斐波那契是数学中最值得讨论的一个问题,从12世纪斐波那契提出这个数列后,就有很多数学家研究过这个数列,对斐波那契数列的新发现也越来越多,这些细节我没能力去研究,这篇文章中要讲的是编程中对生成斐波那契数算法的优化。首先要说的就是斐波那契数列的定义,这一切都起源于一个生殖能力超强的兔子:
- 第一个月初有一对刚诞生的兔子
- 第二个月后(第三个月初)他们可以生育
- 每月没对兔子可生育的兔子会诞生下一对新兔子
- 兔子永不死去
几乎每个学计算机的在学编程语言的时候都会遇到这样的习题:计算第N个月兔子的总数
点击这里查看完整源代码,建议对着完整的代码调试。
最简单的递归算法
老师肯定会教的一种方法:
1
2
3
4
5
| uint64_t fibonacci(unsigned int n) {
if (n == 0) return 0;
if (n <= 2) return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
|
该方法来自于斐波那契数列的一个递推式:fib(n) = fib(n-1) + fib(n-2)
然后使用递归算法并指定递归出口,即可得出结果。
使用循环迭代消除递归
递归因为要不断地调用函数自身,调用函数就伴随着参数以及函数局部变量入栈,当递归层数较大容易产生栈溢出,所以通常需要我们使用循环优化递归算法。幸运地是,大多数递归都能修改成循环(使用自定义栈保存变量的方式仍然算递归)。而且上面的算法在效率上存在很大的优化空间:
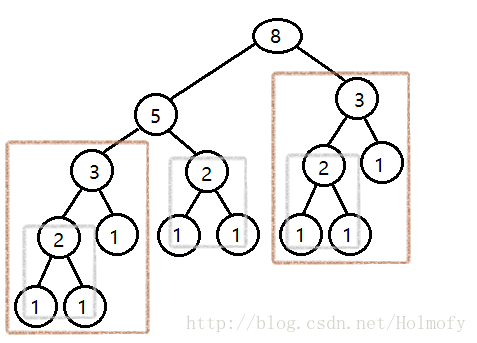
你会发现fib(5) = fib(4) + fib(3),而求fib(4)的时候我们已经求过fib(3),这意味着我们做了很多重复的工作,很明显我们需要把前面做过的工作暂存。
递归算法时间呈指数形式增长:O(2^N);而使用循环迭代时间上呈线性增长:O(N)。在我笔记本上测试时,当n超过40递归算法的时间就开始爆炸了。
1
2
3
4
5
6
7
8
9
10
11
| uint64_t fibonacci(unsigned int n) {
if (n == 0) return 0;
if (n == 1 || n == 2) return 1;
uint64_t f1 = 1, f2 = 1, fn;
for (unsigned int i = 3; i <= n; i++) {
fn = f1 + f2;
f1 = f2;
f2 = fn;
}
return fn;
}
|
矩阵算法求解
斐波那契数列的递推公式是:fib(n) = fib(n-1) + fib(n-2);我们可以用矩阵来表示这种关系:
进一步推到可以得到:
从0开始算得到Fn则需要更进一步:
我们要实现一下矩阵运算:
特别地:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| uint64_t fibonacci(unsigned int n) {
uint64_t m[2][2] = { 1,1,1,0 };
uint64_t result[][2] = { 1,0,0,1 };
uint64_t temp[2][2];
for (unsigned int i = 1; i <= n; i++) {
temp[0][0] = result[0][0] * m[0][0] + result[0][1] * m[1][0];
temp[0][1] = result[0][0] * m[0][1] + result[0][1] * m[1][1];
temp[1][0] = result[1][0] * m[0][0] + result[1][1] * m[1][0];
temp[1][1] = result[1][0] * m[0][1] + result[1][1] * m[1][1];
memcpy(result, temp, sizeof(uint64_t) * 4);
}
return result[1][0] * 1;
}
|
该算法在时间上也是按线性增长的:O(N),由于for循环内指令较多,所以可能会比循环迭代算法更耗时。但是该算法有很多可优化的地方,这里作为引子,方便下面算法的理解。
矩阵快速幂优化矩阵算法
在计算整数的乘法时,计算机底层是通过加法和移位运算实现的,举个例子:
1
| 十进制:4*13 => 二进制:100b*1101b = 100b*(1000b+100b+00b+1b) = (100b<<3)+(100b<<2)+0+(100b<<1)
|
快速幂:对于幂运算,我们也可以用类似的方式进行优化。
通常我们进行幂运算会直接循环累积,比如:4^13,会循环13次。
但是如果我们使用乘法的结合律就可以将时间复杂度降到O(log(N)):
1
2
3
4
| 4^13 = (4^8) + (4^4) + (4^1) ;
4^8 = 4^4 * 4^4;
4^4 = 4^2 * 4^2;
4^2 = 4*4;
|
快速幂实现如下:
1
2
3
4
5
6
7
8
9
10
| int quick_pow(int base, int exp) {
int result = 1;
while (exp) {
if (exp & 1)
result *= base;
exp >>= 1;
base *= base;
}
return result;
}
|
我们可以把快速幂的思想应用到矩阵运算上,从而对上面的矩阵算法进行优化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| uint64_t fibonacci(unsigned int n) {
uint64_t m[2][2] = { 1,1,1,0 };
uint64_t result[][2] = { 1,0,0,1 };
uint64_t temp[2][2];
while (n) {
if (n & 1) {
temp[0][0] = result[0][0] * m[0][0] + result[0][1] * m[1][0];
temp[0][1] = result[0][0] * m[0][1] + result[0][1] * m[1][1];
temp[1][0] = result[1][0] * m[0][0] + result[1][1] * m[1][0];
