Name:x-IBM1123 DisplayName:x-IBM1123 Aliases:ibm1123 ibm-1123 1123 cp1123 Name:x-IBM1124 DisplayName:x-IBM1124 Aliases:ibm-1124 1124 cp1124 ibm1124 Name:x-IBM1166 DisplayName:x-IBM1166 Aliases:cp1166 ibm1166 ibm-1166 1166 Name:x-IBM1364 DisplayName:x-IBM1364 Aliases:cp1364 ibm1364 ibm-1364 1364 Name:x-IBM1381 DisplayName:x-IBM1381 Aliases:cp1381 ibm-1381 1381 ibm1381 Name:x-IBM1383 DisplayName:x-IBM1383 Aliases:ibm1383 ibm-1383 1383 cp1383 Name:x-IBM300 DisplayName:x-IBM300 Aliases:cp300 ibm300 300 ibm-300 Name:x-IBM33722 DisplayName:x-IBM33722 Aliases:33722 ibm-33722 cp33722 ibm33722 ibm-5050 ibm-33722_vascii_vpua Name:x-IBM737 DisplayName:x-IBM737 Aliases:cp737 ibm737 737 ibm-737 Name:x-IBM833 DisplayName:x-IBM833 Aliases:ibm833 cp833 ibm-833 Name:x-IBM834 DisplayName:x-IBM834 Aliases:ibm834 834 cp834 ibm-834 Name:x-IBM856 DisplayName:x-IBM856 Aliases:ibm856 856 cp856 ibm-856 Name:x-IBM874 DisplayName:x-IBM874 Aliases:ibm-874 ibm874 874 cp874 Name:x-IBM875 DisplayName:x-IBM875 Aliases:ibm-875 ibm875 875 cp875 Name:x-IBM921 DisplayName:x-IBM921 Aliases:ibm921 921 ibm-921 cp921 Name:x-IBM922 DisplayName:x-IBM922 Aliases:ibm922 922 cp922 ibm-922 Name:x-IBM930 DisplayName:x-IBM930 Aliases:ibm-930 ibm930 930 cp930 Name:x-IBM933 DisplayName:x-IBM933 Aliases:ibm933 933 cp933 ibm-933 Name:x-IBM935 DisplayName:x-IBM935 Aliases:cp935 ibm935 935 ibm-935 Name:x-IBM937 DisplayName:x-IBM937 Aliases:ibm-937 ibm937 937 cp937 Name:x-IBM939 DisplayName:x-IBM939 Aliases:ibm-939 cp939 ibm939 939 Name:x-IBM942 DisplayName:x-IBM942 Aliases:ibm-942 cp942 ibm942 942 Name:x-IBM942C DisplayName:x-IBM942C Aliases:ibm942C cp942C ibm-942C 942C Name:x-IBM943 DisplayName:x-IBM943 Aliases:ibm943 943 ibm-943 cp943 Name:x-IBM943C DisplayName:x-IBM943C Aliases:943C cp943C ibm943C ibm-943C Name:x-IBM948 DisplayName:x-IBM948 Aliases:ibm-948 ibm948 948 cp948 Name:x-IBM949 DisplayName:x-IBM949 Aliases:ibm-949 ibm949 949 cp949 Name:x-IBM949C DisplayName:x-IBM949C Aliases:ibm949C ibm-949C cp949C 949C Name:x-IBM950 DisplayName:x-IBM950 Aliases:cp950 ibm950 950 ibm-950 Name:x-IBM964 DisplayName:x-IBM964 Aliases:ibm-964 cp964 ibm964 964 Name:x-IBM970 DisplayName:x-IBM970 Aliases:ibm970 ibm-eucKR 970 cp970 ibm-970 Name:x-ISCII91 DisplayName:x-ISCII91 Aliases:ISCII91 iso-ir-153 iscii ST_SEV_358-88 csISO153GOST1976874 Name:x-ISO-2022-CN-CNS DisplayName:x-ISO-2022-CN-CNS Aliases:ISO2022CN_CNS ISO-2022-CN-CNS