temp[1][1] = result[1][0] * m[0][1] + result[1][1] * m[1][1];
memcpy(result, temp, sizeof(uint64_t) * 4);
}
temp[0][0] = m[0][0] * m[0][0] + m[0][1] * m[1][0];
temp[0][1] = m[0][0] * m[0][1] + m[0][1] * m[1][1];
temp[1][0] = m[1][0] * m[0][0] + m[1][1] * m[1][0];
temp[1][1] = m[1][0] * m[0][1] + m[1][1] * m[1][1];
memcpy(m, temp, sizeof(uint64_t) * 4);
n >>= 1;
}
return result[1][0] * 1;
}
|
使用常量表优化幂矩阵运算
为了减少计算2、4、8…次幂矩阵所消耗的时间,我们可以提前把这些矩阵幂求出来并存在常量表中,这样可以减少乘法运算的次数。
先写个程序自动生成常量表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| void power_matrix(uint64_t m[][2], unsigned int exp) {
uint64_t result[][2] = { 1,0,0,1 };
uint64_t temp[2][2];
for (unsigned int i = 1; i <= exp; i++) {
temp[0][0] = result[0][0] * m[0][0] + result[0][1] * m[1][0];
temp[0][1] = result[0][0] * m[0][1] + result[0][1] * m[1][1];
temp[1][0] = result[1][0] * m[0][0] + result[1][1] * m[1][0];
temp[1][1] = result[1][0] * m[0][1] + result[1][1] * m[1][1];
memcpy(result, temp, sizeof(uint64_t) * 4);
}
memcpy(m, result, sizeof(uint64_t) * 4);
}
void generate_matrix() {
uint64_t m[2][2] = { 1,1,1,0 };
uint64_t temp[2][2];
for (int i = 0; i < 8; i++) {
memcpy(temp, m, 4 * sizeof(uint64_t));
printf("{");
power_matrix(temp, 1 << i);
for (int j = 0; j < 2; j++) {
for (int k = 0; k < 2; k++) {
printf("%llu, ", temp[j][k]);
}
}
printf("},\n");
}
}
|
调用generate_matrix函数生成0~7次矩阵。
把生成的常量表复制粘贴到代码中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| uint64_t fibonacci6(unsigned int n) {
const static uint64_t cache[][2][2] = {
{ 1, 0, 0, 1 },
{ 1, 1, 1, 0 },
{ 2, 1, 1, 1 },
{ 5, 3, 3, 2 },
{ 34, 21 ,21, 13 },
{ 1597, 987, 987 ,610 },
{ 3524578, 2178309, 2178309, 1346269 },
{ 17167680177565, 10610209857723, 10610209857723, 6557470319842},
{ 8102862946581596898, 18154666814248790725, 18154666814248790725, 8394940206042357789}
};
uint64_t result[][2] = { 1,0,0,1 };
uint64_t temp[2][2];
int bit_pos = 1;
while (n) {
if (n & 1) {
temp[0][0] = result[0][0] * cache[bit_pos][0][0] + result[0][1] * cache[bit_pos][1][0];
temp[0][1] = result[0][0] * cache[bit_pos][0][1] + result[0][1] * cache[bit_pos][1][1];
temp[1][0] = result[1][0] * cache[bit_pos][0][0] + result[1][1] * cache[bit_pos][1][0];
temp[1][1] = result[1][0] * cache[bit_pos][0][1] + result[1][1] * cache[bit_pos][1][1];
memcpy(result, temp, sizeof(uint64_t) * 4);
}
n >>= 1;
bit_pos++;
}
return result[1][0] * 1;
}
|
这种方法的缺点是所能求的斐波那契最大项决定于表的大小,上面代码实现中所能求的最大项是255(八位全1的情况),不过斐波那契数列的第94项就已经超过64位无符号整形了。
(第93项斐波那契数为1220 0160 4151 2187 6738,而64位无符号整形最大值为2^64-1=1844 6744 0737 0955 1615,第94项为1974 0274 2198 6822 3167溢出就成了129 3530 1461 5867 1551)
如果想要求更大的斐波那契数,则需要自己实现一个类似于Java中的BigInteger类(C++应该会有很多类似的开源库)
通项式直接求解
求斐波那契数列通项有很多种方法,这里用最容易理解的方法进行求解:初等代数进行数列代换。
这种方法只要有高中数学水平就可以解出来(当时高中解出来的时候,还以为是什么天大的发现^_^)。
①、构造等比数列
可得到系数关系:
$$
\left{
\right.
\left{
\right.
或
\left{
\right.
$$
因为,所以{}是公比为β的等比数列,首项为
求等比数列通项:
②、再次构造等比数列
上一步得到,等式两边同时除以,得到:
不妨设,则有:
继续构造:
有等式:
求得等比通项:
即:
得到:
对上一步的解进行分类讨论:
综上所述:
有了公式,代码就简单了。
1
2
3
4
5
6
7
8
9
|
uint64_t fibonacci6(unsigned int n) {
const double sqrt5 = 2.2360679774997896964091736687313;
const double a = (sqrt5 + 1) / 2;
const double b = (1 - sqrt5) / 2;
const double sqrt1_5 = 1 / sqrt5;
return (uint64_t)((pow(a, n) - pow(b, n))*sqrt1_5);
}
|
该方法依赖于pow函数的复杂度,由于是浮点数的幂运算,所以不能像之前那样优化运算。
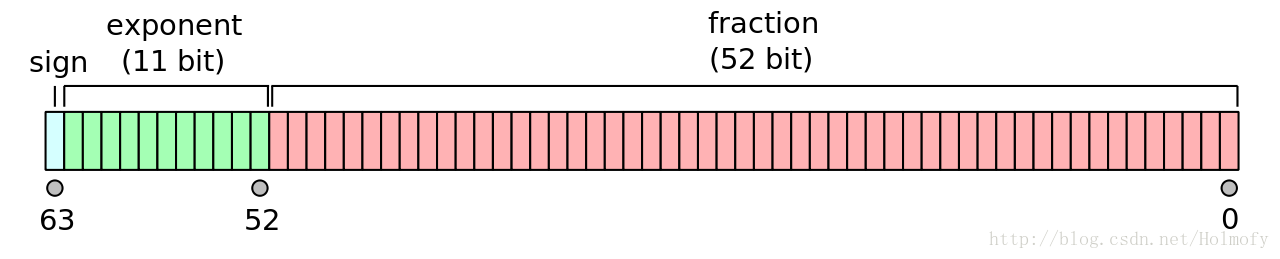
因为double位64位双精度浮点数,只有52位保证数据精度,所以斐波那契数列项数越大,精度越低,同样的这种方式也会发生溢出。有一个解决方案是使用类似于Java中的BigDecimal的类来代替double。
各实现方法比较测试
第一种递归算法就不拉进来测试了,笔记本要炸( ╯□╰ ):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
double duration(struct timespec *end, struct timespec *start) {
double d_sec = difftime(end->tv_sec, start->tv_sec);
long d_nsec = end->tv_nsec - start->tv_nsec;
return (d_sec*10e9 + d_nsec);
}
void compare_and_test() {
typedef uint64_t(*PFUNC)(unsigned int n);
PFUNC pFuncs[] = { fibonacci2 ,fibonacci3, fibonacci4, fibonacci5, fibonacci6 };
struct timespec start, end;
for (int j = 0; j < sizeof(pFuncs) / sizeof(PFUNC); j++) {
timespec_get(&start, TIME_UTC);
for (int i = 0; i < 95; i++) {
# ifdef NDEBUG
(*pFuncs[j])(i);
# else
printf("%llu ", (*pFuncs[j])(i));
# endif
}
timespec_get(&end, TIME_UTC);
printf("\t duration: %lf nanosecond\n", duration(&end, &start));
}
}
|
运行结果(单位纳秒):
1
2
3
4
5
| duration: 165800.000000 nanosecond
duration: 1653500.000000 nanosecond
duration: 147000.000000 nanosecond
duration: 76000.000000 nanosecond
duration: 134700.000000 nanosecond
|
项数越大,矩阵快速幂算法的优势越明显。
参考链接:
维基百科:https://en.wikipedia.org/wiki/Fibonacci_number