Name:x-ISO-2022-CN-GB DisplayName:x-ISO-2022-CN-GB Aliases:ISO2022CN_GB ISO-2022-CN-GB Name:x-iso-8859-11 DisplayName:x-iso-8859-11 Aliases:iso-8859-11 iso8859_11 Name:x-JIS0208 DisplayName:x-JIS0208 Aliases:JIS0208 JIS_C6226-1983 iso-ir-87 x0208 JIS_X0208-1983 csISO87JISX0208 Name:x-JISAutoDetect DisplayName:x-JISAutoDetect Aliases:JISAutoDetect Name:x-Johab DisplayName:x-Johab Aliases:ms1361 ksc5601_1992 johab ksc5601-1992 Name:x-MacArabic DisplayName:x-MacArabic Aliases:MacArabic Name:x-MacCentralEurope DisplayName:x-MacCentralEurope Aliases:MacCentralEurope Name:x-MacCroatian DisplayName:x-MacCroatian Aliases:MacCroatian Name:x-MacCyrillic DisplayName:x-MacCyrillic Aliases:MacCyrillic Name:x-MacDingbat DisplayName:x-MacDingbat Aliases:MacDingbat Name:x-MacGreek DisplayName:x-MacGreek Aliases:MacGreek Name:x-MacHebrew DisplayName:x-MacHebrew Aliases:MacHebrew Name:x-MacIceland DisplayName:x-MacIceland Aliases:MacIceland Name:x-MacRoman DisplayName:x-MacRoman Aliases:MacRoman Name:x-MacRomania DisplayName:x-MacRomania Aliases:MacRomania Name:x-MacSymbol DisplayName:x-MacSymbol Aliases:MacSymbol Name:x-MacThai DisplayName:x-MacThai Aliases:MacThai Name:x-MacTurkish DisplayName:x-MacTurkish Aliases:MacTurkish Name:x-MacUkraine DisplayName:x-MacUkraine Aliases:MacUkraine Name:x-MS932_0213 DisplayName:x-MS932_0213 Aliases: Name:x-MS950-HKSCS DisplayName:x-MS950-HKSCS Aliases:MS950_HKSCS Name:x-MS950-HKSCS-XP DisplayName:x-MS950-HKSCS-XP Aliases:MS950_HKSCS_XP Name:x-mswin-936 DisplayName:x-mswin-936 Aliases:ms936 ms_936 Name:x-PCK DisplayName:x-PCK Aliases:pck Name:x-SJIS_0213 DisplayName:x-SJIS_0213 Aliases: Name:x-UTF-16LE-BOM DisplayName:x-UTF-16LE-BOM Aliases:UnicodeLittle Name:X-UTF-32BE-BOM DisplayName:X-UTF-32BE-BOM Aliases:UTF_32BE_BOM UTF-32BE-BOM Name:X-UTF-32LE-BOM DisplayName:X-UTF-32LE-BOM Aliases:UTF_32LE_BOM UTF-32LE-BOM Name:x-windows-50220 DisplayName:x-windows-50220 Aliases:cp50220 ms50220 Name:x-windows-50221 DisplayName:x-windows-50221 Aliases:cp50221 ms50221 Name:x-windows-874 DisplayName:x-windows-874 Aliases:ms-874 ms874 windows-874 Name:x-windows-949 DisplayName:x-windows-949 Aliases:windows949 ms949 windows-949 ms_949 Name:x-windows-950 DisplayName:x-windows-950 Aliases:ms950 windows-950 Name:x-windows-iso2022jp DisplayName:x-windows-iso2022jp Aliases:windows-iso2022jp
这些编码的实现类都是sun包下的:
有了Charset对象即可获取CharsetDecoder(解码器)和CharsetEncoder(编码器)。